总结
- 提出了一个代号为Inception的神经网络结构,开头点出此结构的最大作用是提升计算资源的利用率
- 是NIN的deep版本
- 参考Serre et al. 15 用多个size的filter来抽取信息;有两个不同点
- 所有网络中的filter都是学习得来
- 重复使用Inception结构组成一个更深的网络
- 又参考了Lin et al. 12使用1 * 1的卷积核来提升模型的表达能力;并且可以减少维度,使在同等的计算资源下网络可以更深更宽,从而提升效果
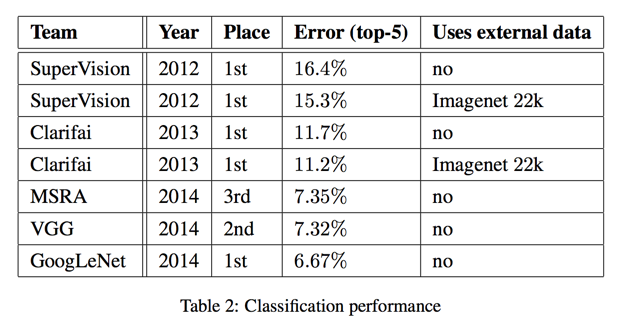
- ILSVRC 2014 数据集
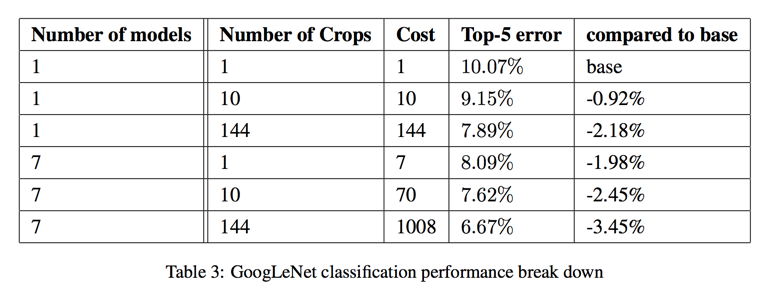
- 1 model; 1 crops; top5 error: 10.07%
- ensemble(7 models, 144 crops); top5 error: 6.67%
Inception 诞生的心路历程
- 现如今提升网络效果主要靠提升网络的宽度和深度;这么做有两个问题:
- 容易过拟合
- 计算资源需求快速增长
- 因为权重矩阵中有很多的0,因此人们提出从全连接结构改成稀疏链接结构的方式
- 后来证明不行,因为稀疏结构的查找开销太大盖过了计算开销的节省,还不如不用
- 后来提出了用网络结构解决此问题的方式——Inception
Inception结构详解
- 中心思想是找到一种简单可用的稠密结构去近似局部最优的稀疏结构
- 有两种方式可以从同样的数据中抽取更多的信息
- 在抽取信息后用1*1卷积再抽象一层
- 用少量不同size的filter对同样的信息做处理然后再拼在一起
- 为了避免patch-alignment issues(不懂), filter的size固定在1 1, 3 3, 5 * 5
- 除此之外又加了pooling结构
- 由于高层网络中空间信息变少,越高层的网络中3 3和5 5卷积层的比例也应该越来越少
结构改进
- 上述结构filter数量的增长太快计算不过来
- 引入1 1卷积层,在3 3 和 5 * 5的卷积计算之前先降低filter的数量
实验表明Inception结构只在高层网络中有收益,所以底层网络结构保持传统方式
Abstract
- propose a deep convolutional neural network architecture codenamed Inception
- the main hallmark of this architecture is the improved utilization of the computing resources inside the network
- the architectural decisions were based on the Hebbian principle and the intuition of multi-scale processing
Introduction
the design of the deep architecture presented in this paper included this factor rather than having a sheer fixation on accuracy numbers —— 1.5 billion multiply-adds at inference time
meanings of “deep”
- in the sense that we introduce a new level of organization in the form of the “Inception module” and also in the more direct sense of increased network depth
- In general, one can view the Inception model as a logical culmination of
Network in Networkwhile taking inspiration and guidance from the theoretical work by Arora et al
Related Work
standard structure starting with LeNet-5
- stacked convolutional layers
- followed by contrast normalization(optionally)
- followed by max-pooling(optionally)
- one or more fully-connected layers
recent trend
- increase number of layers
- increase layer size
- using dropout to address the problem of overfitting
filters of different sizes
Inspired by a neuroscience
Serre et al. 15 use a series of fixed Gabor filters of different sizes in order to handle multiple scales
differences in Inception:
- all filters in the Inception model are learned
- Inception layers are repeated many times
1 x 1 convolutions
proposed by Lin et al. 12 in order to increase the representational power of neural networks
remove computational bottlenecks $\rightarrow$ increasing the depth & width
R-CNN
leading approach for object detection
- to first utilize low-level cues such as color and superpixel consistency for potential object proposals in a category-agnostic fashion
- and to then use CNN classifiers to identify object categories at those locations
enhancements:
- multi-box
- prediction for higher object bounding box recall
- ensemble approaches for better categorization of bounding box proposals
Motivation and High Level Considerations
if we improve the performance of neural network only by increasing their size, there are two major drawbacks:
- more prone to overfitting
- dramatically increased use of computational resources
solution:
- moving from fully connected to sparsely connected architectures
but:
- the overhead of lookups and cache misses is so dominant that switching to sparse matrices would not pay off
another way:
- use architecture to do this ——
Inception - implied by 2
cautious:
- whether its quality can be attributed to the guiding principles that have lead to its construction
Architectural Details
The main idea of the Inception architecture is based on finding out how an optimal local sparse structure in a convolutional vision network can be approximated and covered by readily available dense components
two way to gain more information:
- a lot of clusters concentrated in a single region and they can be covered by a layer of 1 X 1 convolutions —— suggested in 12
- a smaller number of more spatially spread out clusters —— proposed in this paper
In order to avoid patch-alignment issues, current incarnations of the Inception architecture are restricted to filter sizes 1X1, 3X3 and 5X5
it suggests that adding an alternative parallel pooling path in each such stage should have additional beneficial effect, too
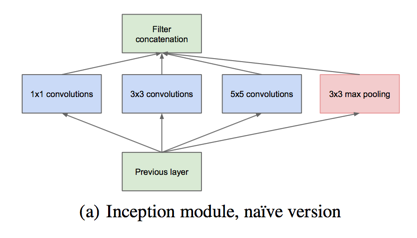
as features of higher abstraction are captured by higher layers, their spatial concentration is expected to decrease suggesting that the ratio of 3X3 and 5X5 convolutions should increase as we move to higher layers.
problem:
- inevitable increase in the number of outputs from stage to stage
solution:
- applying dimension reductions
- even low dimensional embeddings might contain a lot of information
- compress the signals only whenever they have to be aggregated union
- That is, 1 X 1 convolutions are used to compute reductions before the expensive 3 X 3 and 5 X 5 convolutions
- (only for pooling?) also include the use of rectified linear activation which makes them dual-purpose
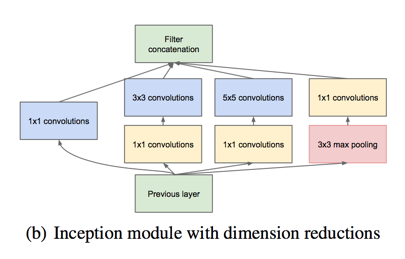
use only at higher layer
it seemed beneficial to start using Inception modules only at higher layers while keeping the lower layers in traditional convolutional fashion
main benefits of this architecture
- it allows for increasing the number of units at each stage significantly without an uncontrolled blow-up in computational complexity
- it aligns with the intuition that visual information should be processed at various scales and then aggregated so that the next stage can abstract features from different scales simultaneously
Another way to utilize the inception architecture is to create slightly inferior, but computationally cheaper versions of it.
GoogLeNet
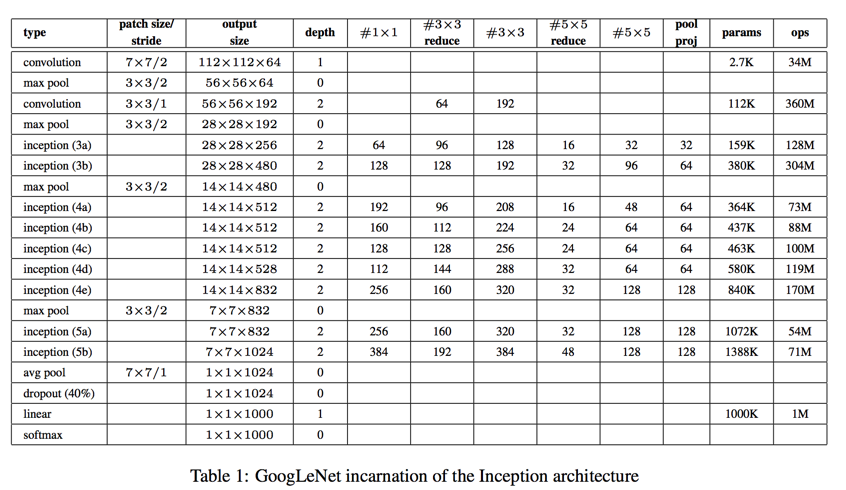
- activation: rectified linear unit
- input:
- 224 * 224
- RGB
- mean subtraction
It was found that a move from fully connected layers to average pooling improved the top-1 accuracy by about 0.6%
back-propagate effectively:
- adding auxiliary classifiers connected to these intermediate layers
- add discount weighted by 0.3 to total loss
- At inference time, these auxiliary networks are discarded
Training Methodology
- asynchronous stochastic gradient descent with 0.9 momentum
- decreasing the learning rate by 4% every 8 epochs
- Polyak averaging
sampling:
- work very well after the competition includes sampling of various sized patches of the image
- work very well after the competition includes sampling of various sized patches of the image
Experiment
ILSVRC 2014 Classification Challenge Setup and Results
- 7 models ensemble
- aggressive cropping
- resize the image to 4 scales(256, 288, 320 and 352)
- take the left, center and right square
- For each square, we then take the 4 corners and the center 224 X 224 crop as well as the square itself
- mirror
- This results in 4 X 3 X 6 X 2 = 144
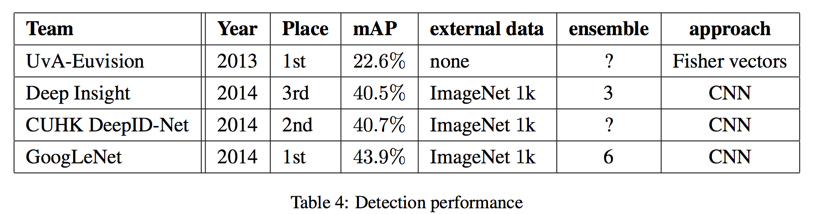
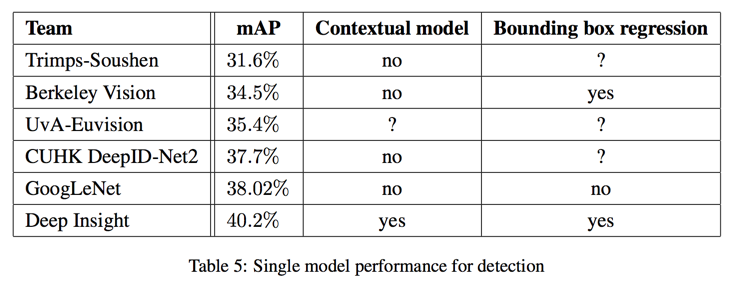
ILSVRC 2014 Detection Challenge Setup and Results
- 6 models ensemble
Reference
2. Sanjeev Arora, Aditya Bhaskara, Rong Ge, and Tengyu Ma. Provable bounds for learning some deep representations. CoRR, abs/1310.6343, 2013. ↩
12. Min Lin, Qiang Chen, and Shuicheng Yan. Network in network. CoRR, abs/1312.4400, 2013. ↩
15. Thomas Serre, Lior Wolf, Stanley M. Bileschi, Maximilian Riesenhuber, and Tomaso Poggio. Robust object recognition with cortex-like mechanisms. IEEE Trans. Pattern Anal. Mach. Intell., 29(3):411–426, 2007. ↩