总结
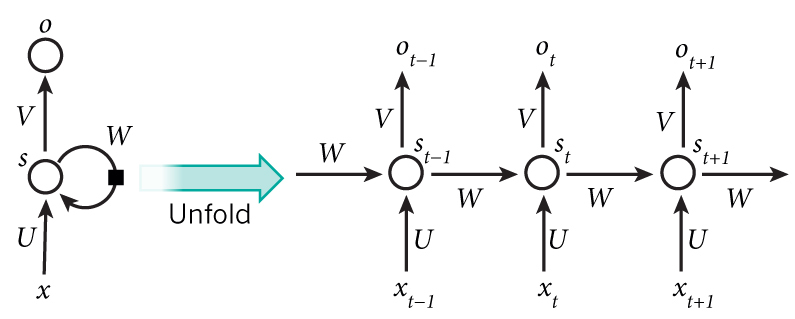
- 提出了一个代号为Inception的神经网络结构,开头点出此结构的最大作用是提升计算资源的利用率
- 是NIN的deep版本
- 参考Serre et al. 15 用多个size的filter来抽取信息;有两个不同点
- 所有网络中的filter都是学习得来
- 重复使用Inception结构组成一个更深的网络
- 又参考了Lin et al. 12使用1 * 1的卷积核来提升模型的表达能力;并且可以减少维度,使在同等的计算资源下网络可以更深更宽,从而提升效果
- ILSVRC 2014 数据集
- 1 model; 1 crops; top5 error: 10.07%
- ensemble(7 models, 144 crops); top5 error: 6.67%
Inception 诞生的心路历程
- 现如今提升网络效果主要靠提升网络的宽度和深度;这么做有两个问题:
- 容易过拟合
- 计算资源需求快速增长
- 因为权重矩阵中有很多的0,因此人们提出从全连接结构改成稀疏链接结构的方式
- 后来证明不行,因为稀疏结构的查找开销太大盖过了计算开销的节省,还不如不用
- 后来提出了用网络结构解决此问题的方式——Inception