0%
胶囊网络
- 创新点:“vector in vector out”代替“scalar in scalar out”?
- NLP很多任务其实做过类似的事情。
- 提出了一种新的“vector in vector out”方案,并且带有一定的可解释性
- 胶囊等同于向量。作者的说法是表达更多更丰富的信息。NLP中one-hot词表和embedding做类比?
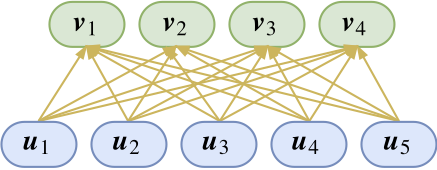
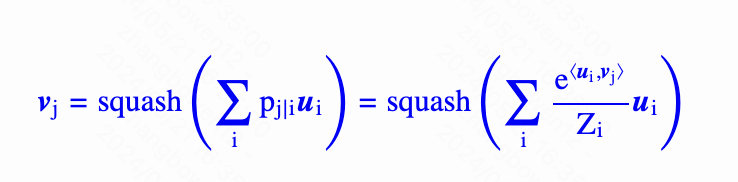
- 可以看做上面一层向量的聚类中心。胶囊的可解释性来源就是“输出是输入的某种聚类结果”
Squash

- 后一部分是把x的模长变为1,前面一部分是把模长变为0~1
- 为啥要用这种方式不清楚,可能是实验科学
动态路由
- 计算$v_j$的时候实际上是用到$v_j$本身,这个有点反直觉
- 本文的做法是把$v_j$初始化为$u_i$的均值,然后反复迭代,这就是动态路由

矩阵变换
- 上述方法可以迭代去求解$v_j$,但是下一层的所有节点理论上就都是一样的了,所以在计算的时候实际上需要做一个矩阵变换

共享参数
- 可以让不同u的参数矩阵共享,从而达到减少参数数量和摆脱输入层数量的限制的效果
CIKM 2019 MIND
- 为每个用户生成多个embedding来表征用户兴趣

- 输入特征为用户特征、用户行为序列以及target(行为序列后下一个交互的item)
- 先过embedding层然后过胶囊网络聚类多个特征,与用户特征concat后过多层relu成为用户侧特征
- 初始化权重服从一个正态分布,代替原文的都是0
- 参数矩阵共享权重,输入可以变长(用户行为序列的长度不一致)
- 训练时把用户侧特征当做K、V,target embedding当做Q去过attention得到新的用户特征,用新用户特征和target做内积算softmax loss
- 服务的时候直接用用户侧特征去做召回
KDD 2020 ComiRec
- 提出了一种在统一的推荐系统中集成了可控性(controllability)和多兴趣模块的框架
- 通过在线上推荐系统的实现和学习,探索了个性化系统可控性的作用
结构

- 通过Multi-Interest Framework抽取兴趣聚类,得到K个interest embedding
- 两种方案一个是ComiRec-DR,就是胶囊网络方案
- 另外一是ComiRec-SA,自注意力方案
- 训练时会选取与target embedding最近的interest embedding做计算算softmax loss
- 在线上服务的时候会用每个interest embedding去召回N个item,然后再通过aggregation module合并成N个item返回
ComiRec-SA
- 其中$H \in R^{d \times n}$, $w_1 \in R^{d_n \times d}$, $w_2 \in R^{d_n}$
- 将$w_2$ 的维度变为 $d_n \times K$即可得到K组结果
Agregation Mdule
- 比较朴素的方式就是按照内积的值排序。这也是MIND用的方法



参考