总结
- 本文提出了一个对于GAN的另外的应用场景——使用模型的中间结果作为特征
- 首先提出了新的generator结构,在之前CNN的基础上做了优化;其中的trans_conv/deconv/反向卷积结构其实是等同于CNN中的反向传播求梯度过程,是在深层传来的梯度值得基础上左乘卷积核矩阵,详见此处
- 在训练GAN的时候提出了解决generator记忆样本问题的方法:将训练样本降维然后建hash表,对于所有生成出来的在hash表中有碰撞的样本全都舍弃
- 对于模型表达能力的证实
- 在无监督训练中,作为特征提取器超过了KNN的效果(CIFAR-10数据集)
- 在有监督训练中,作为特征提取器达到了最好的效果(SVHN数据集)
- 对于模型可视化的探索:
- 在z中做差值,可以观察到生成图像的渐变
- 对D中的filter做可视化
- 操作z以达到特定目的:
- 指定取消某个物体
- 通过z的向量运算,产生图像的运算
Abstract
in this paper we hope to help bridge the gap between the success of CNNs for supervised learning and unsupervised learning
Introduction
- We propose that one way to build good image representations is by training Generative Adversarial Networks (GANs) (Goodfellow et al., 2014), and later reusing parts of the generator and discriminator networks as feature extractors for supervised tasks
- We use the trained discriminators for image classification tasks, showing competitive per- formance with other unsupervised algorithms
- We visualize the filters learnt by GANs and empirically show that specific filters have learned to draw specific objects.
- We show that the generators have interesting vector arithmetic properties allowing for easy manipulation of many semantic qualities of generated samples
Related Work
representation learning from unlabeled data
- clustering on the data
- hierarchical clustering of image patches (Coates & Ng, 2012) to learn powerful image representations
- auto-encoders (convolutionally, stacked (Vincent et al., 2010), separating the what and where components of the code (Zhao et al., 2015), ladder structures (Rasmus et al., 2015)) that encode an image into a compact code
generating natural images
- non-parametric
- often do matching from a database of existing images, often matching patches of images
- parametric
- Generative Adversarial Networks (Goodfellow et al., 2014) generated images suffering from being noisy and incomprehensible
- A laplacian pyramid extension to this approach (Denton et al., 2015) showed higher quality images, but they still suffered from the objects looking wobbly
- A recurrent network approach (Gregor et al., 2015) and a deconvolution network approach (Dosovitskiy et al., 2014) have also recently had some success
visualizing the internals of CNNs
In the context of CNNs, Zeiler et. al. (Zeiler & Fergus, 2014) showed that by using deconvolutions and filtering the maximal activations, one can find the approximate purpose of each convolution filter in the network
Approach and Model Architecture
three core changes:
- all convolutional net instead of spatial pooling functions
- trend towards eliminating fully connected layers on top of convolutional features
- Batch Normalization
- Use ReLU activation in generator for all layers except for the output, which uses Tanh
- Use LeakyReLU activation in the discriminator for all layers
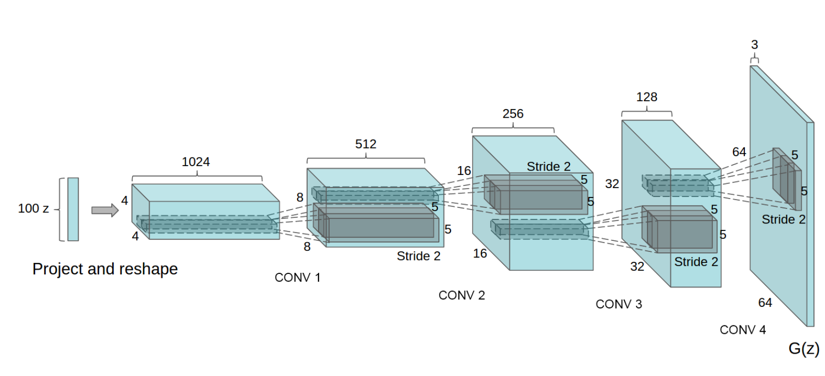
Details of adversarial training
trained on three datasets:
- Large-scale Scene Understanding(LSUN)
- Imagenet-1k
- Faces dataset
settings:
- no pre-processing beside scaling to [-1, 1]
- mini-batch SGD with size 128
- weights initialized from a zero-centered Normal distribution with standard deviation 0.02
- LeakyReLU, the slope of the leak was set to 0.2 in all model
- Adam optimizer with tuned hyperparameters(set $\beta$ to 0.5)
- learning rate is 0.0002
LSUN


dedeplication
To further decrease the likelihood of the generator memorizing input examples, We fit a 3072-128-3072 de-noising dropout regularized RELU autoencoder on 32x32 downsampled center-crops of training examples
The resulting code layer activations are then binarized via thresholding the ReLU activation which has been shown to be an effective information preserving technique
if there is a hash collision then we remove it
Faces
We run an OpenCV face detector on these images, keeping the detections that are sufficiently high resolution, which gives us approximately 350,000 face boxes
Imagenet-1k
train on 32 × 32 min-resized center crops
Empirical Validation of DCGANs Capabilities
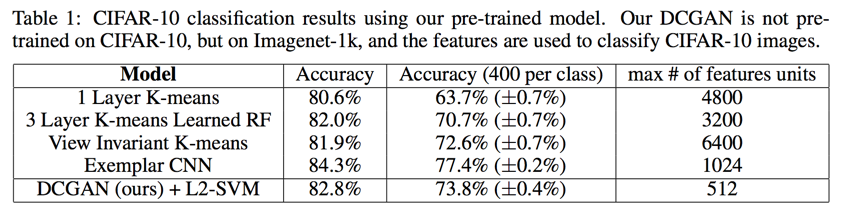
classifying CIFAR-10 using GANs as a feature extractor
One common technique for evaluating the quality of unsupervised representation learning algo- rithms is to apply them as a feature extractor on supervised datasets and evaluate the performance of linear models fitted on top of these features
DCGANs achieves 82.8% accuracy, out performing all K-means based approaches 82.0% while the discriminator has many less feature maps(512 at most)
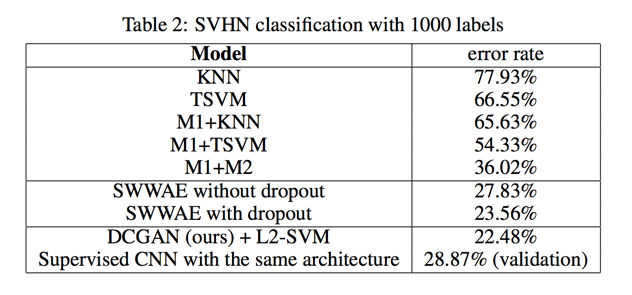
classifying SVHN digits using GANs as a feature extractor
On the StreetView House Numbers dataset, we use the features of the discriminator of a DCGAN for supervised purposes when labeled data is scarce
achieves state of the art at 22.48% test error
Investigating and Visualizing the Internals of the Networks
both is nearest neighbors and log-likelihood metrics is poor
walking in the latent space

visualizing the discriminator features

manipulating the generator representation
forgetting to draw certain objects

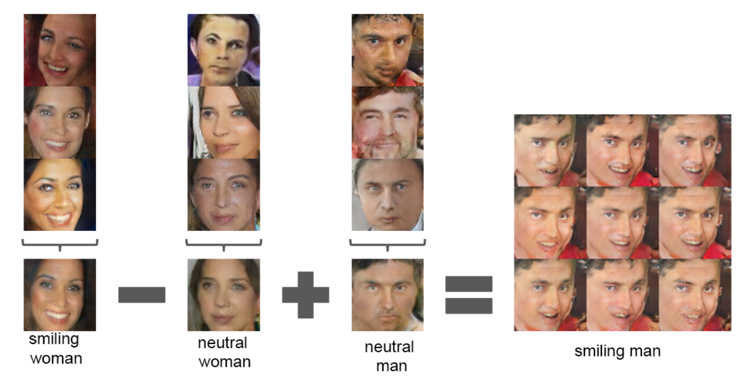
vector arithmetic on face samples
Experiments working on only single samples per concept were unstable, but averaging the Z vector for three examplars showed consistent and stable generations that semantically obeyed the arithmetic
Conclusion and Further Work
we noticed as models are trained longer they sometimes collapse a subset of filters to a single oscillating mode