0%
总结
- 提出CLIP, for Contrastive Language-Image Pre-training
- 在imagenet上,无监督训练打平Res50,堪比alexnet
- 训练流程如下,使用已有图片、文本对的数据集进行pairwise训练。4亿条清洗过的数据
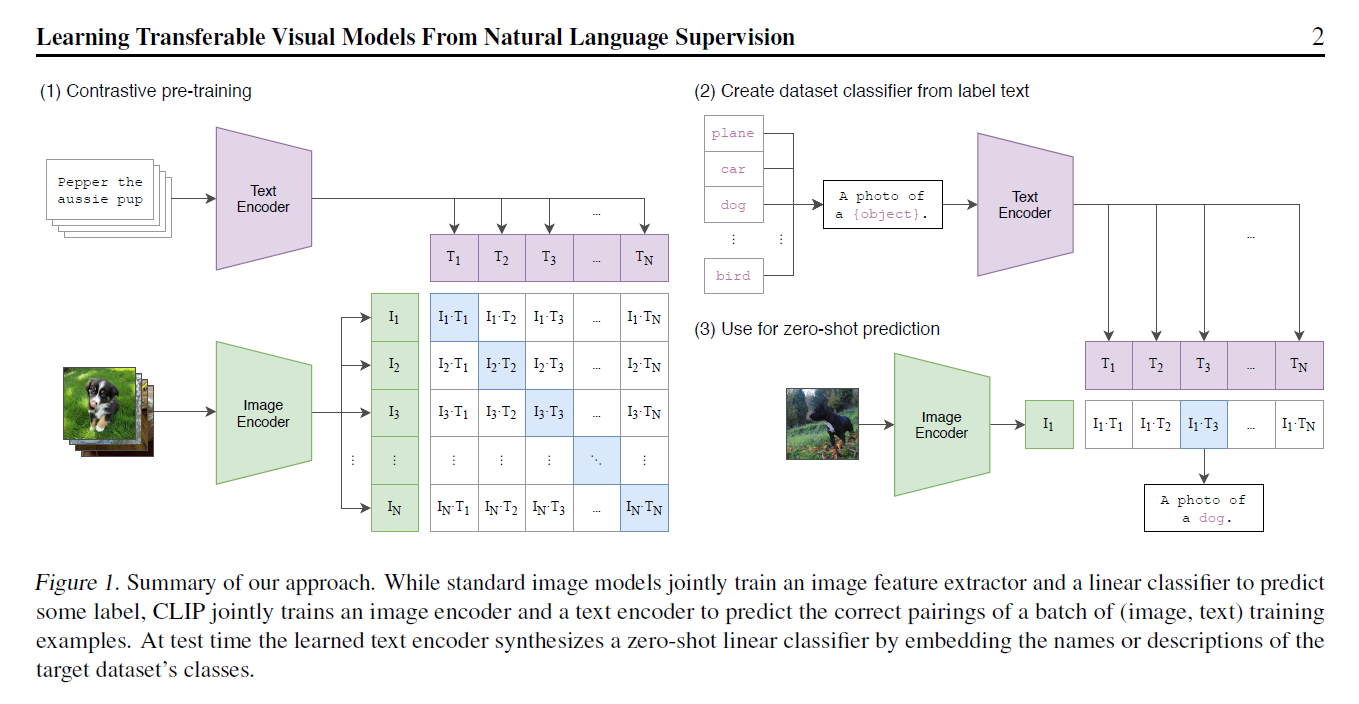
- 这种方式训练是没有分类头的无法直接落地应用。作者引入prompt template机制,也是pair wise的去做分类。用句子效果比用直接裸的单词效果更好,因为训练的时候看到的都是划分好的句子么。这个template也是有一些讲究的,所以后面还提到了prompt engineering和prompt ensemble
- 这种方式可以很好的拓展,不局限于训练中所使用的的类别,摆脱了categorical label的限制
- 迁移效果非常好,在OpenAI官网上列举了各个不同数据集的效果。但是这块有点存疑的是数据量级的差别4亿对100万

- clip后面的拓展工作
- clip + styleGan,ICCV oral
- ciipDraw
- clip + 目标检测
- clips 视频检索,通过文本去搜视频里的内容,case都很惊艳
摘要
- 目前已有的方法是在固定类别的数据集上进行学习,作者想引入语义的信息当做监督信号进行学习
- 所用数据集体量大约4亿,可以和有监督的Resnet在ImageNet上面打平
- 开源了预训练模型和推理代码
- 受到文本模态(GPT3)的启发,想在CV领域应用无监督
- 和之前17年的工作有一些相似之处,但是17年并没有transformer,所以效果并不是特别好
- transformer之后还有挺多的工作和clip比较像,但是在训练方式和数据集规模上都有一定的差距
- 还有一些弱监督工作的探索,类目拓展了,但是还没有到可以摆脱类目限制的地步
- 作者总结是主要是数据规模和模型规模上的差异
- 因为要展示模型的迁移能力,作者在30个数据集上都取得了不错的效果
模型
- 用文本监督信号去训练视觉模型非常有潜力
- 造了一个很大的数据集,和训练GPT-2的那个数据集比较接近
- 训练效率很重要,动辄需要训练很多十几个GPU年,训练由预测型任务(给一张图片输出预测词)改为对比学习,训练效率提升四倍
- encoder出来的向量通过投射层投射到多模态空间,这个投射层是线性投射,怀疑之前在对比学习非线性投射层的涨点主要是针对图片单模态的涨点
- 温度参数可训练
- 图片模型是resnet或transformer,文本模态使用transformer
- 用最小的resnet50去做超参搜索
- batch size是3w+(SimCLR是8000+)
- 混合精度
实验
- 研究transfer 的动机:标签闭集训练的结果还是需要有标签的数据去做微调
- prompt 工作:歧义性、训练推理一致性
- 一个简单的模板直接提升了1.3%的准确率
- 加类型限定、双引号标注
- ensemble多种提示方式叠加
- 最终使用的模板数量多达80个
- 在多个数据集上验证,效果有好有坏,通常来说简单物体数据集效果好,抽象数据集效果差
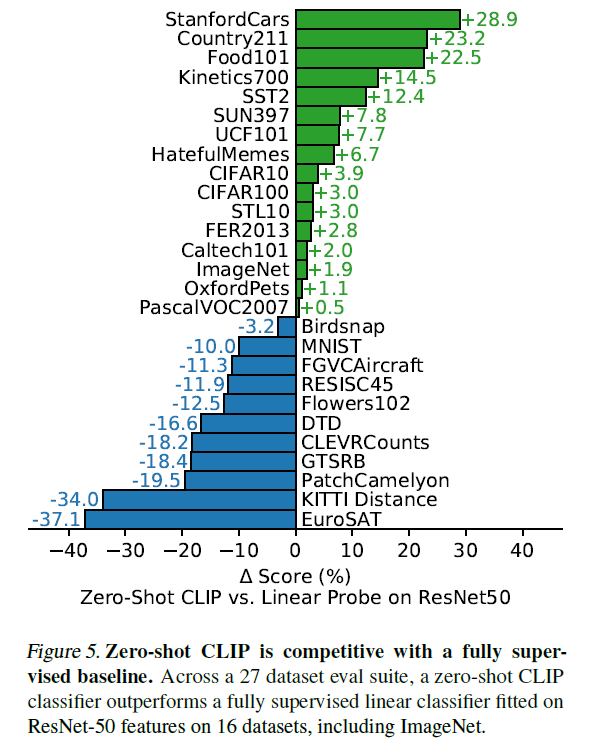
- 作者认为有些特定领域的问题做zero shot肯定是不合理的,所以又加了few shot的结果对比(把图片模态冻住,只训练文本)
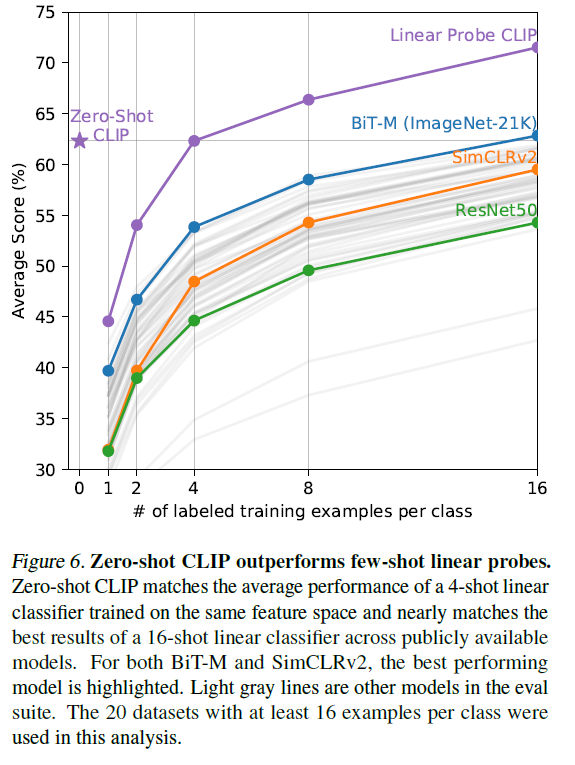
- 表征学习有个悖论:如果你把网络全部放开无法证明预训练模型的好坏;如果冻住主干只训练分类头,那么就很不灵活,无法达到很好的效果
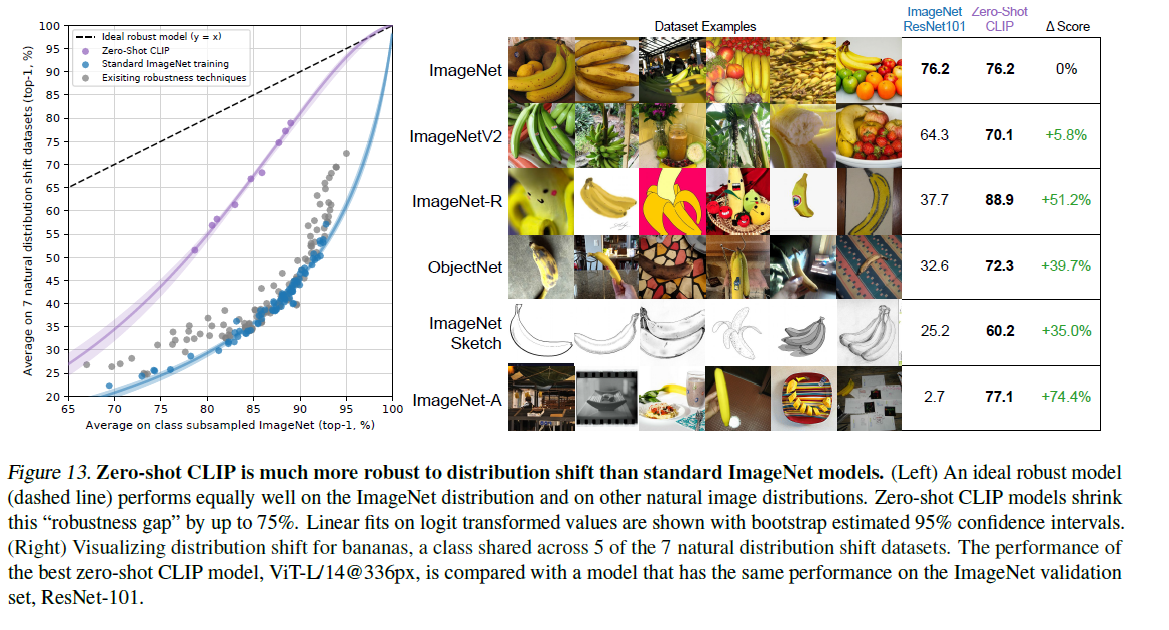
- clip在数据分布变化比较大的数据集上有很好的表现
- 和人类对比(5个人,一个数据集),很有意思的点
- 人类oneshot和twoshot在准确率上没有差别
- 对于clip和人来说各个类别难易度的趋势是一致的
- 数据去重实验,验证clip本身效果就比较好
局限性
- 和state of art的有监督训练模型比有差距
- 有很多领域,比如一些抽象概念的领域,clip都不行
- 数据分布如果差距特别大,泛化性也不行,比如MNIST
- 会有few shot不如zero shot的情况
以CLIP为基础的工作
LSeg: language driven semantic segmentation
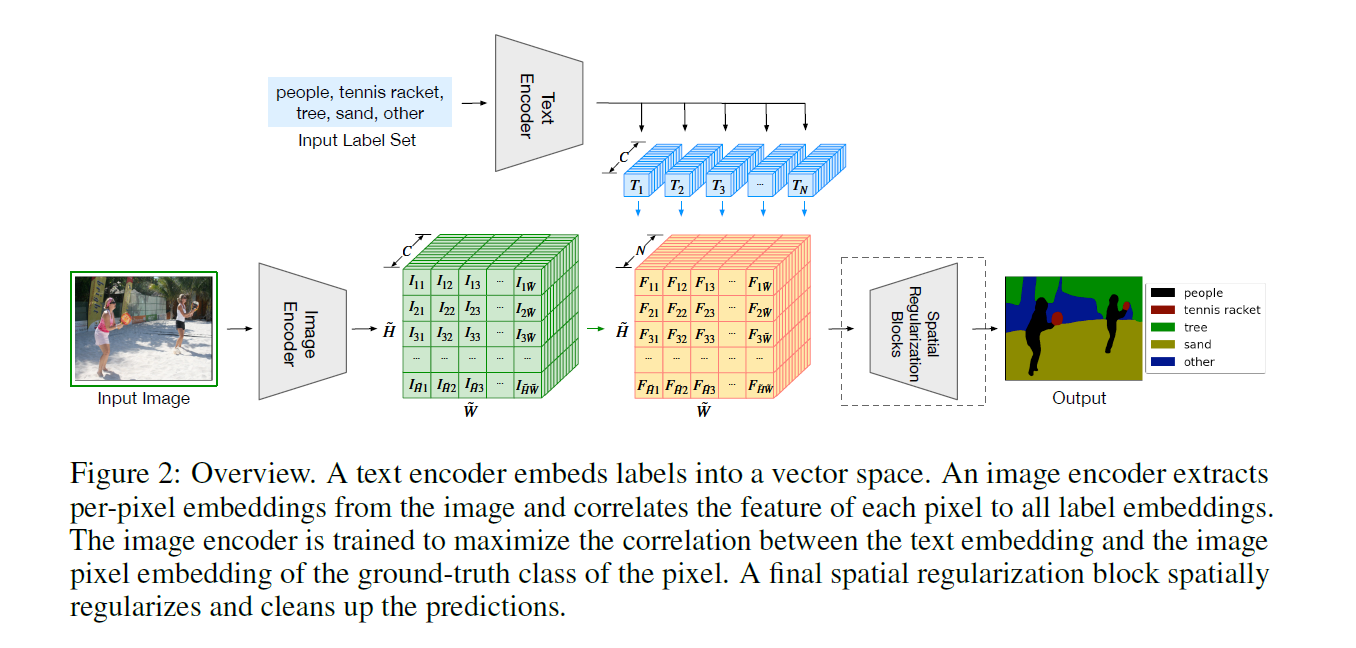
- 图像编码器是DPT结构 = ViT + decoder(upscale维度)
- 文本编码器是CLIP的参数没有进行训练,可能是分割数据集整体比较小的原因
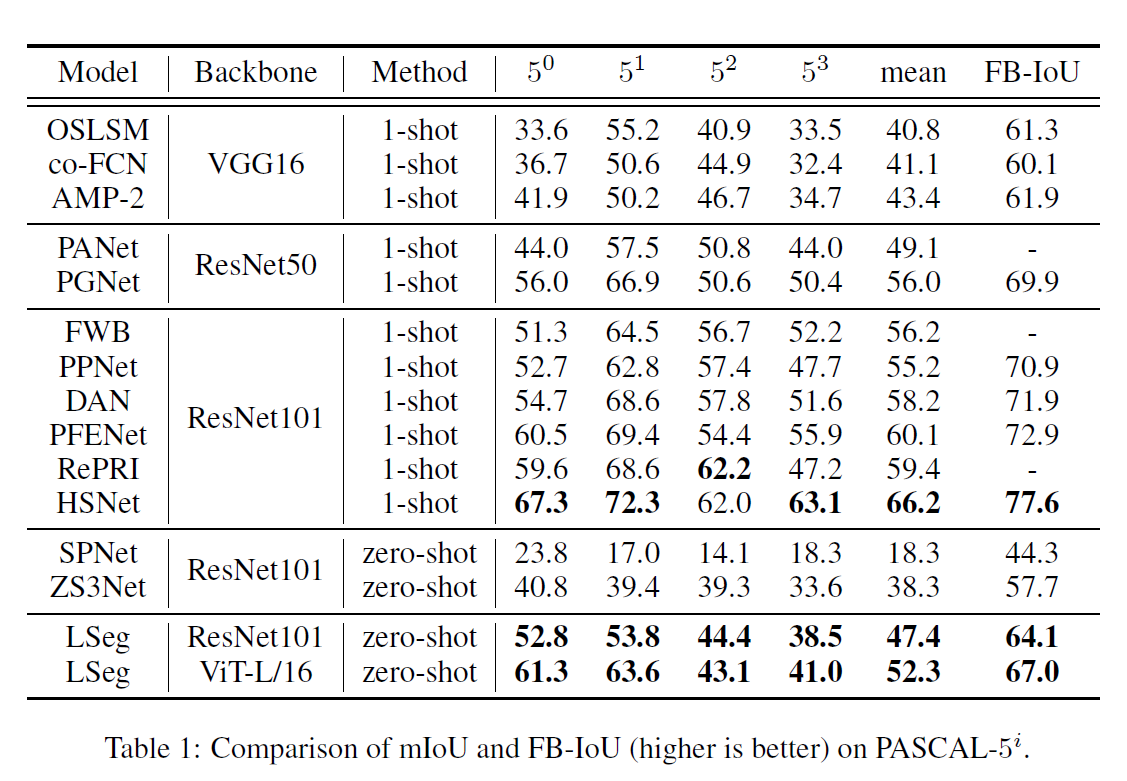
- 效果超过之前zero shot的方法,但是和有监督one shot还是差距特别远
GroupViT
- 摆脱分割任务对于标注的需求量
- 引入grouping block和grouping tokens
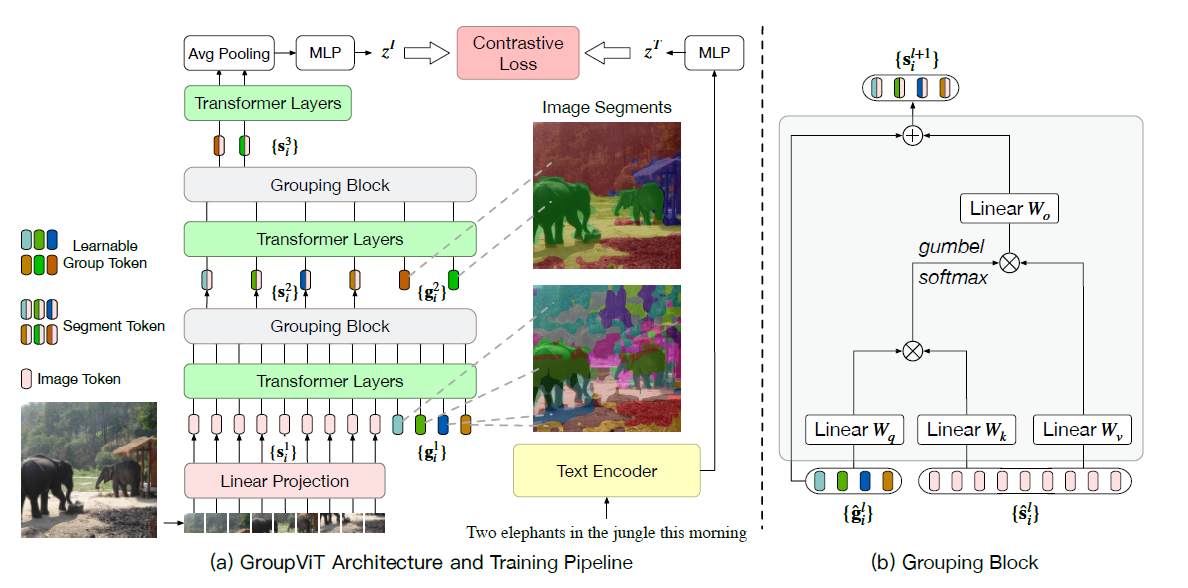
- 主体框架是12层Vit,输入除了image patch之外,还有group token。这个token的维度和patch的维度是对齐。patch维度是196 384,token是64 384。这个group token其实和文本分类中的cls token效果类似,这里可以看作为聚类中心
- 原始的输入经过6层transformer之后通过group block把image token分配到每个聚类中心,同时在下一层再引入新的更少的聚类中心(8 * 384)。因为分配操作不可导,所以用gumbel softmax替代
- 训练是文本和图像的对比学习loss,8个聚类中心过avg pooling得到一个384维度特征,与文本特征进行学习
- 分割的时候对每个聚类中心去算距离最近的文本,得到改聚类中心的所属类别实现分割
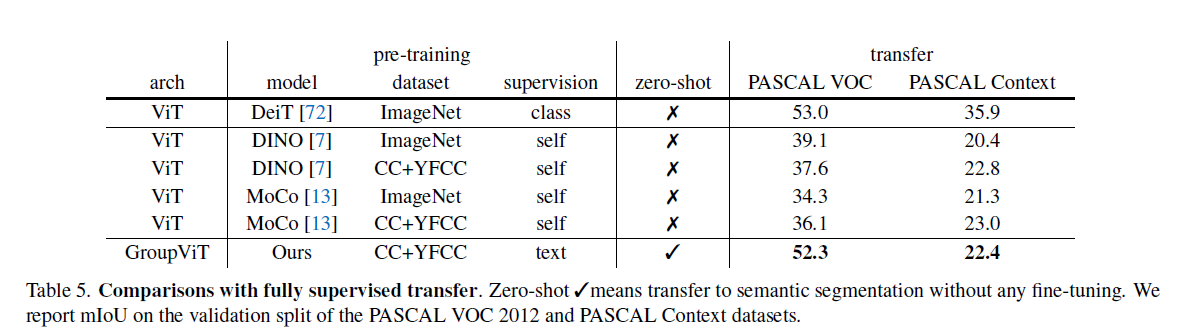
- 从实验效果上来看和有监督方法的差距还是比较大,分割的很好但是分类问题很大,背景的相似度阈值是个比较麻烦的点
ViLD
- 因为目前的检测任务标注类别总体很有限,作者想做开集合的目标检测
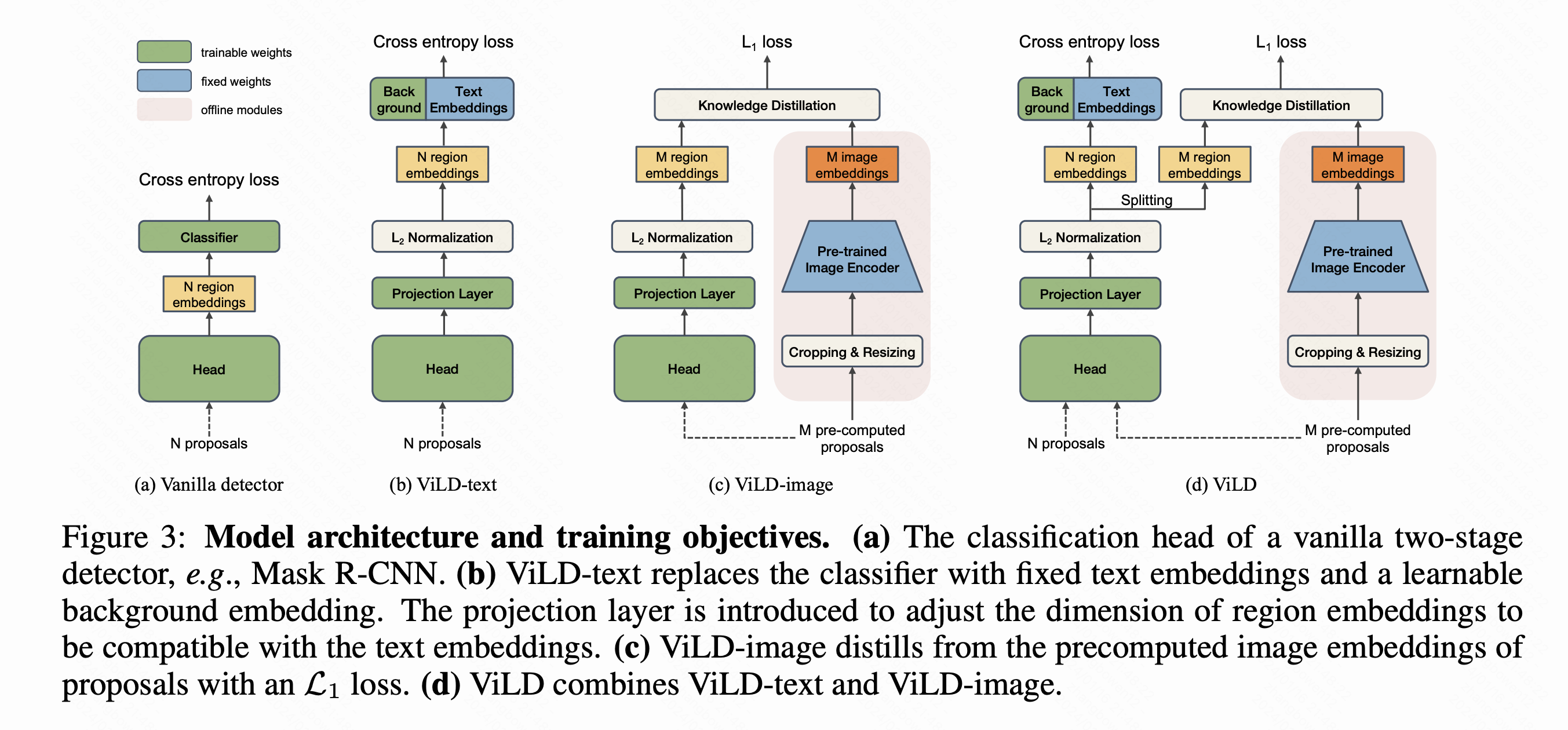
- Base版本模型类似于RCNN,两阶段训练。文章提出的结构基本都是从第二阶段开始的,输入是已经提取好的proposal
- ViLD-text:提取出每个region的embedding后和文本(经过prompt)提取的embedding和一个特殊的背景类embedding点乘做分类,目前还是用基础的标签类别来做有监督学习
- ViLD-image:使用CLIP图像编码器部分去提取embedding,让我们的网络和CLIP这个网络去做知识蒸馏,学习clip的输出(L1 Loss)。这样可以突破现有标签体系的限制;为了节约CLIP的计算开销预先提取好proposal给到CLIP去计算缓存下来
- ViLD完整版就是用蒸馏好的模型来做检测任务
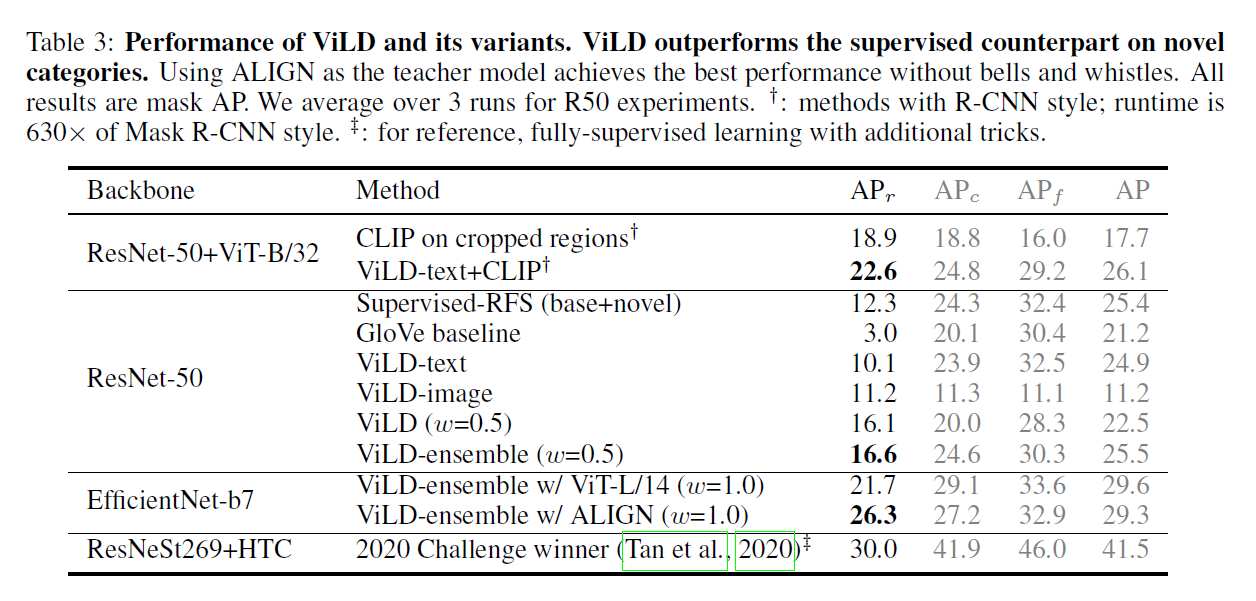
- 实验效果在长尾数据集上超越了有监督学习(但是这个数据集长尾数据标注确实很少),总体精度不如有监督训练
GLIP
- 结合目标检测和phrase grounding,实现detection任务的无监督训练
- grounding计算过程是模型分别计算图片和文本的embedding,然后计算相似度
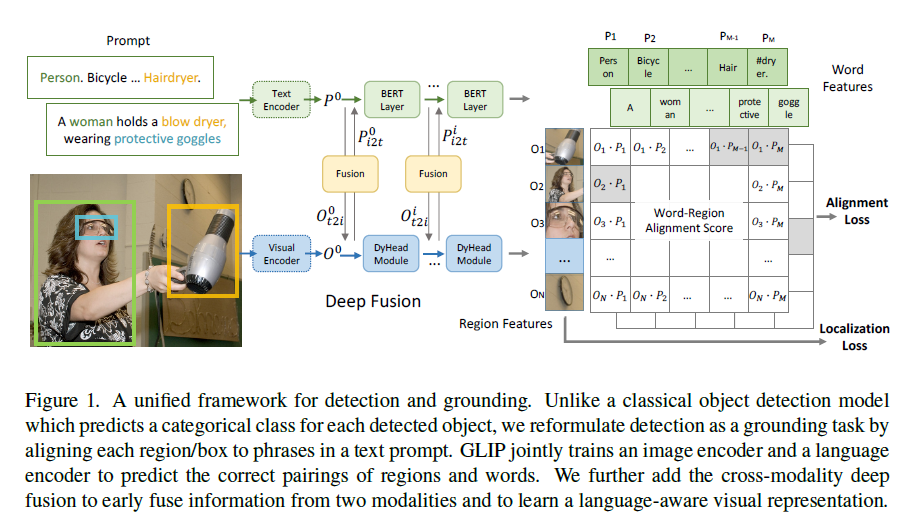
- 优化alignment loss和localization loss之前多加了一些层去融合图像特征和文本特征
CLIPasso

- 以往的工作是data driven的,种类和生成图片的抽象程度都比较受限
- 以往有分析(Multimodal neurons in artificial neural networks)研究了CLIP在简笔画上的表现,发现很好,作者就尝试了CLIP
- 建模基于贝兹曲线,本文用四个点定义一个曲线,通过模型参数去学习这个曲线的形状
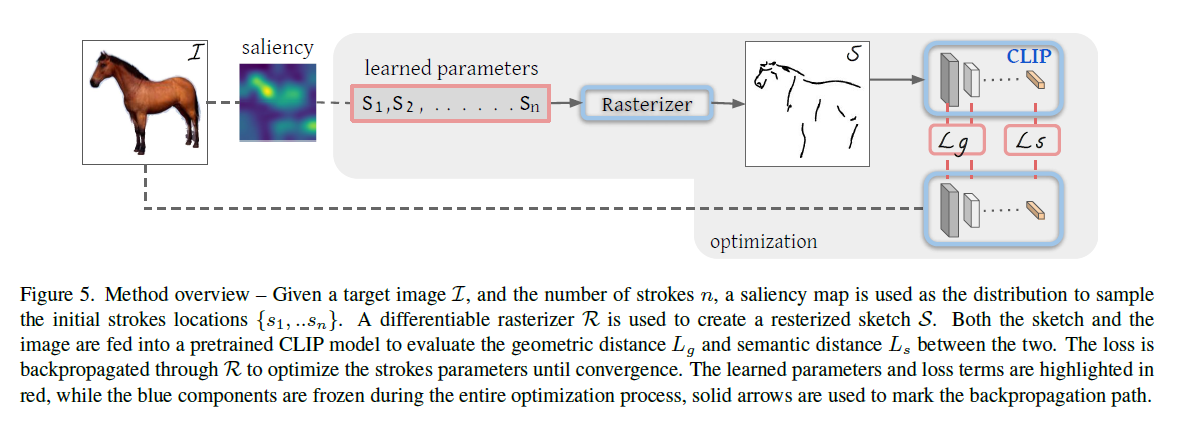
- 训练流程分别用原始图像和简笔画过CLIP模型,让生成出的特征尽可能相似(语义目标函数Ls)。同时用CLIP前几层的函数值也一起去做损失函数计算(几何目标函数Lg)
- 实验发现初始化方式对结果影响很大,所以又探索了一个让结果更稳定的初始化方法。使用ViT过一遍图像,用最后一层的加权注意力头做平均,得到一个注意力的热力图,在注意力高的地方去采点
- 作者有加了一个后处理流程,一次生成多张图片,把每个图片的loss比较下,返回更低的那个图
- 此模型有很多优势:
- 可以画不常见的物体的简笔画
- 可以通过控制每个贝兹曲线点的数量来调解简笔画的抽象程度
- 目前也有一些问题:
- 如果原图有背景,那么效果就会大打折扣(先用一个网络把物体抠出来)
- 贝兹曲线的点需要手动控制
CLIP4Clip
- 文本和视频匹配的任务,整体结构和CLIP一样,只是图像侧加了时间维度变成了视频
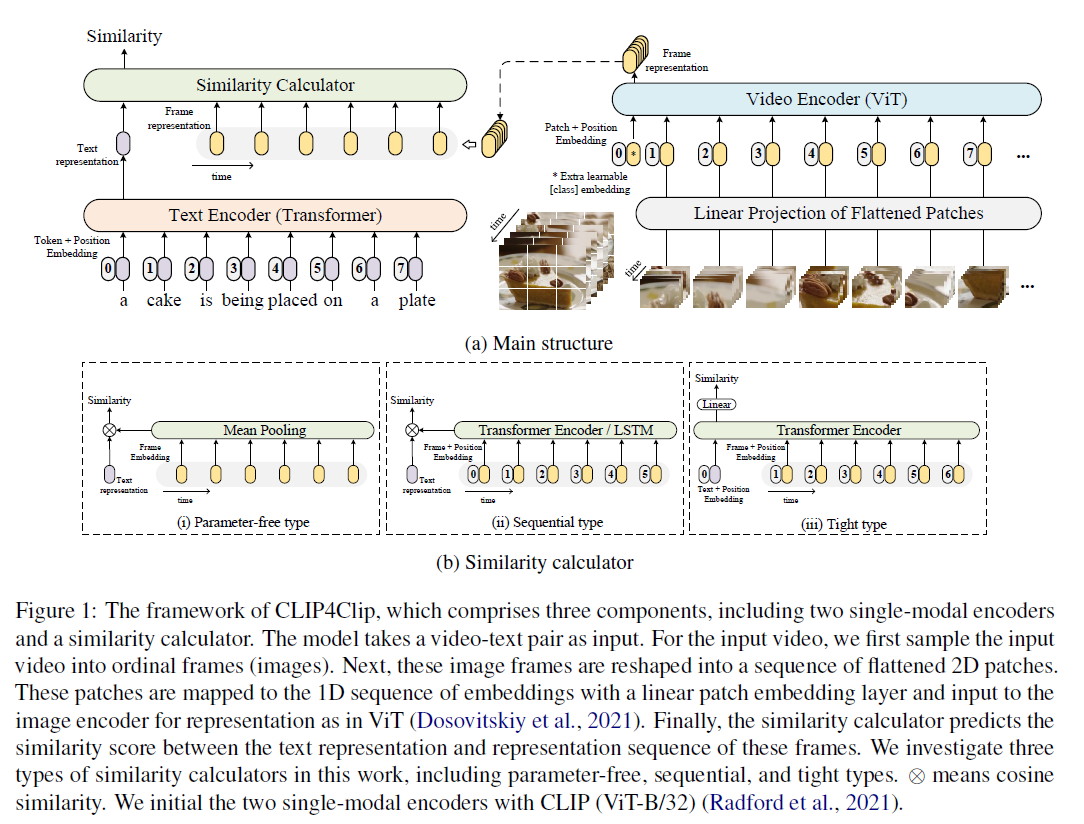
- 由于图像那边变成了多个CLS token,怎么和文本算相似度就成了一个问题,作者这里尝试了三种方法
- 直接平均,简单效果也不差,没有时序信息
- 用transformer / LSTM做序列建模
- 把文本和多个图像token一起扔给transformer进行训练,相当于early fusion
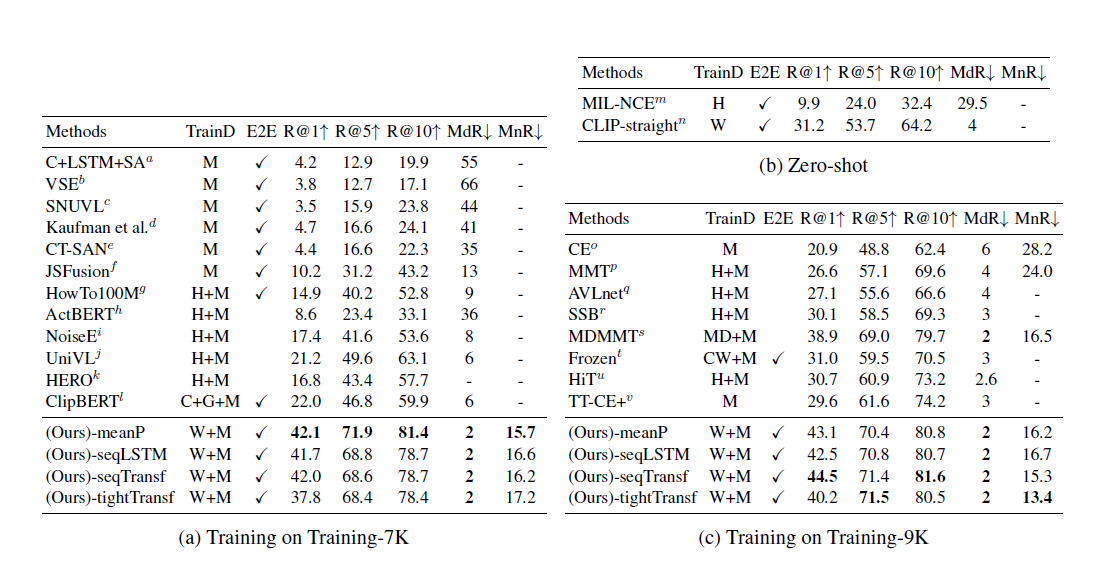
- 实验结果来看CLIP本身zero shot的结果已经很强了
- 训练数据少的时候直接做平均的效果就很好,多的时候用transformer效果好,但不多,大多数情况下直接做meanpooling就可以了
ActionClip
- 动作识别的标签比物体视频任务更难获得,并且有些还比较抽象,所以想迁移CLIP来做动作识别
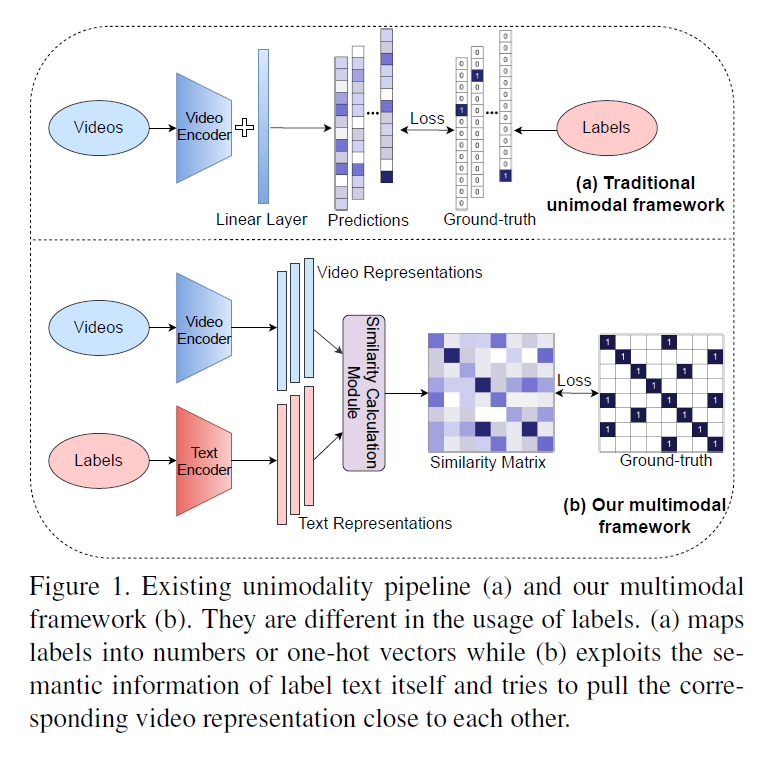
- 一个batch中一个视频可能与多个label构成正样本,所以损失函数由之前CLIP训练的cross entropy换为了KL散度
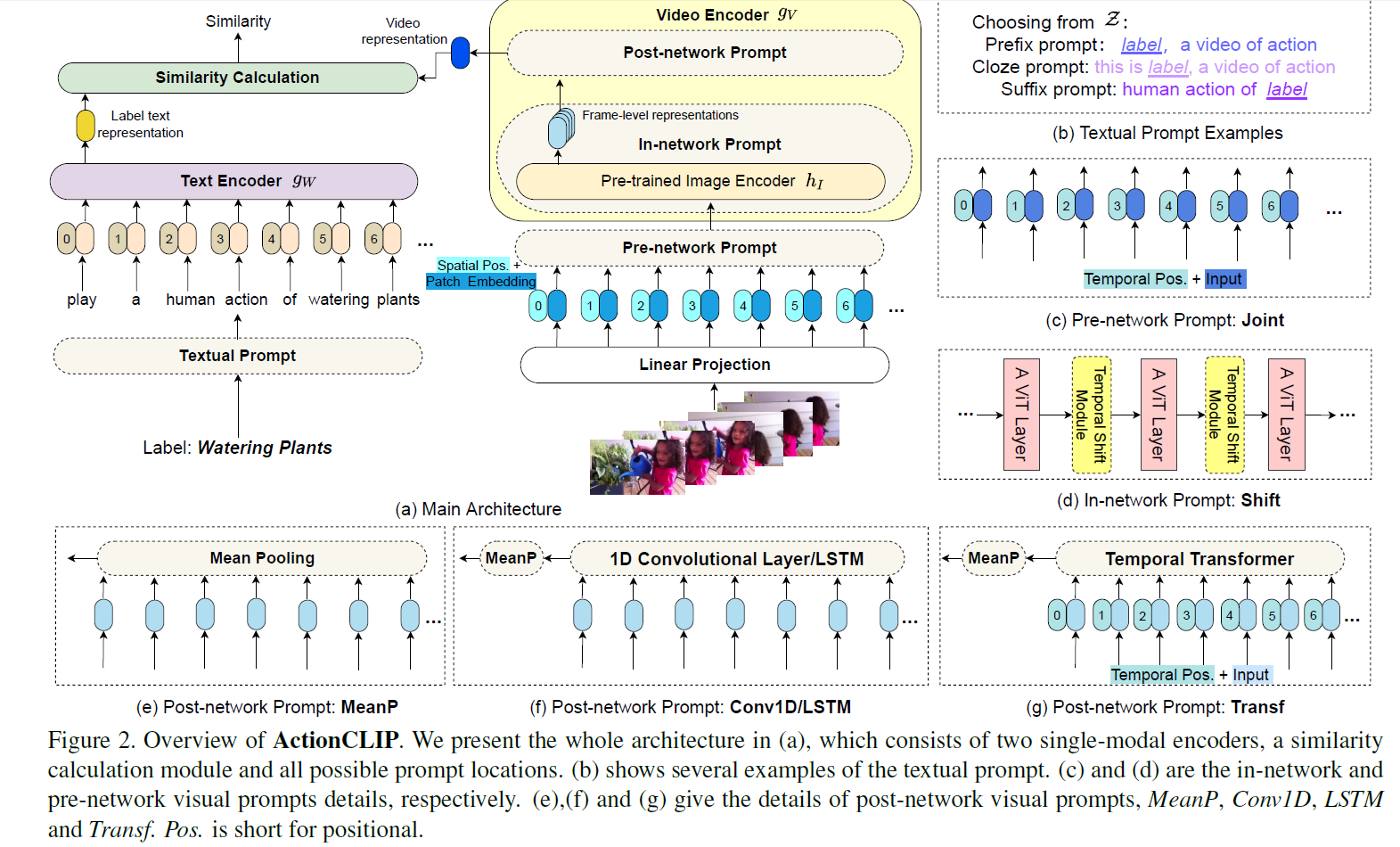
- 整体流程就是文本视频分别编码算相似度,但是有一些创新
- 文本用了prompt包装
- 图像这边也用了prompt
- 加pos bias
- 使用shift 操作,对channel维度进行偏移,即某些通道来自于上一时刻,某些通道来自于下一时刻,增加时序建模
- 多帧特征融合为单帧特征,用的是clip4clip方案
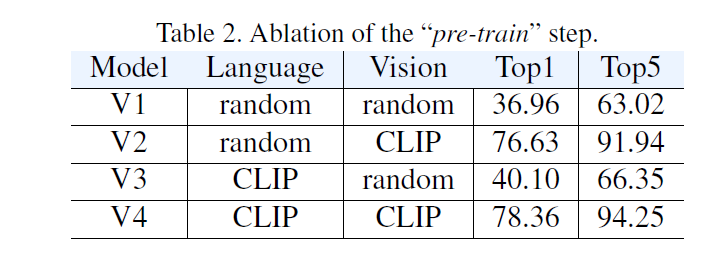
- 初始化参数的效果非常显著
- 文本的初始化没有那么重要
CLIP-ViL
- 没有新方法,只是把视觉编码器换成了CLIP看看效果
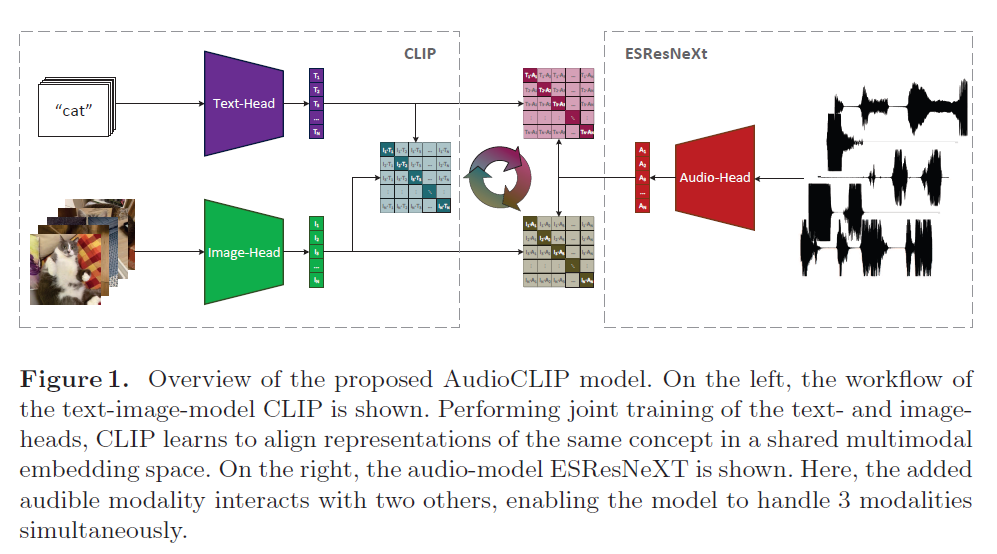
Audio-CLIP
Point-CLIP
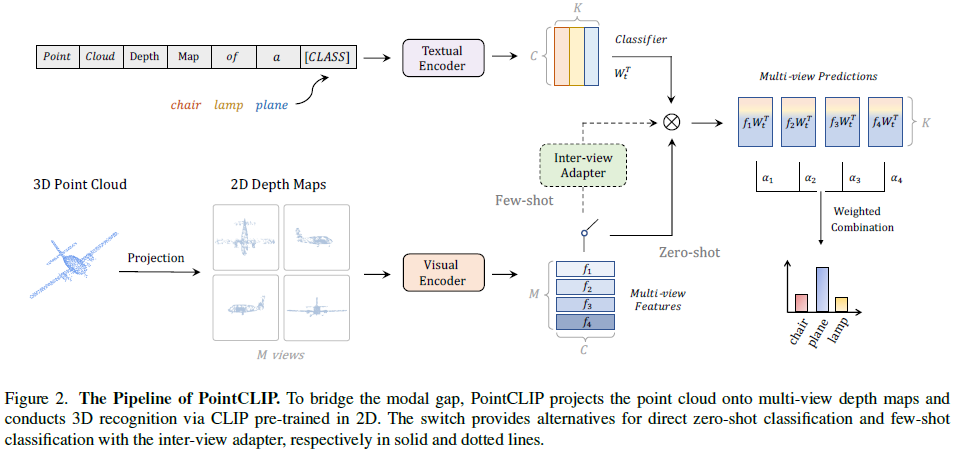
- 作者使用一种映射把3D点云映射到2D,然后就是应用到CLIP的范式
- 没想到CLIP应用的下游任务领域这么广……深度图都可以
Depth-CLIP
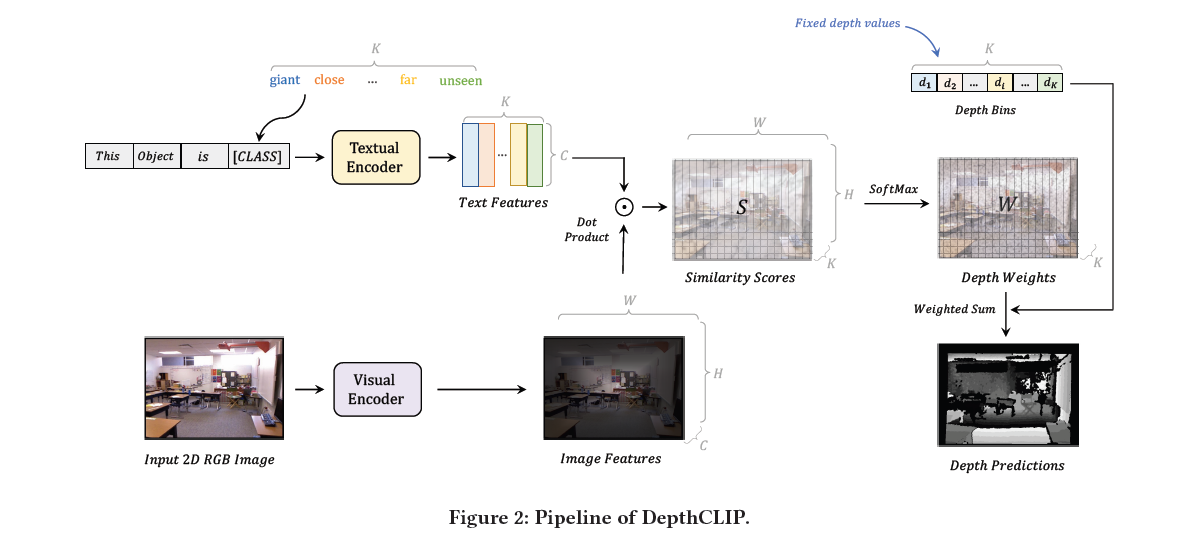
- 把深度回归问题变为分类问题,图像特征和文本特征相乘,然后argmax一下得到图片每个位置的深度分类结果