总结
- 在GAN的基础上加上了条件输入(对于D和G同时加)
- 目标函数改为$\underset {G} {min} \underset {D} {max}V(D,G) = E_{x \sim p_{data}(x)}[logD(x|y)] + E_{z \sim p_z(z)}[1 - log(D(G(z|y)))]$
- 如果没有对于条件的需求在实验中有CGAN的效果并不比GAN的效果好
- CGAN可以按照条件输入输出特定的随机值
- 给定一个数字输出特定数字的手写图片
- 给定一个图片输出该图片的tag 概率分布,取较大者作为图片的tag,实现自动化tagging
Abstract
this net can be constructed by adding condition information to both generator and discriminator
Introduction
by conditioning the model on additional information it is possible to direct the data gener- ation process
Related Work
multi-modal learning for image labelling
present works problems:
- hard to predict output categories
- almost one-to-many mapping
solution:
- first issue: leverage additional information from other modalities
- second issue: use a conditional probabilistic generative model
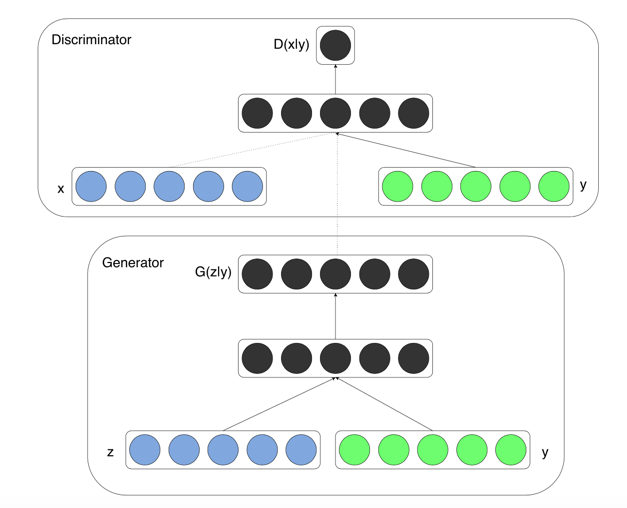
Conditional Adversarial Nets
Generative Adversarial Nets
a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G. Both G and D could be a non-linear mapping function, such as a multi-layer perceptron
Conditional Adversarial Nets
Generative adversarial nets can be extended to a conditional model if both the generator and discrim- inator are conditioned on some extra information y
objective function:
Experimental Results
Unimodal
trained a conditional adversarial net on MNIST images conditioned on their class labels, encoded as one-hot vectors

outperformed by several other approaches
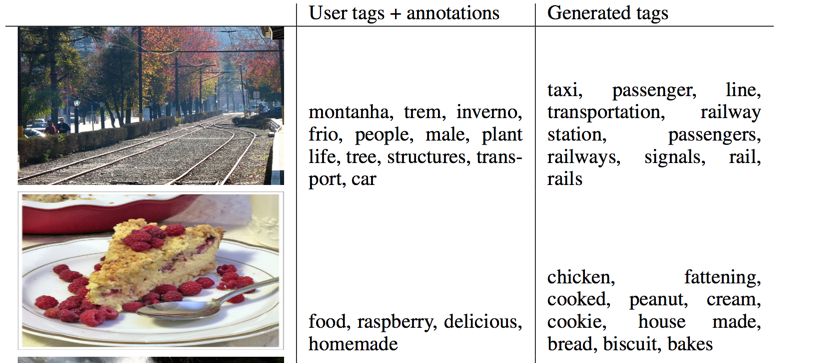
Multimodal
use User-generated metadata on Flickr
Future Work
in the current experiments we only use each tag individually. But by using multiple tags at the same time