0%
总结
- Facebook的Meta.ai 开源了大模型LLaMA,是一组模型分别有7,13,33,65B参数,和GPT3的165B、Google的PaLM的540B参数比算是小模型。Bigger Than Bigger,Google的ViT也推出了22B的版本
- 四个方向
- Efficiency,在大模型中追求效率(PEFT,parameter efficient fine tuning)
- 直接引用已有模型,在这个基础上做研究
- plug and play 即插即用模块,比如数据增强方式
- 数据集、分析、综述文章
效率方向
AIM
- Adaptive Image Models,视频理解的工作
- 以往的工作大体分类两类,时空在一起处理和分开处理。分开处理的比方说光流,time transformer。在一起的比如说各种3D卷积。在一起的模型训练成本非常高,不过总体他们都有预训练模型所以还好。
- 我们能不能在做时空分开训练的模型的时候将空间部分冻结?
- Clip已经验证zero shot的效果,即不去finetune模型直接在下游任务去应用,效果也非常好。
- 模型的泛化性在逐步的增强
- 可以避免灾难性遗忘的问题(在数据量比较小的情况下去finetune大模型)
- 冻住大模型微调周边的方式有两种一种是Adapter另一种是prompt tuning
Adapter
- 最早出自parameter efficient transfer learning for NLP,结构如下图:
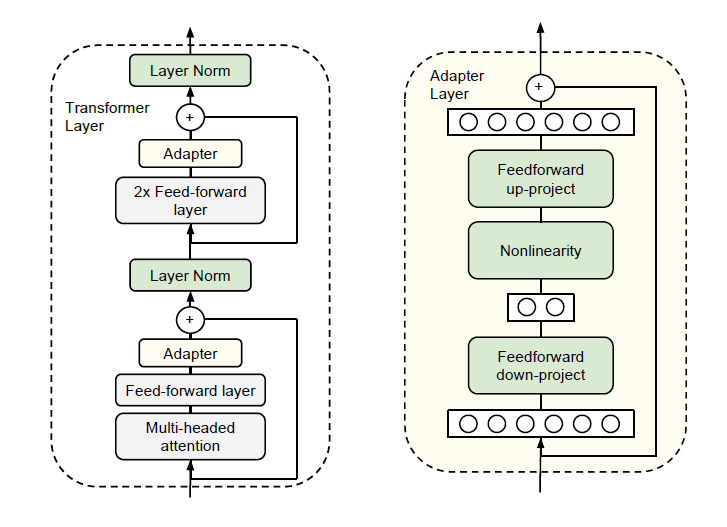
- 先过降采样层,然后过非线性层,然后过上采样层。然后有残差链接链接到最后。这个和SENet很接近
Prompt tuning
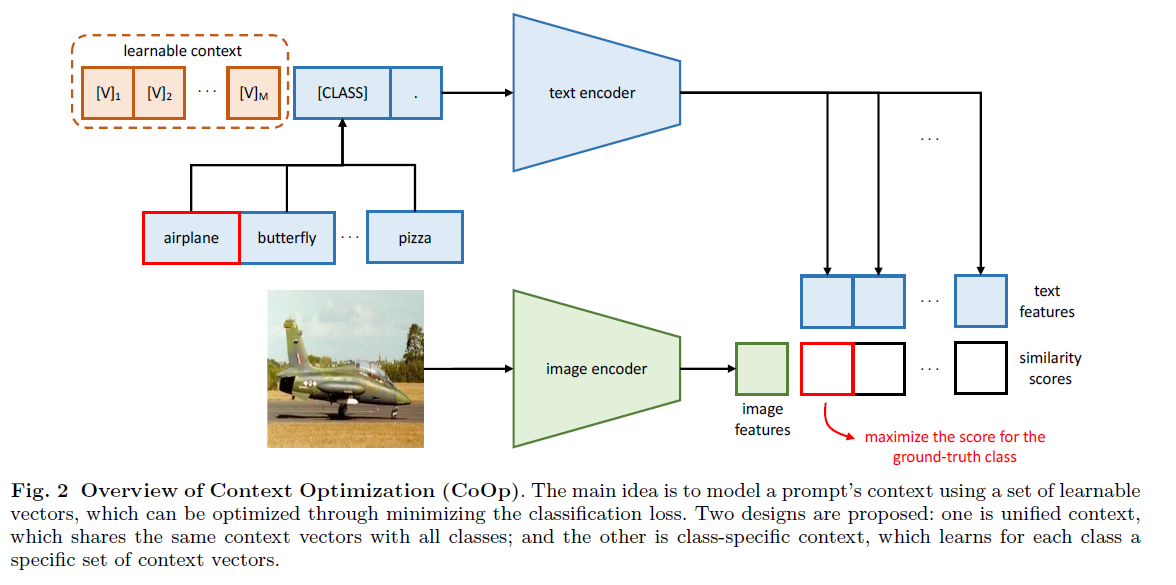
- 以CoOP(Learning to Prompt for Vision-Language Models)举例,假设用一个已经训练好的多模态模型来做图片分类,可以把图片和prompt给他,这个prompt怎么设置就很有学问,对效果影响非常大

- CoOP的想法就是把需要先验只是的hard prompt变为soft prompt,去学一个向量拼在图片前面,整体的框架是基本和Clip是一样的只是模型部分锁住不动,只去更新那个learnable context
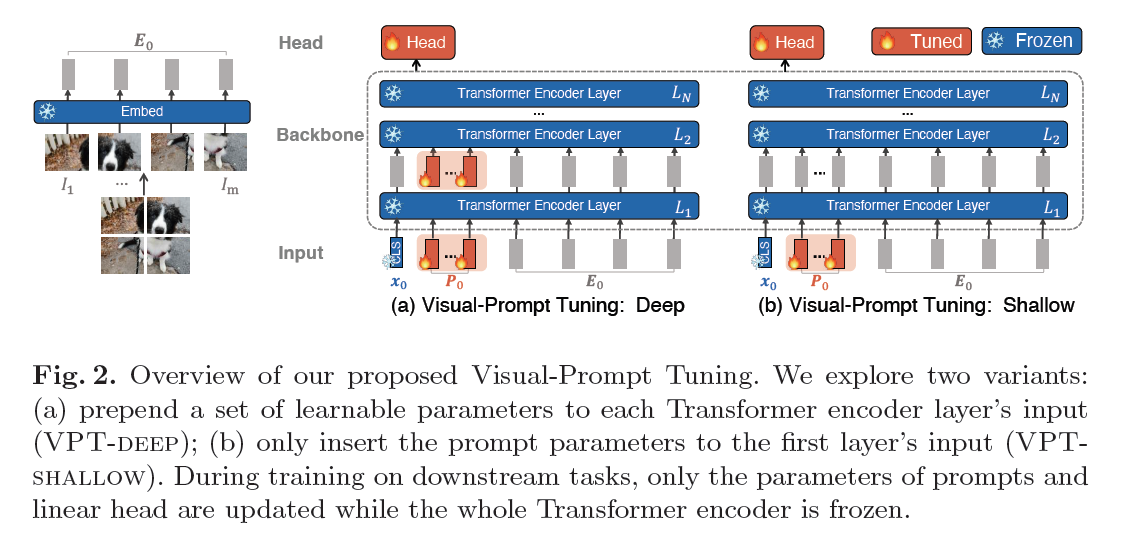
- 后面又有一篇Visual Prompt Tuning,把prompt应用在纯视觉领域上。分为shallow和deep两种方式
- shallow就是前图片的patch前面加可学习的prompt
- deep就是在每层都加
AIM的方法
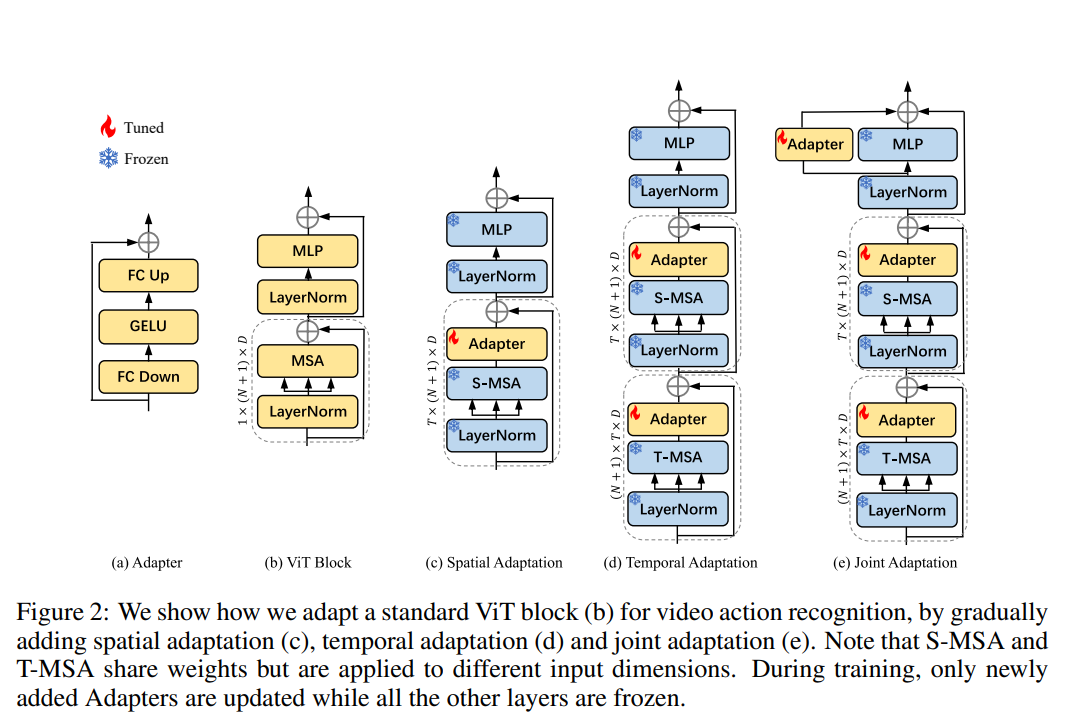
- 尝试在ViT的不同部分加Adapter查看效果
- C项是直接在空间域加Adapter,锁住其他
- D项在时间和空间分别去做attention,串行,两个attention共享权重,通过reshape的操作和Adapter机制在时域和频域切换。这种结构相比于C项有巨大提升,基本上可以打平fullfinetune的模型
- E项是Joint Modeling的思路,在最后一层做一层spatial temporal
- 消融实验结果,这个表列的非常清晰:
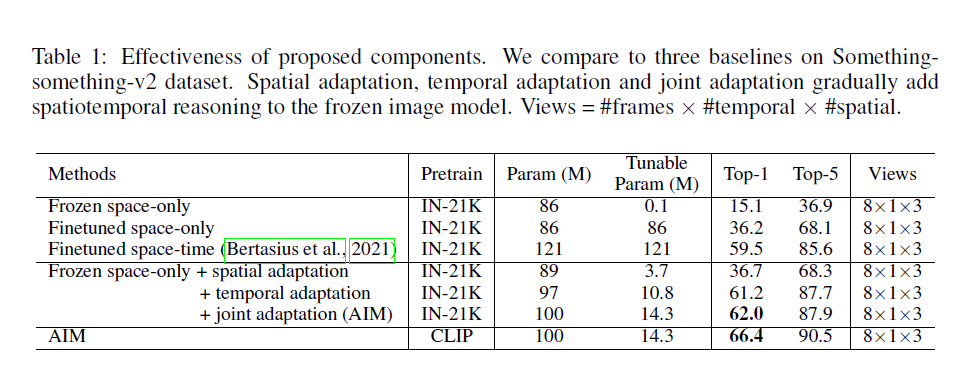
- 把预训练模型换成更好的CLIP,效果还能提升,证明和大部分模型工作是兼容的
用已有的模型
- 用已有的模型在新的方向上应用
- 不pretrain,比如用saliency detector(DeepUSPS) + 表征学习网络(DINO) + 聚类,可以无监督的生成标注和标签,从而训练语义分割模型(PSPNET)
即插即用的研究
- 以数据增强方法MixGen为例,是多模态的数据增强
- 起初是想做知识蒸馏,因为文本模型普遍比视觉模型大,所以想用文本大模型去蒸馏视觉的小模型,但是结果不尽如人意。
- 但是在看论文的过程中发现很多工作都没有做数据增强。有些工作说是数据集比较大,有些工作是因为标注和图像内容相关,某些数据增强方式不适合,Mixup可以缓解这个问题,所以最先考虑的是Mixup
- MixGen的雏形:图像侧两边混用,文本直接拼接,效果很好
