总结
- CNN中的卷积层的filter个数可以增加网络的表达能力
- 但是过多的数量会让计算开销增加的太大
- 传统方法用maxout函数来达到增加表达能力又不增加太多计算开销的目的
- 当没有对于隐藏层分布先验信息的情况来说,用一个能拟合所有函数的结构要更适合一些(maxout只能拟合所有凸函数)
- 比较常见的能拟合所有函数的结构有两个
- radial basis network
- multilayer perceptron
- 本文选择了multilayer perceptron 有如下两个原因
- multilayer perceptron可以使用反向传播训练与CNN结合的比较好
- 可以扩展,自己当做一个深层网络
- 新的结构就叫做mlpconv,其实就是后面接了两层1X1卷积
- 此外还提出了一种新的结构全局平均池(Global Average Pooling)代替传统最后一层的FC层
- 先为每个分类结果项生成一个feature map(最后一层卷积的filter数量等于类别数量即可)
- 然后对每个feature map取平均得到一个向量
- 直接用改向量做softmax
- 这么做的好处有两个
- 让最终feature map的结果更加直观
- 这种结构没有参数,避免过拟合
- CIFAR-100实验结果
- top1 35.68%
Abstract
We propose a novel deep network structure called “Network In Network”(NIN) to enhance model discriminability.
We build micro neural networks with more complex structures to abstract the data within the receptive field.
Introduction
The convolution filter in CNN is a generalized linear model(GLM)
Replacing the GLM with a more potent nonlinear function approximator can enhance the abstraction ability of the local model
In this work we choose multilayer perceptron as the instantiation of the micro network
Instead of adopting the traditional fully connected layers for classification in CNN, we directly output the spatial average of the feature maps from the last mlpconv layer as the confidence of categories via a global average pooling layer
Convolutional Neural Networks
- classic convolutional neuron networks, use liner rectifier unit as example, the feature map can be calculated as follow:
- individual linear filters can be learned to detect different variations of a same concept.
- However, having too many filters for a single concept imposes extra burden on the next layer
- in the recent maxout network, the number of feature maps is reduced by maximum pooling over affine feature maps——which is capable of approximating any convex functions
- NIN is proposed from a more general perspective
Network In Network
MLP Convolution Layers
it is desirable to use a universal function approximator for feature extraction of the local patches
we choose multilayer perceptron instead of radial basis network in this work for two reasons
- MLP is trained using back-propagation
- multilayer perceptron can be a deep model itself
this new type of layer is called mlpconv in this paper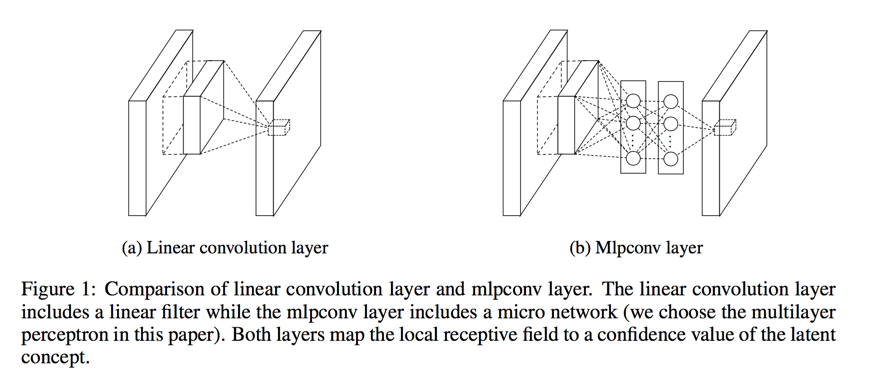
The cross channel parametric pooling layer is also equivalent to a convolution layer with 1x1 con- volution kernel
compare to maxout
mlpconv layer differs from maxout layer in that the convex func- tion approximator is replaced by a universal function approximator
Global Average Pooling
the fully connected layers are prone to overfitting
we propose another strategy:
- generate one feature map for each corresponding category of the classification task in the last mlpconv layer
- take the average of each feature map
- the resulting vector is fed directly into the softmax layer
advatage:
- more native to the convolution structure by enforcing correspondences between feature maps and categories
- no parameter to optimize in the global average pooling thus overfitting is avoided at this layer
Network In network structure
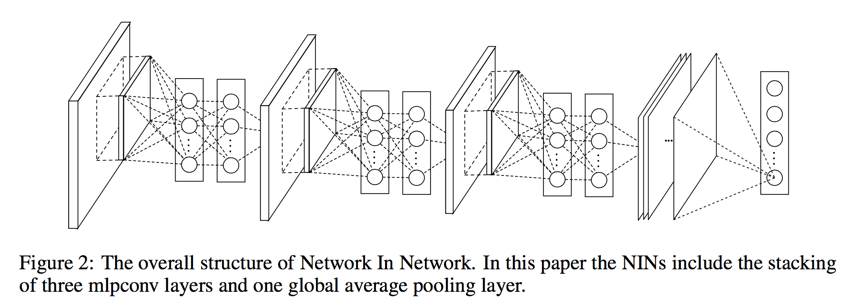
Experiments
- batch_size: 128
- learning rate is lowered by a scale of 10
CIFAR-10
composed of 10 classes of natural images with 50,000 training images in total, and 10,000 testing images

CIFAR-100
but it contains 100 classes

Street View House Numbers
composed of 630,420 32x32 color images
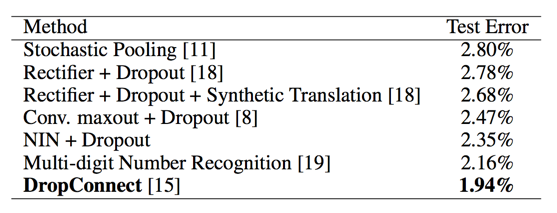
MNIST
consists of hand written digits 0-9 which are 28x28 in size. There are 60,000 training images and 10,000 testing images in total

Global Average Pooling as a Regularizer

Conclusions
- use multilayer perceptrons to convolve the input
- a global average pooling layer as a replacement for the fully connected layers in conventional CNN