ViT的特性

在以下CNN做的不太好的场景ViT的表现会好一些:
- 遮挡
- 数据分布发生偏移
- 加对抗性的patch
- 重排列
总结
- ViT训练资源少,指一块TPU V3 跑2500天
- Transformer目前还没有看到性能饱和的现象
- Transformer应用到图像的难处:计算复杂度和序列长度的平方成正比,所以对于天然的图像来说不太适合(目前的NLP长度大概是512),所以一个朴素的方向是降低序列长度
- 比如用resnet最后一层当做输入
- 用轴注意力,宽和高分别引入注意力机制
- sparse transformer
- 本文的做法是把图像分为多个patch,每个Patch的像素数量为16 16,这样以patch为粒度,一张224 224图像的序列长度就变为14 * 14 = 196了
- 有监督训练
- 但是比不过同等大小的残差网络
- 少了归纳偏置,一个是locality即靠的近的相关性越强,另一个是平移不变性
- 上了大规模数据集之后就效果拔群了
模型
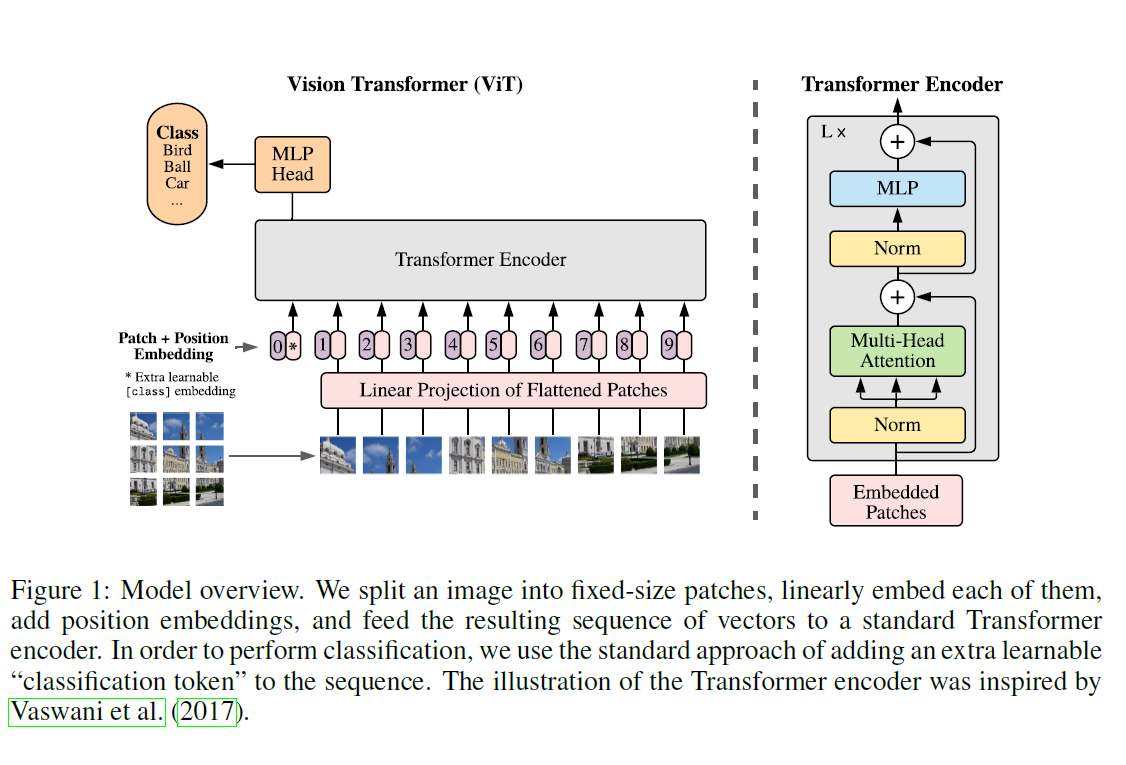
- 划分patch,分别过线性投射层(全连接,本文是768* 768)
- 加position bias
- 在前面加上分类头,用分类头的结果去做训练
消融实验
- 分类头
- 也可以用average pooling去做
- 不过需要调参
- position编码
- 使用二维编码,横纵分别查d/2长度的向量再拼接使用
- 用那种都成
其他讨论
- 训练好的模型不太好向其他不同分辨率的任务迁移,主要是position bias的问题,这个东西可以通过插值来进行缓解,但是不彻底
实验
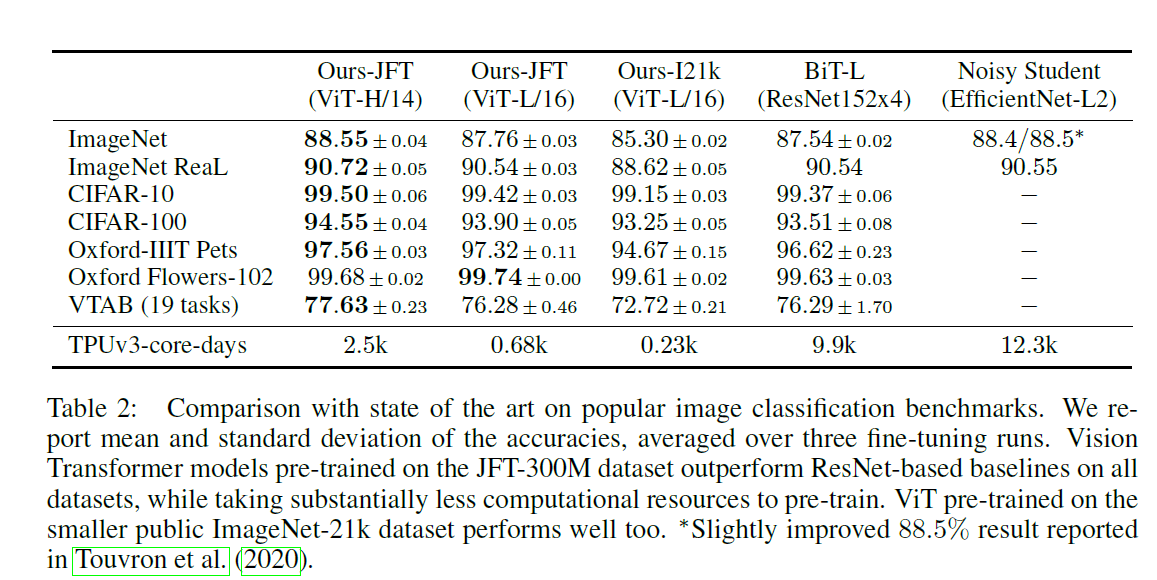
- 性能没有超越太多,但是训练速度相对BiT-L和Noisy Student来说快很多
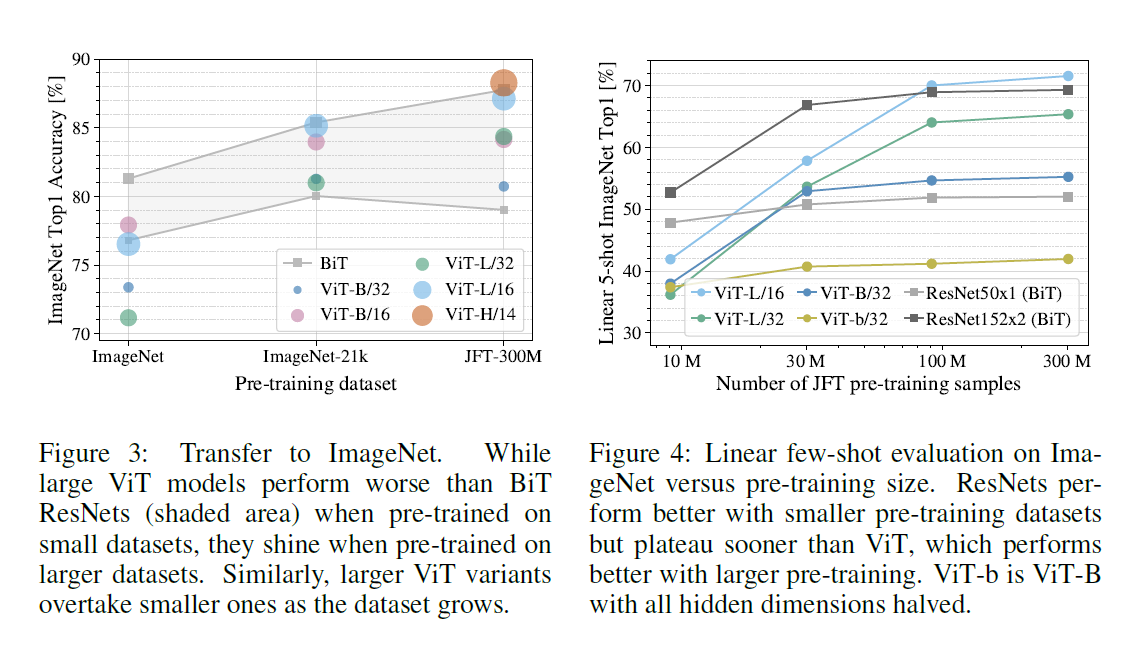
- 数据集越大相对于CNN越有优势

- position bias和注意力机制都可以按照预期工作