0%
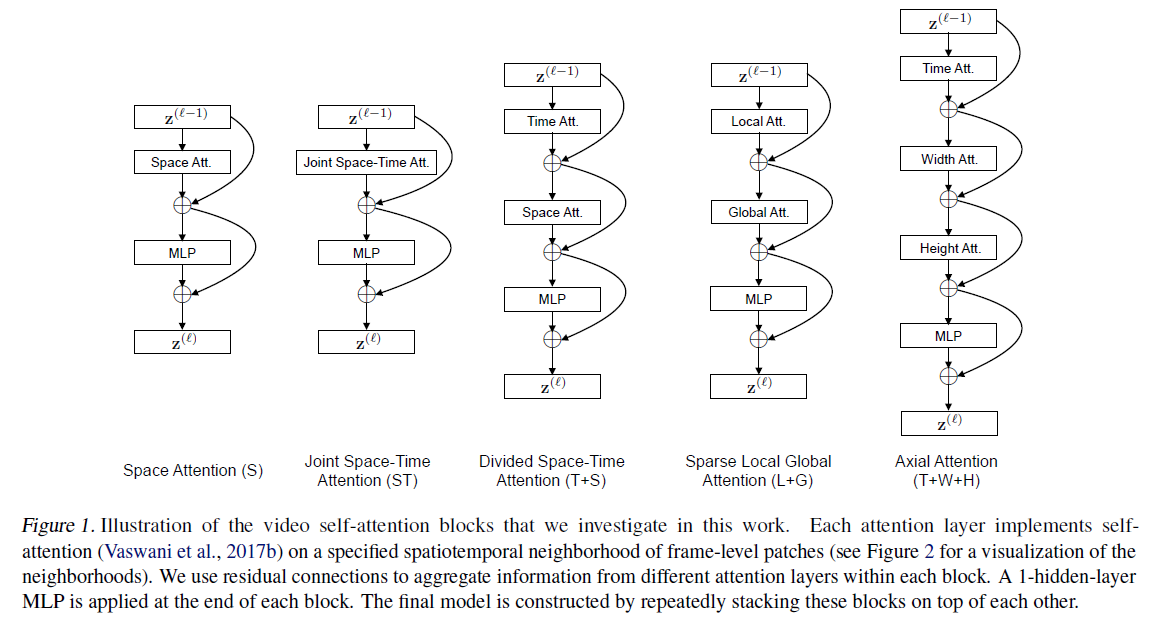
朴素时空融合方案
Deep Video
- 使用大规模数据集通过CNN进行训练,划分了融合框架
- Late只是在最后输出层进行了结合
- Early是在channel维度就把输入揉在一起了
- Slow是前两者方式的结合
- 实验效果来看差别不大,比不过手工特征
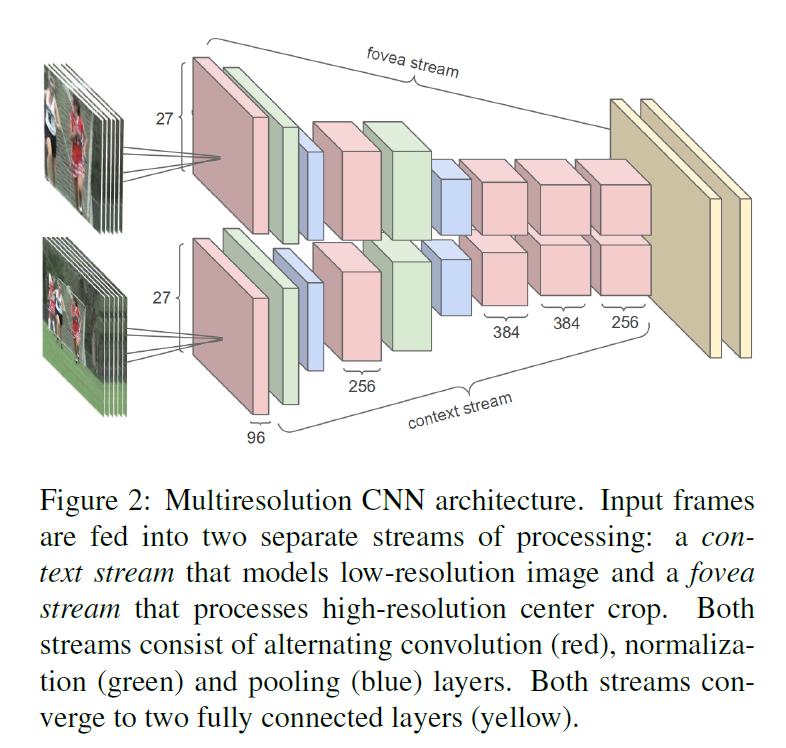
- 提出了sports 1M 数据集
- 尝试了多分辨率网络,在图片里面比较好用的方式,可以算是一种早期的先验注意力机制,最终效果也是不如手工特征
光流方案
Two Stream
Beyond Short Snippets
- 想做长时间跨度的视频建模就要解决多帧建模的问题
- 尝试各种pooling,效果其实都差不多,conv pooling效果稍好一些
- 尝试了LSTM(5层)融合效果提升也比较有限
- 网络整体结构是在双流网络上改的,但是效果提升并没有多少
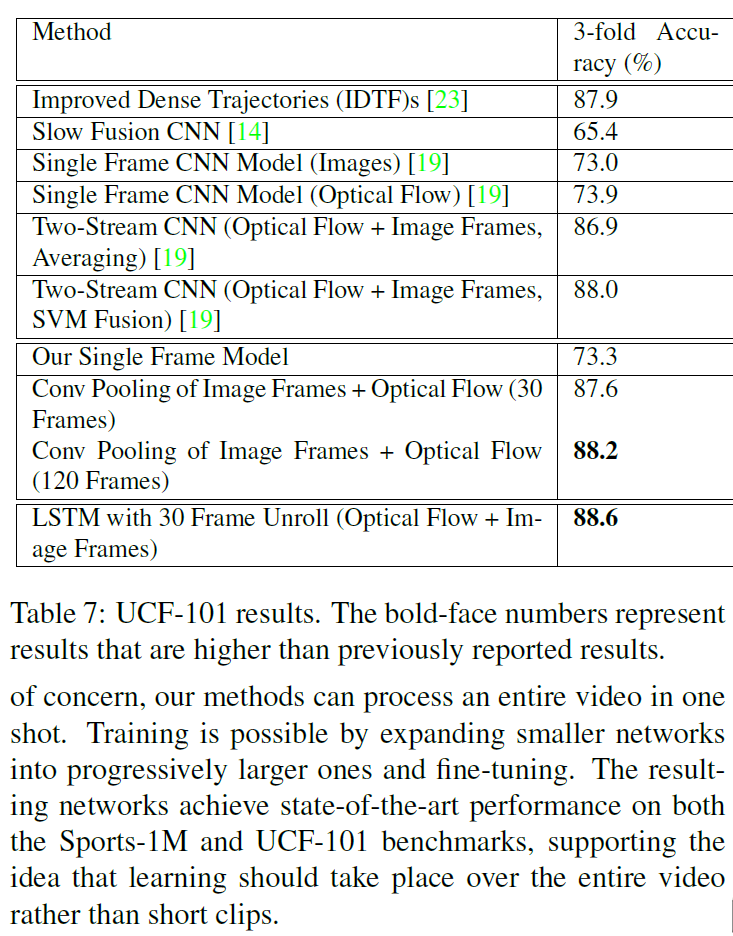
- 可能是这个数据集本身都是比较短的短视频,没有给LSTM表现的空间
Convolutional Two-Stream Network Fusion for Video Action Recognition
- 详细的讲解了如何去做fusion
- spatial fusion:指双流网络中的两个网络如何在空间上对齐融合。给了几种融合方式,1* 1 conv 融合方式效果最好
- how to fusion:主要讨论什么时候融合的问题。通过消融实验试出来的如下图两种方式
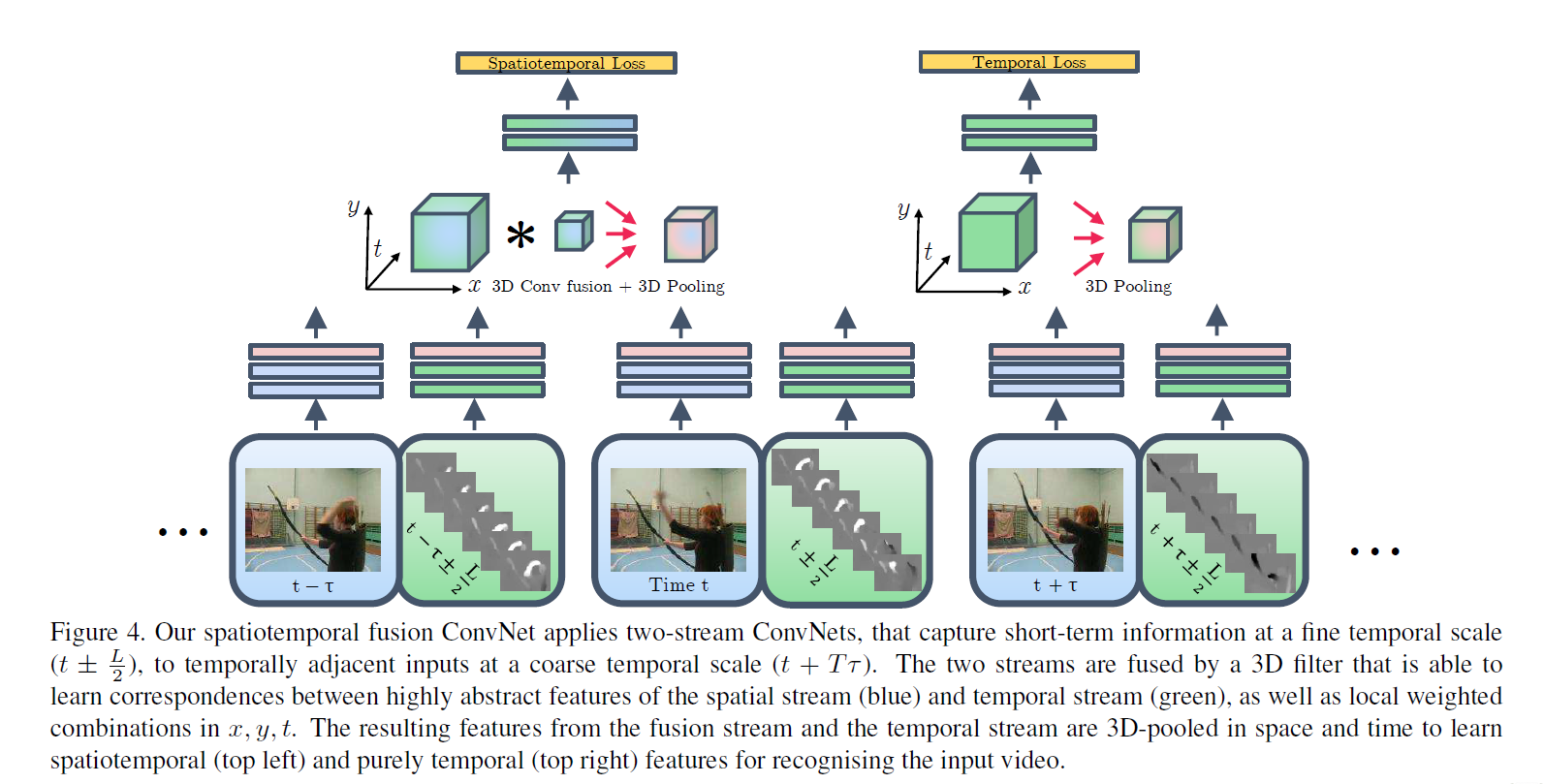
- temporal fusion 如何在时间维度去把他们合并起来。本文尝试了两种方式,3D pooling和先做3Dconv 再做 3D pooling
- 综合起来设计出的网络是有两个分支,一个时空分支一个时间分支,用两种loss去做训练,推理的时候是两个头加权平均
Temporal Segment Networks
- 网络的想法很简单,多段视频理解,走多遍TSN,然后融合
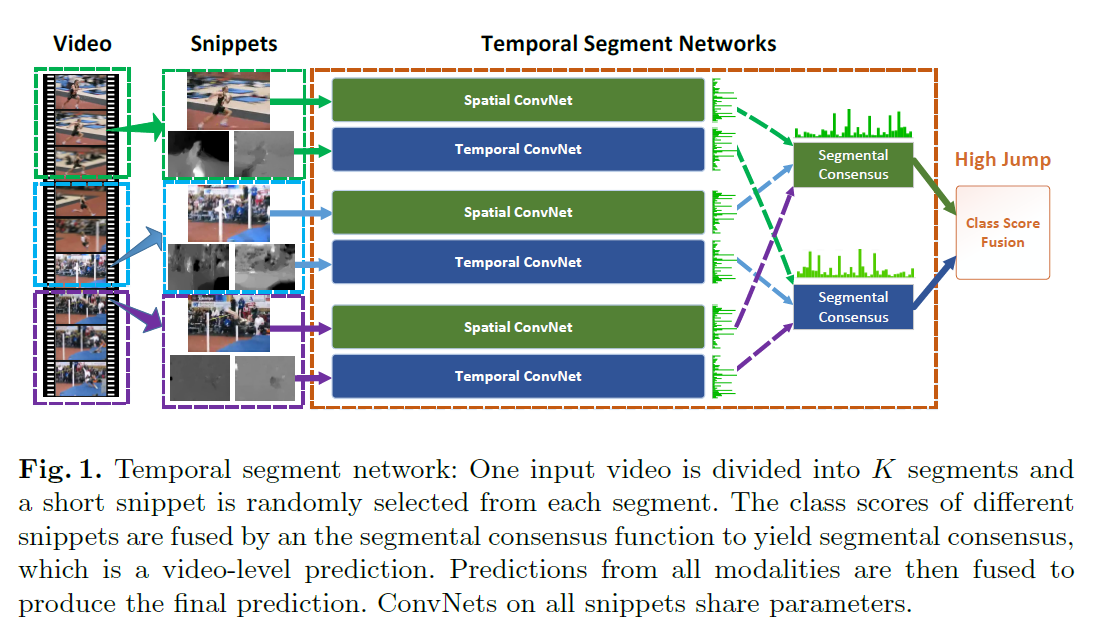
- 融合的方式也有很多
- 如果片段相关可以做加权融合
- 如果不相关可以用LSTM(或者transformer?)
- 训练技巧,涨点很明显
- 光流网络预训练因为数据集比较小,不太好训。作者把imagenet的预训练参数迁移了过来,改变第一层的参数(3->avg 变为 1 -> 复制20遍 -> 20)效果挺好
- Partial BN:传统BN在视频领域因为数据集太小有可能会带来过拟合的问题。所以作者在训练BN的时候只训练第一层,剩下的都冻住,效果比较好
- 数据增强:
- corner cropping:注重边角的裁剪,其实和five crop一个意思
- scale-jittering:改变长宽比去做裁剪,在【256,224,192,168】中随机选两个当做长和宽
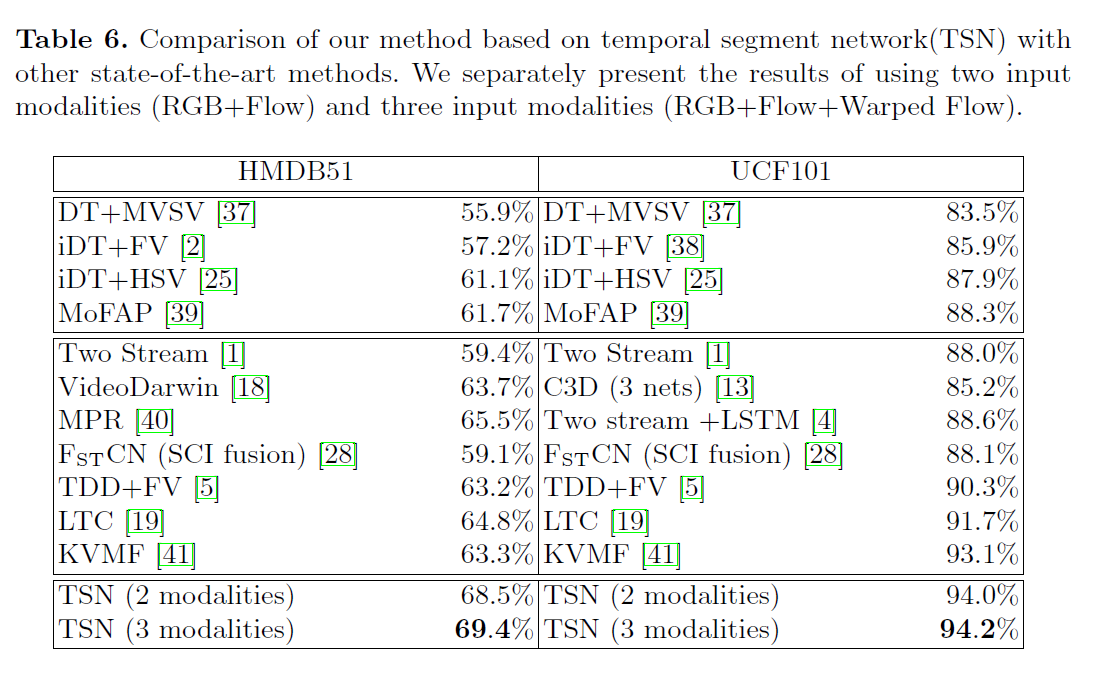
3D卷积方案
- 光流整体耗时比较长,还是被新的方案所取代
- 抽光流(0.06s/frame -> 15 fps)没法应用在很多实时任务场景上
- 但光流特征本身还是很有效,在现有模型上可以继续涨点
C3D

- 整体网络结构就是一个3D版本的VGG
- 网络的整体效果并不突出,没有同时期其他工作效果好,但是作者把卖点放在了用网络抽取特征上
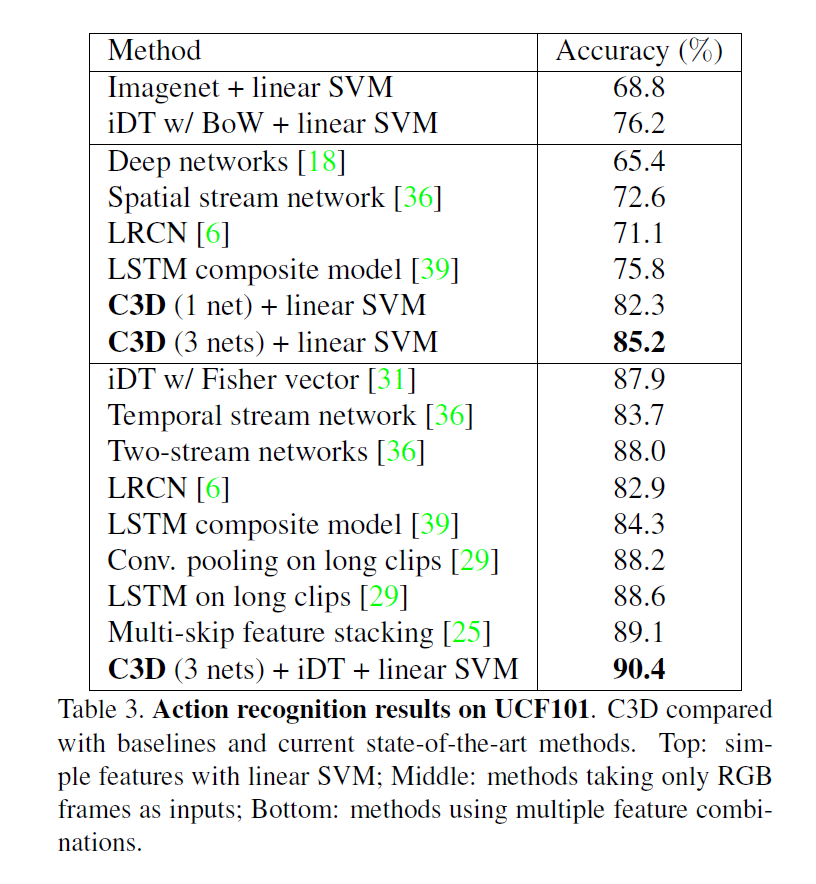
I3D
Non Local
- 受到transformer启发,应用self attention操作,提出了non local算子
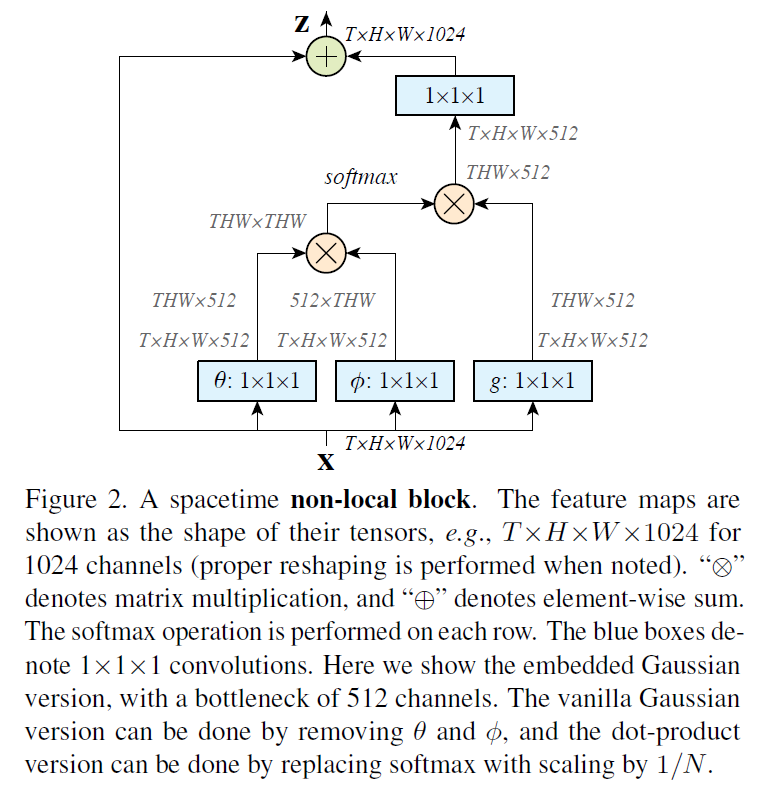
- 消融实验
- 自注意力方式:点乘最好
- 如果只加一个non local算子的插入位置:加在前面效果好但计算贵
- 加多少个算子:越多越好,本文是10个
- 时空有没有必要都算自注意力:有
- 是否对长距离视频有效:是
- 效果超过光流I3D
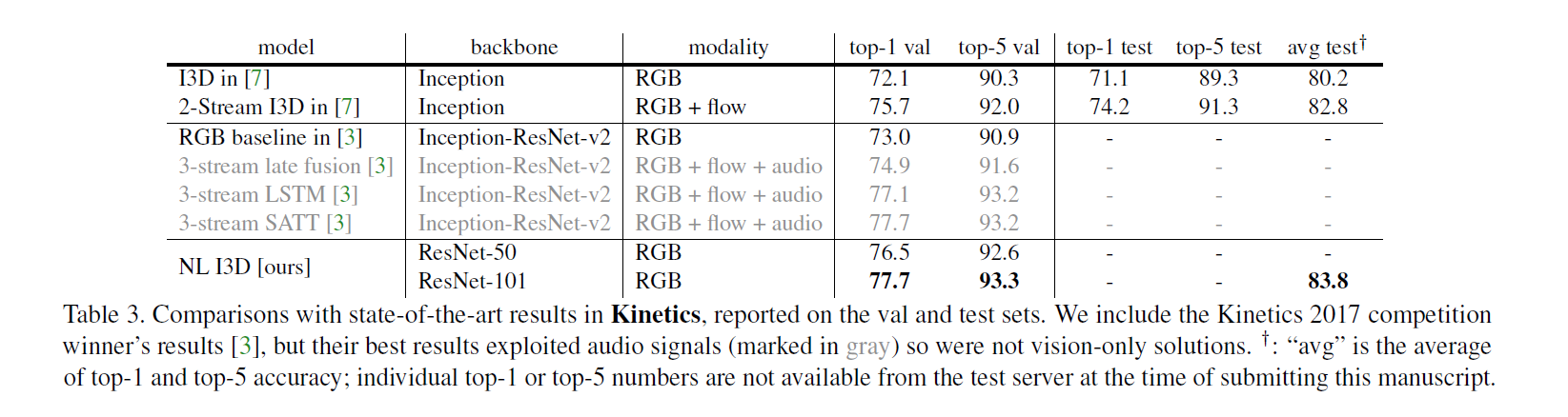
R(2+1)D
- 新版的Deep Video 探索2D卷积的融合方式去处理视频
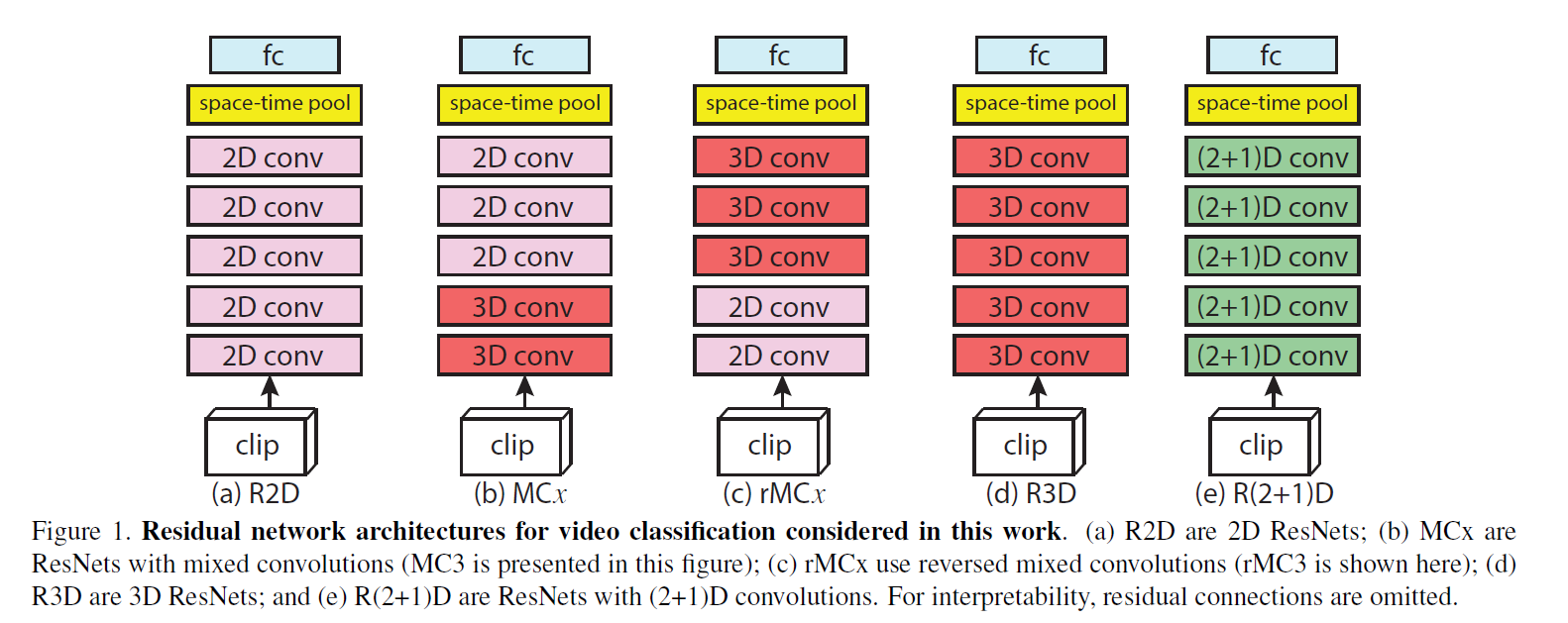
- R(2 + 1)D就是把时空的卷积操作分成两个卷积来做(有点像深度可分离卷积?)
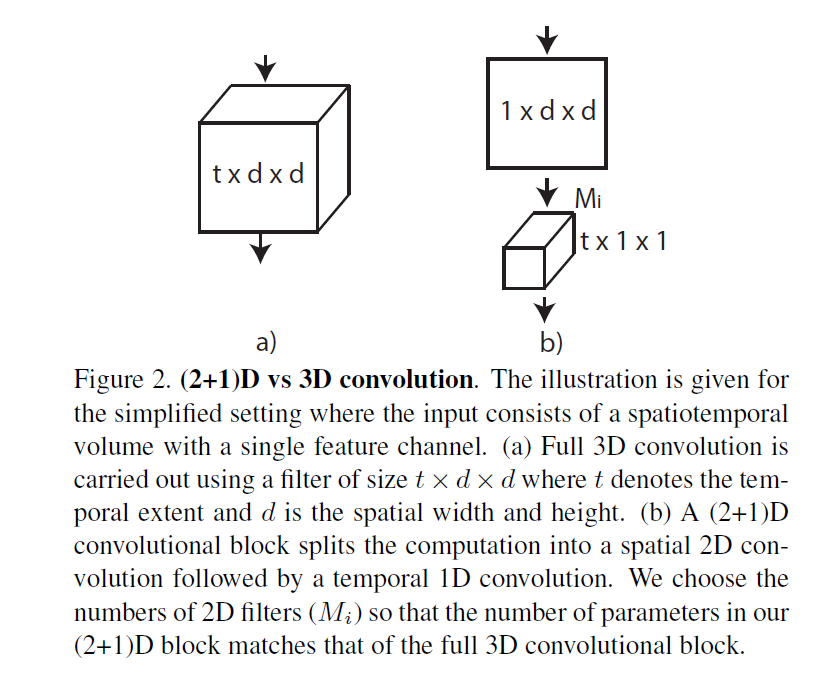
- 这种结构设计是可以降低模型的训练难度,最后的实验效果并没有很突出,可能是受输入数据的尺寸影响
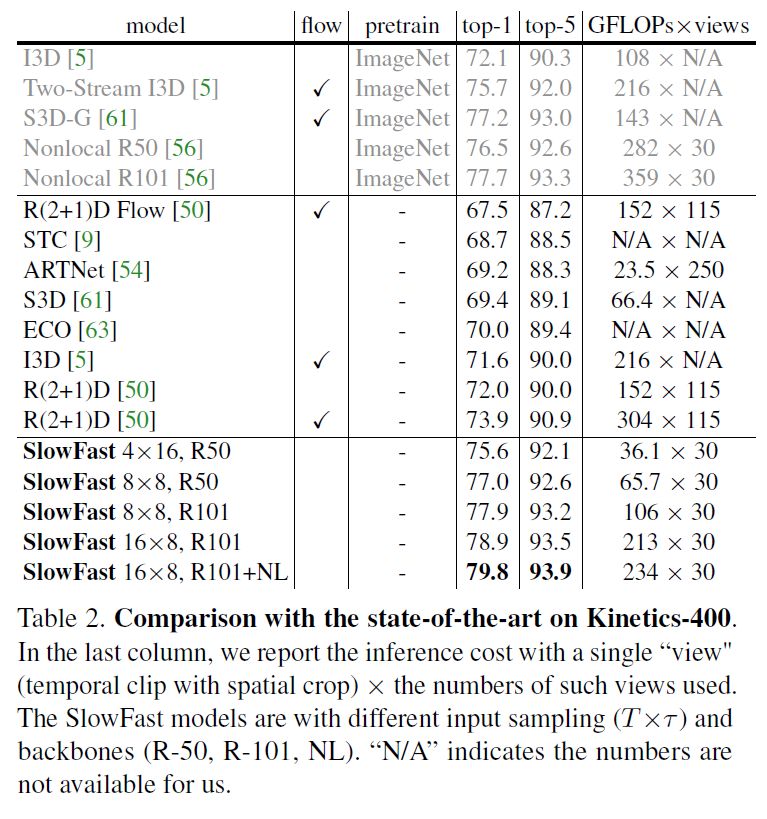
SlowFast
- 灵感来源于人的视觉神经系统,两种细胞一种是p细胞一种是m细胞,p细胞处理静态,m细胞处理动态
- 所以网络设计也分成两部分:
- 一块输入的帧率低,处理静态信息,又因为p细胞占比高,所以用大模型去处理,基本等同于I3D
- 另一块输入的帧率高,处理时序信息,模拟m细胞,用小模型去处理(主要是channel数量少)
- 两分支没有时序下采样
- 两个分支还有中间层连接交互
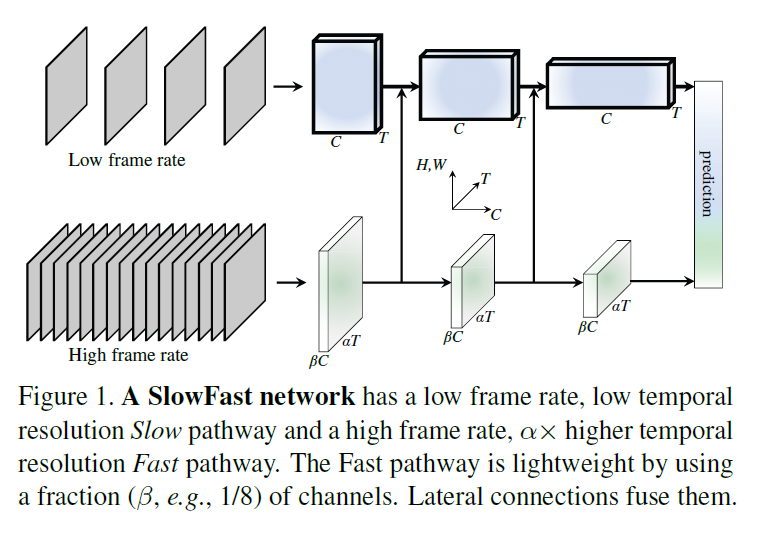
- 类似于R(2 + 1)D 把时间和空间的自注意力机制分开算