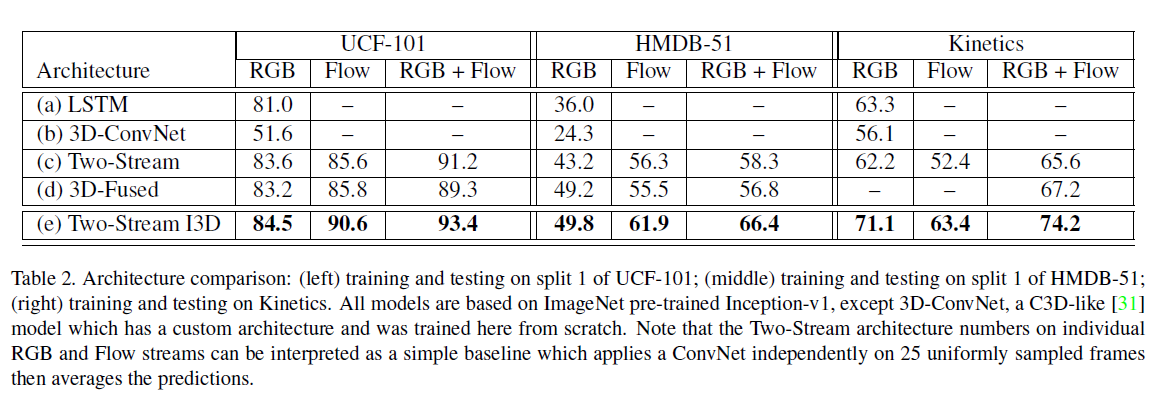
0%
总结
- 提出了一个新模型I3D和一个新的数据集Kinetics,这个数据集基本是动作识别必做的一个数据集。
- 做这个数据集主要是因为主流的数据集太小了,区分度小。并且这个数据集每个视频都来自于一个独立的视频片段,标注的非常好。
- 所谓I3D是指inflated 3D,特点是把已经设计好的2D网络扩展成3D的形式然后应用在视频上面。本文的模型还加上了光流
- 对比传统方式
- CNN + LSTM:后验效果不好,这个方向基本没有后续了
- 3DCNN:参数量过于巨大且数据量小,无法做很深的建模,比如c3d
- 双流:这个东西作者认为有用,在本文也拿过来用了
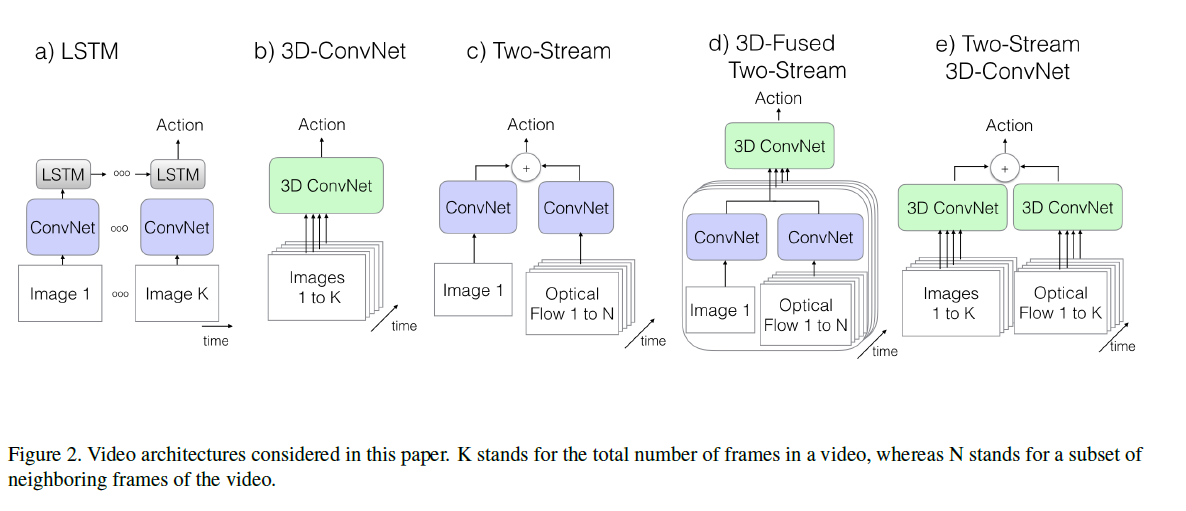
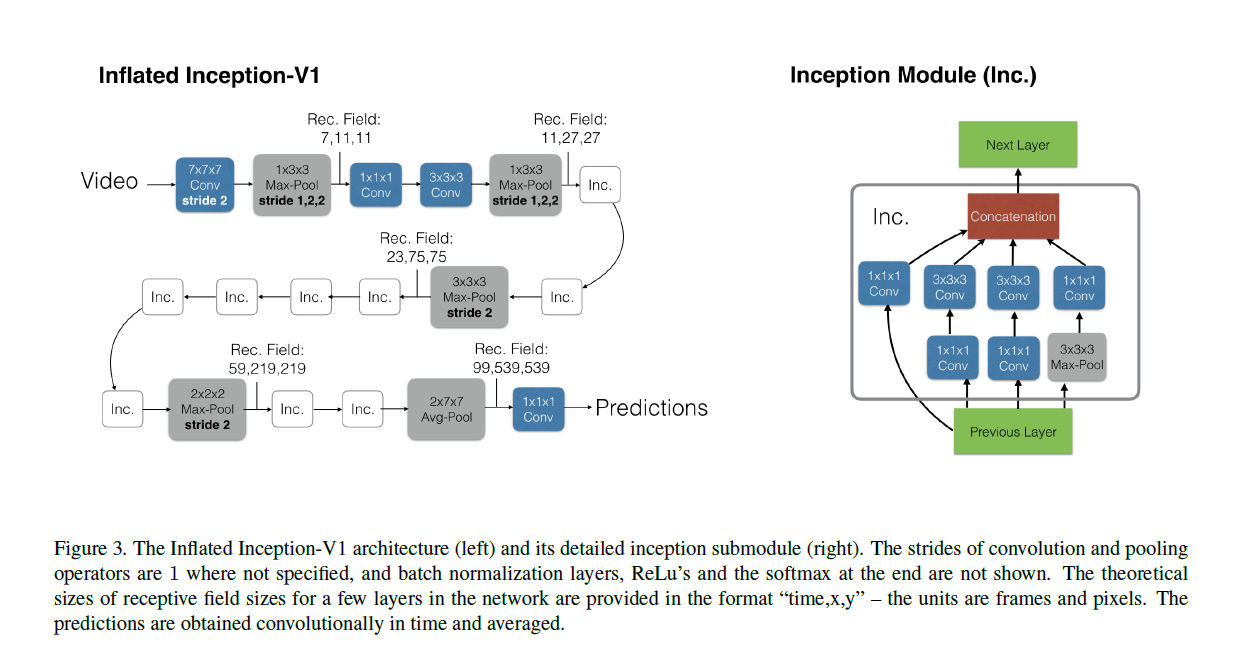
- 启用inflated操作后可以直接利用效果好的2D网络作为初始化模型,本文使用的inceptionV1,(不用resnet是因为在视频领域后验效果不如,但是后面的non local是用resnet来做的,所以后面再说I3D就是指resnet版本的)
模型
- 如何做inflat?这个就是简单直接,遇到一个2D卷积核就变成3D的卷积,pooling也是同样的方法
- 如何初始化参数?其实就是直接把参数在时间维度上复制,达到膨胀的效果。然后为保持输出一致,需要 rescaling,将每个filter的参数值除以时间维度N
- pooling层有些特殊,前面两层pooling没有做时间维度的下采样,后面才开始。近期的一些工作是完全不做任何时间上的下采样的,可能的原因是给到的帧数本来就很少
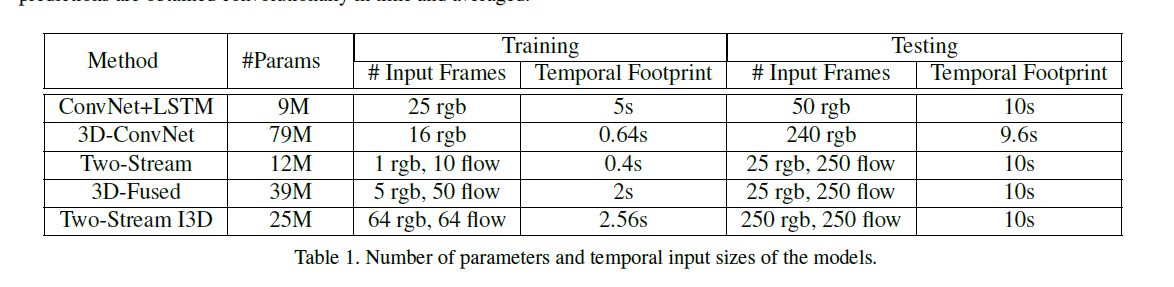
实验