0%
总结
- 相对于ViT只能应用于分类,Swin Transformer可以在更多的下游任务上应用,但是直接用会有点问题
- 本文引入滑动窗口机制解决上述问题。
- 计算复杂度降低
- 相邻窗口之间的数据可以交互
- 有分层、多尺度的特征
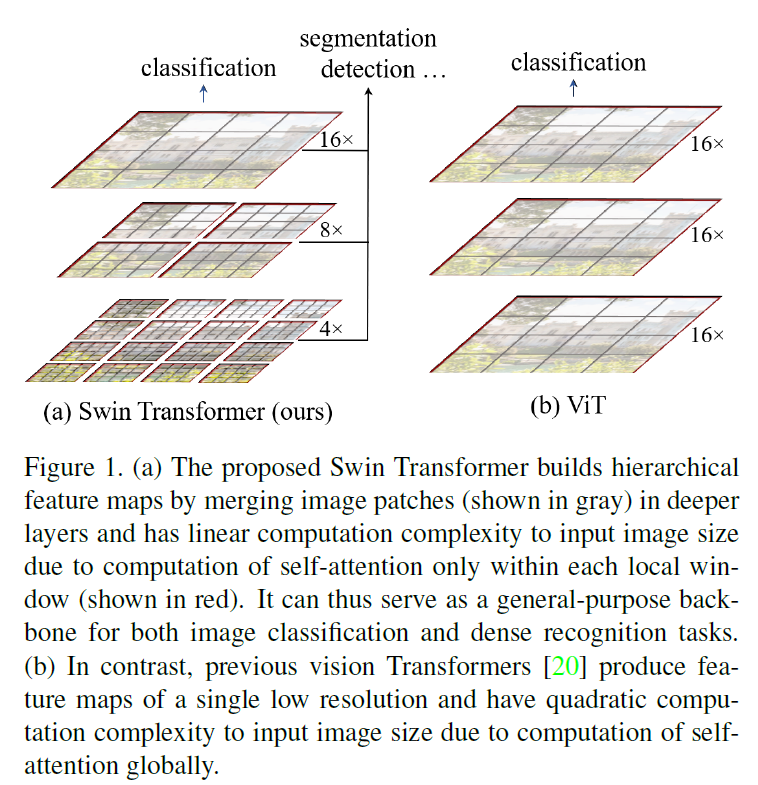
- 相对于卷积的池化操作,Swin Transformer使用的操作是Patch Merging
- 另外就是shift window机制,让不同window里的patch信息可以相互交互,让局部注意力变为全局注意力
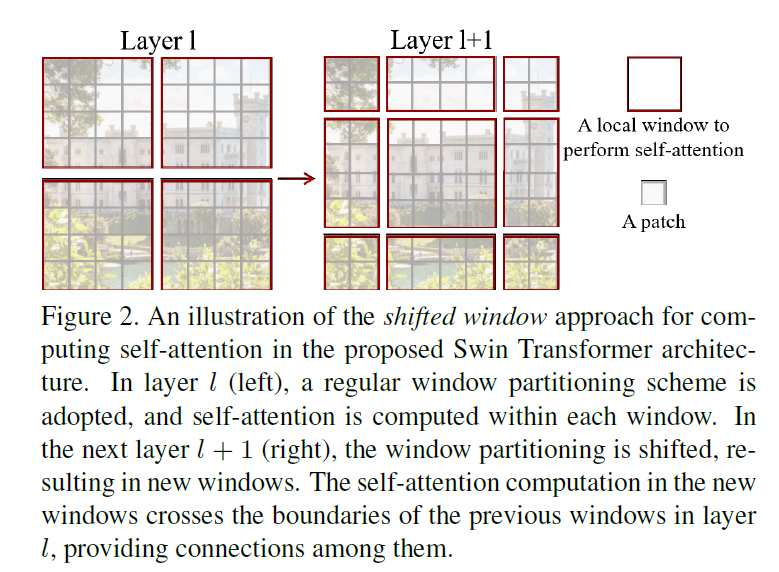
- 但也是因为引入了shift window,导致这个东西没法应用到NLP领域,没法做模型的大一统
模型
整体前向过程
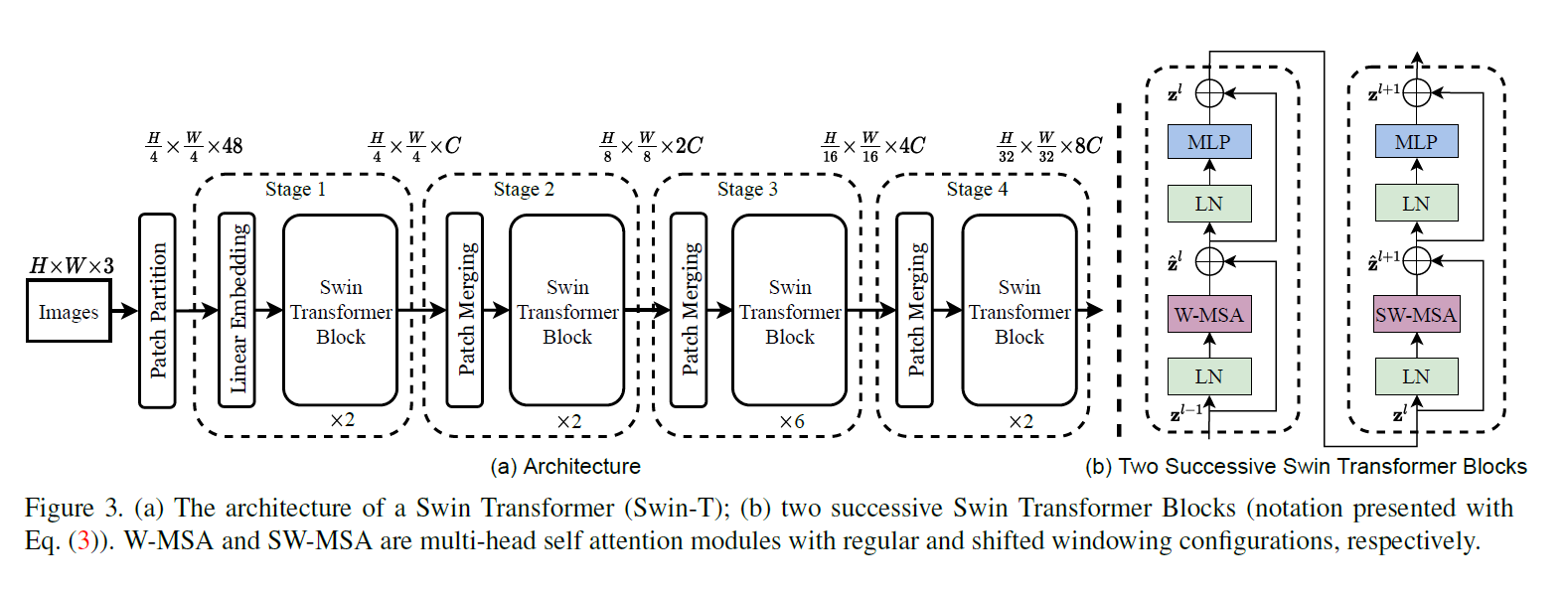
- 以224 224 3的图片为例,先打patch,patch size是4 4,整体维度变为56 56 * 48
- 通过Linear Embedding层(卷积)Channel维度变化为96,整体变为56 56 96
- 前面两维拉直变为3136 * 96,前面代表序列长度,后面代表token的长度
- 可以注意到3136的长度对于Transformer来说太长了,所以引入基于窗口的自注意力计算
- 每个窗口的尺寸是7 * 7,所以序列长度就变为了49
- 过Swin Transformer Block,维度不变还是56 56 96
- 之后是第一次patch merging各一个点取一个值,然后在channel维度叠起来,这样长宽会减半,channel会翻四倍,然后过1 1卷积把channel减半,最终变为28 28 * 192
- 不断重复这一套操作直到拿到结果,然后用average pooling变为768维度的向量
窗口机制

- 引入滑动窗口构建全局信息,每次移动窗口长度的一半使信息有重叠。所以每次都是过偶数遍transformer,第一次window transformer,第二次是shifted window transformer
- 直接移动窗口会带来计算效率问题,还要做特殊处理,以加快网络的效率
窗口掩码
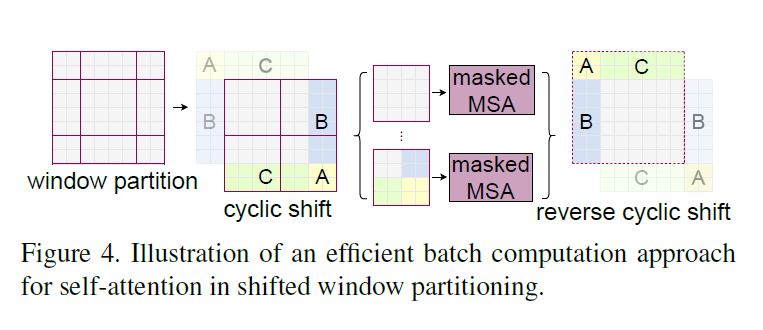
- 这个移动先把上面的碎块移到下面,再把左边的移到右边,凑成四个大块
- 但是凑出来的不应该用自注意力机制,所以再添加掩码保证语义的正确
- 掩码是加法实现,把不想要的部分的数字加上一个很小的负数
- 计算完成之后再把图片还原