总结
- 相当于BERT的CV版本,题目中的autoencoder相当于是自编码器的意思,代表训练数据和目标来自于这个训练数据本身
- 设计训练任务的时候遮住的区域要足够的大,这样才能去学一些语义上的东西(否则做一下差值就算出来了),这样做同时也会减轻计算量
- 用小训练数据可以取得比较好的自监督学习成果,也和BERT一样在很多下游任务上也有很好的效果
- 作者对自监督掩码在CV和NLP领域不同的应用进展做了如下讨论
- 以往的卷积操作不好应用mask
- 图片里的像素信息比较冗余
- 还原的目标图像相比较于文本内容语义更加的基础
模型
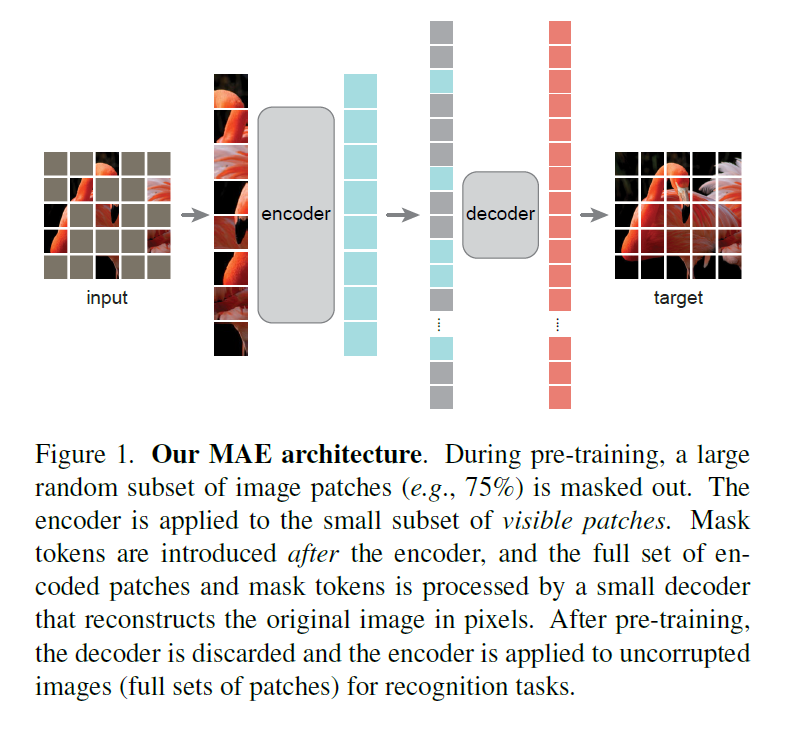
- 切块,掩盖住其中大概3/4的内容,对其余内容进行编码,然后在加上掩盖住的位置信息和一个统一的可学习的向量,一起放到decoder里面进行图片重建
- encoder比decoder略大一些,计算量相对来说要大。这个decoder的运算量相当于encoder的1/10
- 解码器的最后一层是线性层维度等于patch的维度(16 * 16)
- 损失函数是MSE
实验

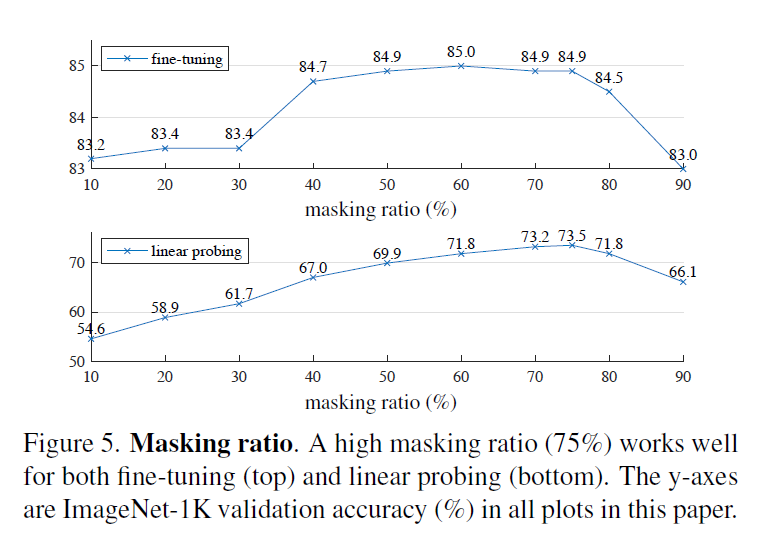
- mask 75% 效果最好
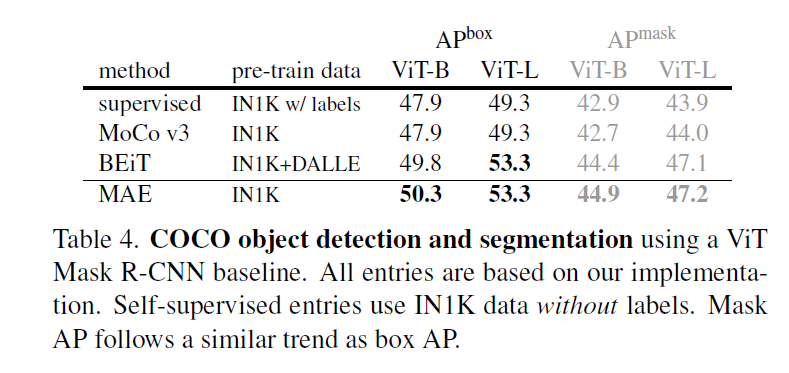
- 在多项任务里面打败了MoCo和BEiT