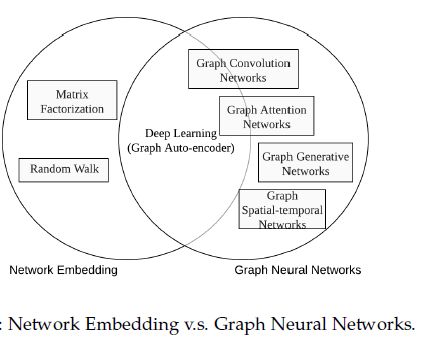
总结
通过本篇文章,笔者第一次接触到Pair-wise训练
其实总体来看实现思路非常简单,就是通过两个point分别过模型inference然后对结果做差,将diff当做一个样本在另外一个样本之前(记$ahead_{ij}$)的对数几率,将这个几率再过一遍Sigmod函数,就得到了概率值(记$P(ahead_{ij})$)
文章很大的篇幅,证明了做差之后结果是可导的,这对模型训练至关重要,但被我可耻的跳过了……
大篇幅的证明 + 只改动几行代码的实现(对于自动求导的神经网络来说是这样的)和之前读的W-GAN感觉很像
不管怎么说Pair-wise训练算是摸到点门道了
Introduction
cast the ranking problem as an ordinal regression problem is to solve an unnecessarily hard problem, we don’t need to do this
we call the resulting algorithm, together with the probabilistic cost function we describe below —— RankNet