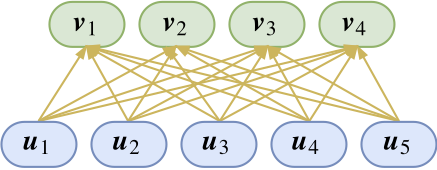
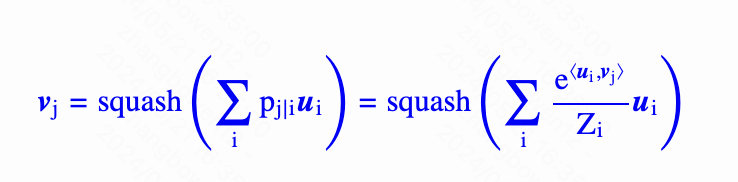多兴趣召回 Posted on 2024-05-22 Edited on 2024-05-26 In machine_learning 胶囊网络 创新点:“vector in vector out”代替“scalar in scalar out”? NLP很多任务其实做过类似的事情。 提出了一种新的“vector in vector out”方案,并且带有一定的可解释性 胶囊等同于向量。作者的说法是表达更多更丰富的信息。NLP中one-hot词表和embedding做类比? 对于下一层的某一个点的向量计算方式是这样的 Read more »
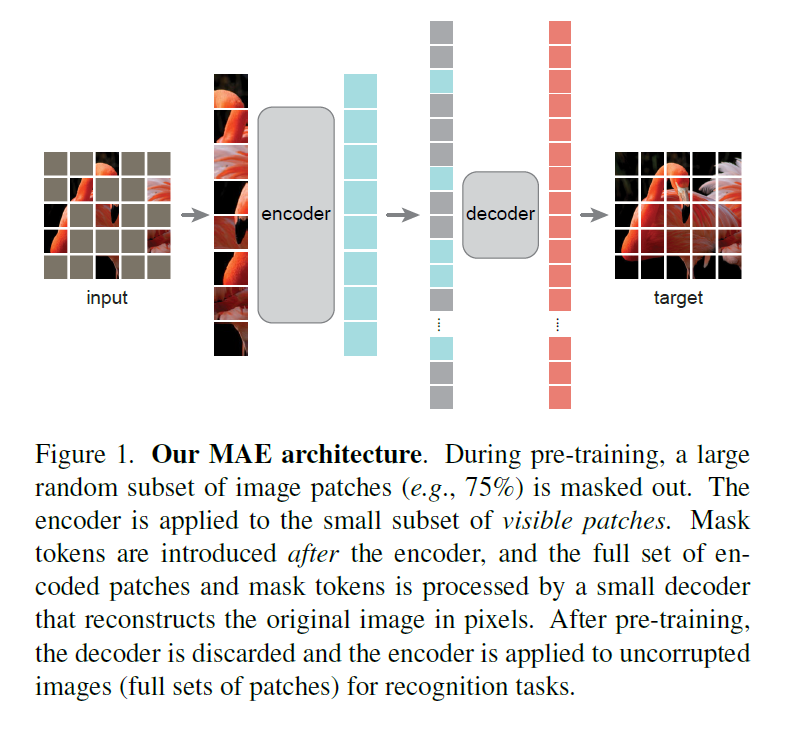
MAE: masked autoencoders are scalable vision learners Posted on 2024-01-28 Edited on 2024-03-25 In machine_learning 总结 相当于BERT的CV版本,题目中的autoencoder相当于是自编码器的意思,代表训练数据和目标来自于这个训练数据本身 设计训练任务的时候遮住的区域要足够的大,这样才能去学一些语义上的东西(否则做一下差值就算出来了),这样做同时也会减轻计算量 用小训练数据可以取得比较好的自监督学习成果,也和BERT一样在很多下游任务上也有很好的效果 作者对自监督掩码在CV和NLP领域不同的应用进展做了如下讨论 以往的卷积操作不好应用mask 图片里的像素信息比较冗余 还原的目标图像相比较于文本内容语义更加的基础 模型 切块,掩盖住其中大概3/4的内容,对其余内容进行编码,然后在加上掩盖住的位置信息和一个统一的可学习的向量,一起放到decoder里面进行图片重建 encoder比decoder略大一些,计算量相对来说要大。这个decoder的运算量相当于encoder的1/10 解码器的最后一层是线性层维度等于patch的维度(16 * 16) 损失函数是MSE Read more »
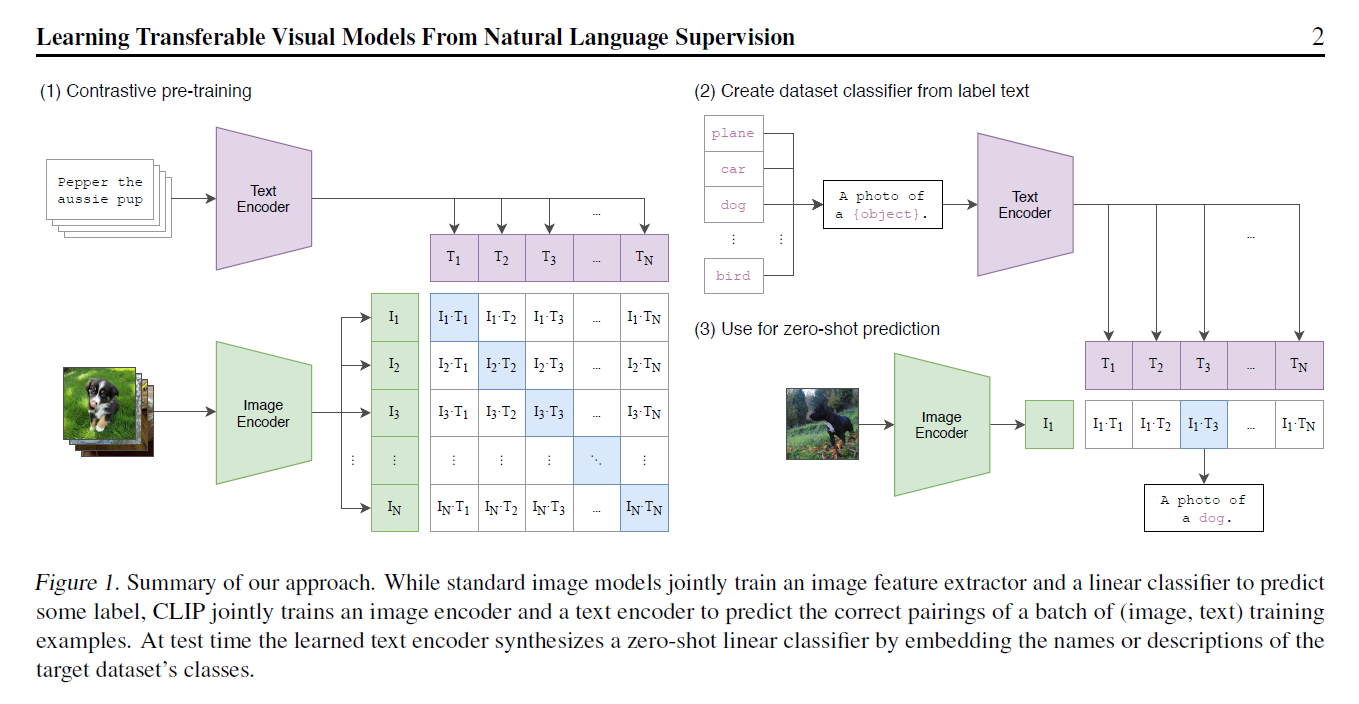
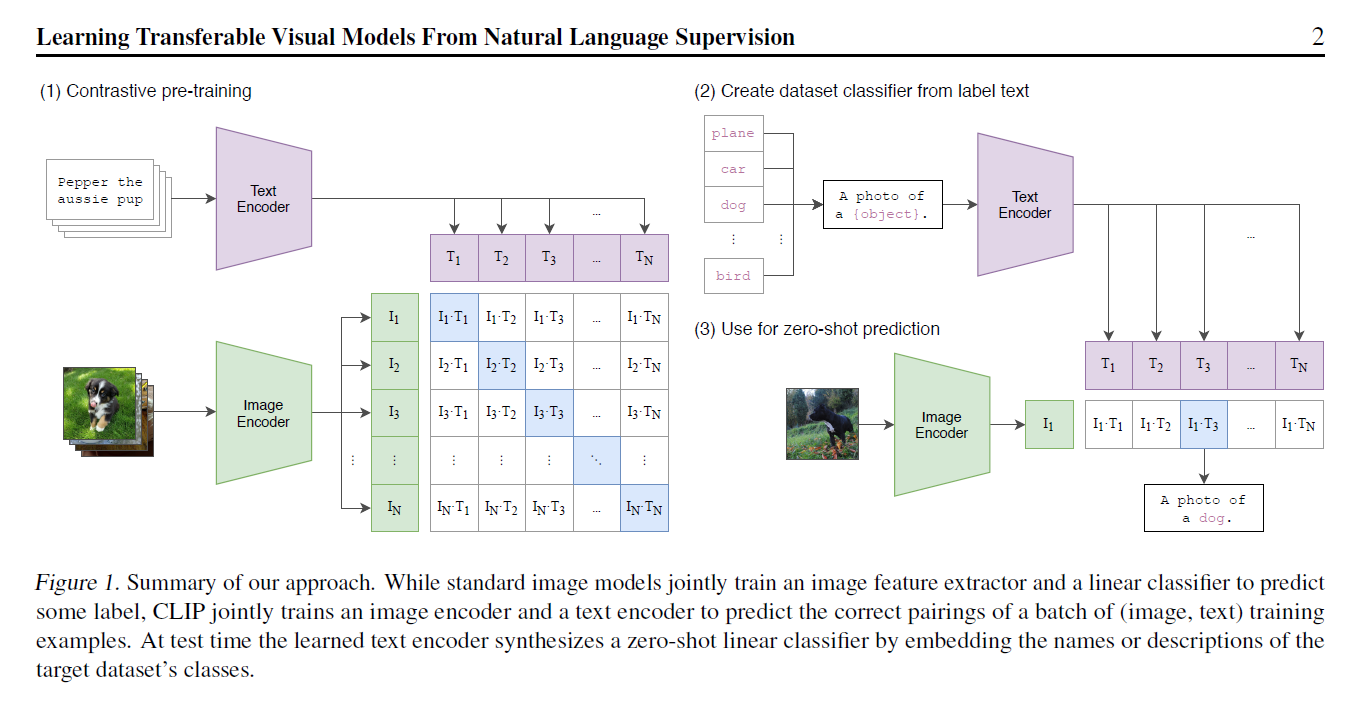
CLIP Learning transferable visual models from natural language supervision Posted on 2024-01-24 Edited on 2024-03-24 In machine_learning 总结 提出CLIP, for Contrastive Language-Image Pre-training 在imagenet上,无监督训练打平Res50,堪比alexnet 训练流程如下,使用已有图片、文本对的数据集进行pairwise训练。4亿条清洗过的数据 这种方式训练是没有分类头的无法直接落地应用。作者引入prompt template机制,也是pair wise的去做分类。用句子效果比用直接裸的单词效果更好,因为训练的时候看到的都是划分好的句子么。这个template也是有一些讲究的,所以后面还提到了prompt engineering和prompt ensemble 这种方式可以很好的拓展,不局限于训练中所使用的的类别,摆脱了categorical label的限制 迁移效果非常好,在OpenAI官网上列举了各个不同数据集的效果。但是这块有点存疑的是数据量级的差别4亿对100万 Read more »
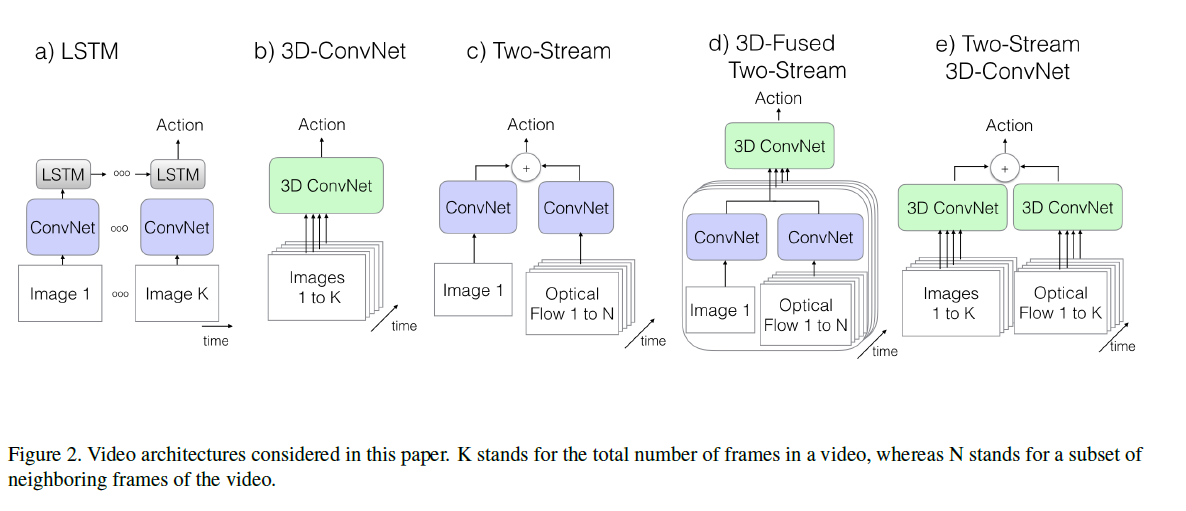
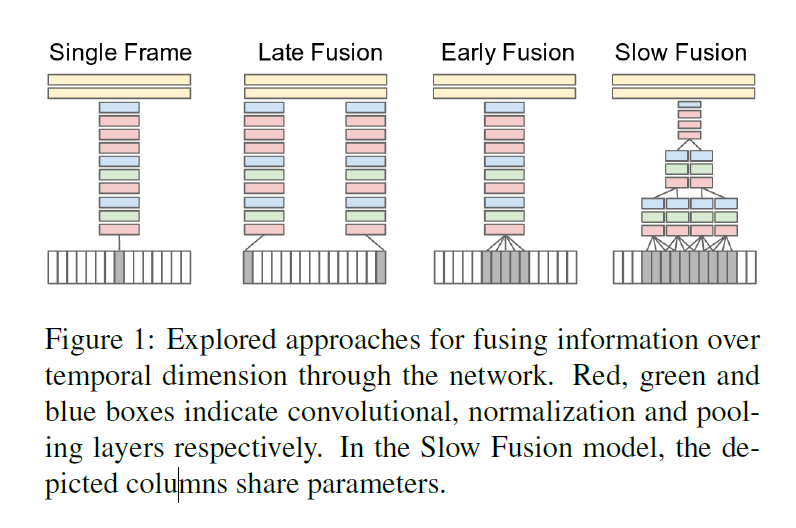
视频理解综述 Posted on 2024-01-02 Edited on 2024-03-24 In machine_learning 朴素时空融合方案Deep Video 使用大规模数据集通过CNN进行训练,划分了融合框架 Late只是在最后输出层进行了结合 Early是在channel维度就把输入揉在一起了 Slow是前两者方式的结合 实验效果来看差别不大,比不过手工特征 提出了sports 1M 数据集 尝试了多分辨率网络,在图片里面比较好用的方式,可以算是一种早期的先验注意力机制,最终效果也是不如手工特征 Read more »
I3D Two-Stream Inflated 3D ConvNet Posted on 2023-12-18 Edited on 2024-03-18 In machine_learning 总结 提出了一个新模型I3D和一个新的数据集Kinetics,这个数据集基本是动作识别必做的一个数据集。 做这个数据集主要是因为主流的数据集太小了,区分度小。并且这个数据集每个视频都来自于一个独立的视频片段,标注的非常好。 所谓I3D是指inflated 3D,特点是把已经设计好的2D网络扩展成3D的形式然后应用在视频上面。本文的模型还加上了光流 对比传统方式 CNN + LSTM:后验效果不好,这个方向基本没有后续了 3DCNN:参数量过于巨大且数据量小,无法做很深的建模,比如c3d 双流:这个东西作者认为有用,在本文也拿过来用了 启用inflated操作后可以直接利用效果好的2D网络作为初始化模型,本文使用的inceptionV1,(不用resnet是因为在视频领域后验效果不如,但是后面的non local是用resnet来做的,所以后面再说I3D就是指resnet版本的) 模型 Read more »
Two-Stream Convolutional Networks Posted on 2023-12-10 Edited on 2024-03-17 In machine_learning 总结 双流是第一次在视频领域应用深度学习方法取得了不错结果的工作 使用两个神经网络去做动作识别——空间流、时间流 作者认为CNN比较擅长学习局部特征,所以把全局的信息处理为先验信息(动作光流)给到神经网络一同去做判定 最终的判定结果是两个网络判定结果的加权平均 作者还提出了一种观点,视频天然适合数据增强 一个比较有启发的想法:当你发现有些东西神经网络不太好学的时候,我们就给他提供成为先验信息帮助他学 模型 Read more »
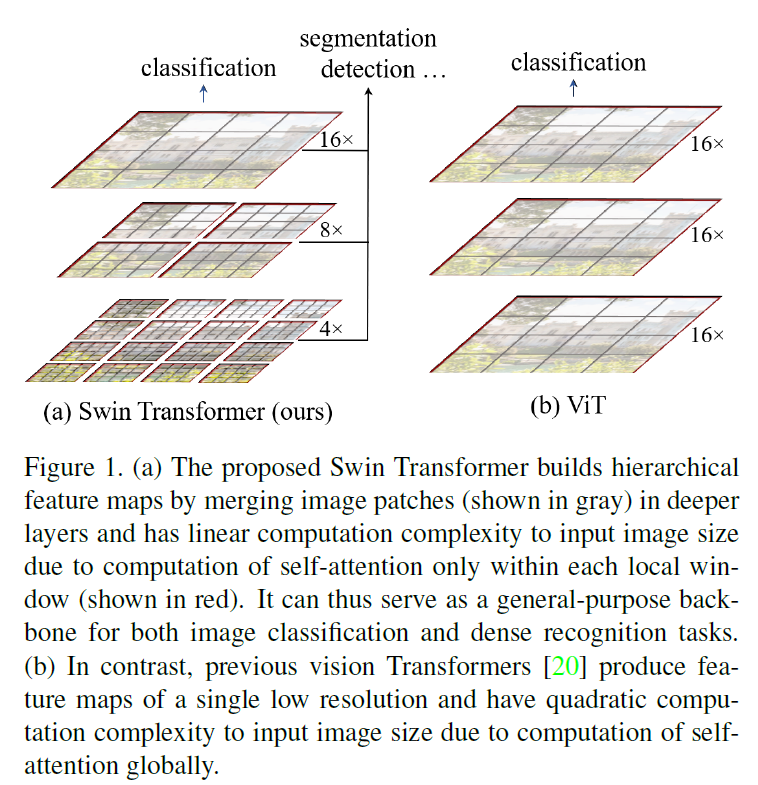
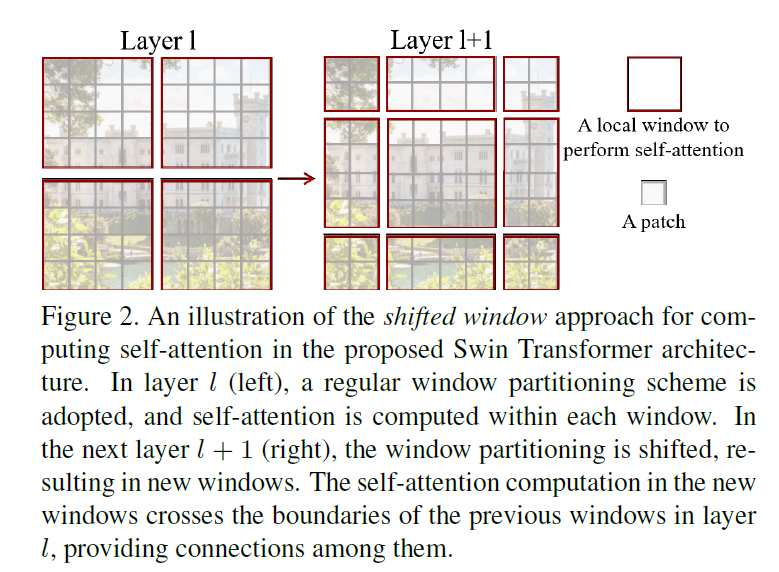
Swin Transformer Posted on 2023-12-04 Edited on 2024-03-15 In machine_learning 总结 相对于ViT只能应用于分类,Swin Transformer可以在更多的下游任务上应用,但是直接用会有点问题 尺度上的问题 原始数据分辨率过大 本文引入滑动窗口机制解决上述问题。 计算复杂度降低 相邻窗口之间的数据可以交互 有分层、多尺度的特征 相对于卷积的池化操作,Swin Transformer使用的操作是Patch Merging 另外就是shift window机制,让不同window里的patch信息可以相互交互,让局部注意力变为全局注意力 Read more »
Vision Transformer Posted on 2023-12-03 Edited on 2024-03-13 In machine_learning ViT的特性 在以下CNN做的不太好的场景ViT的表现会好一些: 遮挡 数据分布发生偏移 加对抗性的patch 重排列 总结 Read more »
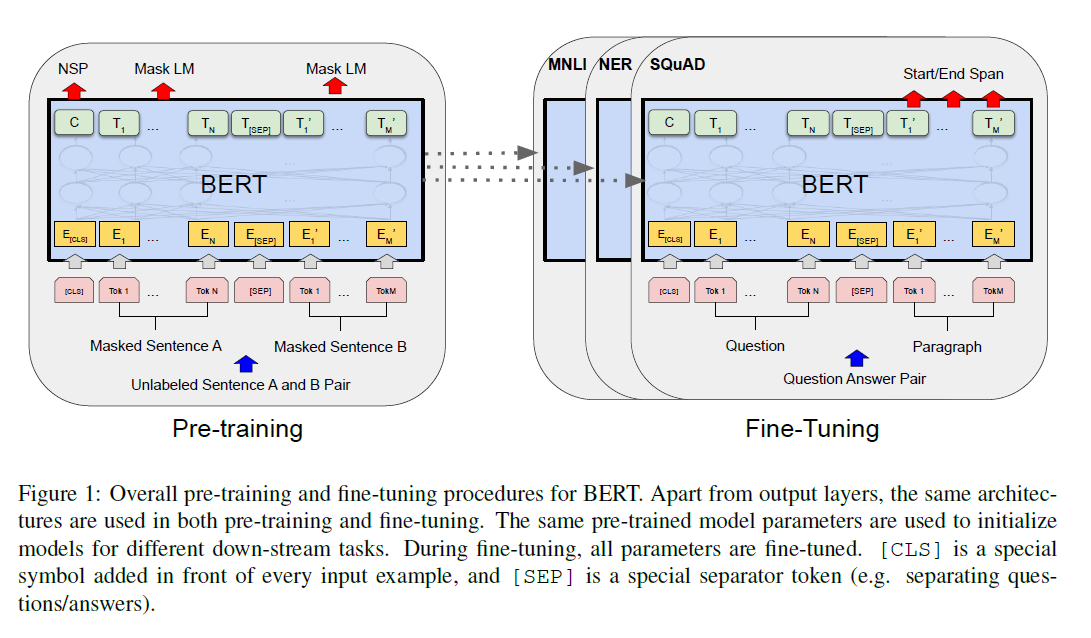
BERT Posted on 2023-09-12 Edited on 2024-03-12 In machine_learning 总结 名字有点说法,Bidirectional Encoder Representations from Transformers,简称BERT和之前所引用的ELMo都是芝麻街主人公的名字…… 和前作对比: 相比较于ELMo的RNN架构,BERT迁移到下游任务相对简单。ELMo这种方式属于基于特征的下游任务应用方式,将预训练好的模型输出当做额外的特征应用到下游任务中去 相比较于GPT,BERT是双向信息建模。GPT的应用下游任务方式属于微调,在不同的任务上重新训练已有的模型。 训练目标 单向信息建模在语义表征任务上其实有一定局限性所以作者想要加入双向信息去做建模,使用了MLM目标去建模,这个东西是一个叫做Cloze的1953年的文章提出来的 还使用了预测下一个句子的任务。因为有些任务比如问答都是要处理两个句子的 在挺多(11个)的任务上表现良好,这里其实证明了两个事情 双向信息很有用 大量的没有label的数据比少量labeled的数据效果更好,这个思想也应用在了视觉领域 模型 模型训练分为两个步骤:预训练(无监督)和微调(下游有监督数据) Read more »
多模态串讲 Posted on 2023-09-06 Edited on 2024-03-01 In machine_learning 之前工作回顾ViLT 把目标检测从视觉端拿掉,因为预训练的效果不好 将目标检测器换为patch embedding,大大降低运算复杂度,改成了目前这种轻Encoder重模态融合的形式(先tokenized然后传给transformer) VILT的缺点 性能不如C类方法(VilBert),经验来看视觉模型要比文本模型要大。另外一个原因是图片模态的初始化比较随机 推理快但是训练很慢(使用WPA Loss) ALBEF就是解决上面的问题 Read more »
大模型科研思路 Posted on 2023-09-04 Edited on 2024-02-19 In machine_learning 总结 Facebook的Meta.ai 开源了大模型LLaMA,是一组模型分别有7,13,33,65B参数,和GPT3的165B、Google的PaLM的540B参数比算是小模型。Bigger Than Bigger,Google的ViT也推出了22B的版本 四个方向 Efficiency,在大模型中追求效率(PEFT,parameter efficient fine tuning) 直接引用已有模型,在这个基础上做研究 plug and play 即插即用模块,比如数据增强方式 数据集、分析、综述文章 效率方向AIM Adaptive Image Models,视频理解的工作 以往的工作大体分类两类,时空在一起处理和分开处理。分开处理的比方说光流,time transformer。在一起的比如说各种3D卷积。在一起的模型训练成本非常高,不过总体他们都有预训练模型所以还好。 我们能不能在做时空分开训练的模型的时候将空间部分冻结? Clip已经验证zero shot的效果,即不去finetune模型直接在下游任务去应用,效果也非常好。 模型的泛化性在逐步的增强 可以避免灾难性遗忘的问题(在数据量比较小的情况下去finetune大模型) 冻住大模型微调周边的方式有两种一种是Adapter另一种是prompt tuning Read more »
Training language models to follow instructions with human feedback Posted on 2023-08-23 Edited on 2024-02-18 In machine_learning 总结 这个文章提出instructGPT模型,instructGPT是ChatGPT的前身,OpenAI的所有工作基本都有连续性 instructGPT官方博客的四个例子 改代码 问合法建议(有危险的问题不会回答) 跨学科回答问题,密码学和文学结合,对上下文的理解很好(8000词左右) 可以理解自己的局限性 数据格式是多轮对话 过往大模型可能存在的问题: 不真实 有政治、法律风险 没有价值(一本正经的胡说) 总的来说就是没有和人的观念对齐,对于大公司来说是不可接受的 为了解决上面说的问题引入人工标注,总体流程分为三块: 人工做了问答数据集,以GPT3为基础fintue了一个模型(SFT,有监督模型) 人工对问答模型的多个结果(beam search)进行排序,训练了一个打分模型(RM reward model 奖励模型)。因为排序比生成简单 使用打分模型和强化学习的方式finetune问答模型 结果instructGPT 1.3B的参数好过175B的GPT3,这个也还好毕竟使用了标注数据集信噪比高 instructGPT虽然在各个任务上表现很好,但是对于细分领域还是不如专业模型 方法 从19和20年的两篇文章来的方法 需要对标注的人员进行测试 SFT模型训练 训练了16个epoch,虽然1个epoch就过拟合了,但是发现虽然过拟合也会对后面RM打分和人工打分有帮助 RM训练 去掉softmax预测词的部分,改为线性层映射为一个分数 用6B参数版本,不用175B因为训练会飞掉 pairwise训练,从top9里面取两个配对,共计36个样本对。感觉给9个答案排序,标注的人也很辛苦 学习的方式是PPO,在强化学习中模型被称为policy,策略 在初始阶段RM模型的参数和SFT是一致的,分批取数据训练,因为训练完成后模型给的值会发生变化,所以采用这种方式称为在线学习 在学习目标中加入了KL散度约束RM模型和SFT模型不要离得太远(训练跑偏) 在学习目标中又把训练GPT3的目标拿了过来,相当于不要遗忘
Attention Is All You Need Posted on 2023-08-22 Edited on 2024-02-17 In machine_learning 总结 作者都来自Google,均等贡献,比较少见 在seq2seq问题中,没有用循环和卷积的架构,而只依赖注意力机制,在一些机器翻译的工作中取得了很好的结果(后来这个工作出圈了,在包括CV在内的所有任务都可以用)。训练也不太费事,在8个GPU上训练了3.5天。 在结论部分有源码(应该放在摘要部分?) 虽然文章标题强调了Attention,但是在后面的消融实验中验证其实其他部分也是很重要的,有个文章叫做Attention is not all you need专门讨论这个事情,也是Google的 在CNN和RNN之外提出了一个新的模型架构,并且几乎可以用这个架构处理所有模态的事情,堪称深度学习界的秦始皇 概述&背景 现有方式的缺点 传统RNN的缺点是只能把输入从左往右挨个遍历,通过隐藏状态去传递信息,难以并行(虽然做了一些改进但是没有根本解决这个问题) 卷积方式对于离的比较远的像素的相关性处理的不好(需要多层卷积);但是也提到了卷积好的一面:可以做多个输出通道,所以也就引出了多头注意力机制 自注意力机制之前已经有人提出,并不是创新 模型 Read more »
Learning transferable visual models from natural language supervision Posted on 2023-07-22 Edited on 2023-07-24 In machine_learning 总结 提出CLIP, for Contrastive Language-Image Pre-training 在imagenet上,无监督训练打平Res50,堪比alexnet 训练流程如下,使用已有图片、文本对的数据集进行pairwise训练。4亿条清洗过的数据 这种方式训练是没有分类头的无法直接落地应用。作者引入prompt template机制,也是pair wise的去做分类。用句子效果比用直接裸的单词效果更好,因为训练的时候看到的都是划分好的句子么。这个template也是有一些讲究的,所以后面还提到了prompt engineering和prompt ensemble 这种方式可以很好的拓展,不局限于训练中所使用的的类别,拜托了categorical label的限制 迁移效果非常好,在OpenAI官网上列举了各个不同数据集的效果。但是这块有点存疑的是数据量级的差别4亿对100万 Read more »
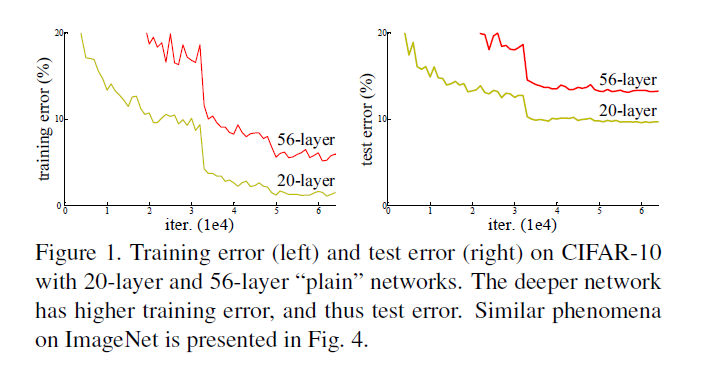
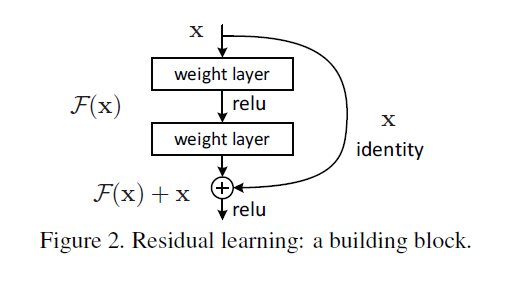
Deep Residual Learning for Image Recognition Posted on 2023-07-17 Edited on 2023-07-24 In machine_learning 结论 现状:深的神经网络很难训练,本文提出了一种残差结构可以构建152层深的网络 训练的“退化”现象:层数变深了,误差反而更高 解决方案:加shortcut,优势是没有引入额外的参数 Read more »