0%
总结
- 名字有点说法,Bidirectional Encoder Representations from Transformers,简称BERT和之前所引用的ELMo都是芝麻街主人公的名字……
- 和前作对比:
- 相比较于ELMo的RNN架构,BERT迁移到下游任务相对简单。ELMo这种方式属于基于特征的下游任务应用方式,将预训练好的模型输出当做额外的特征应用到下游任务中去
- 相比较于GPT,BERT是双向信息建模。GPT的应用下游任务方式属于微调,在不同的任务上重新训练已有的模型。
- 训练目标
- 单向信息建模在语义表征任务上其实有一定局限性所以作者想要加入双向信息去做建模,使用了MLM目标去建模,这个东西是一个叫做Cloze的1953年的文章提出来的
- 还使用了预测下一个句子的任务。因为有些任务比如问答都是要处理两个句子的
- 在挺多(11个)的任务上表现良好,这里其实证明了两个事情
- 双向信息很有用
- 大量的没有label的数据比少量labeled的数据效果更好,这个思想也应用在了视觉领域
模型
- 模型训练分为两个步骤:预训练(无监督)和微调(下游有监督数据)
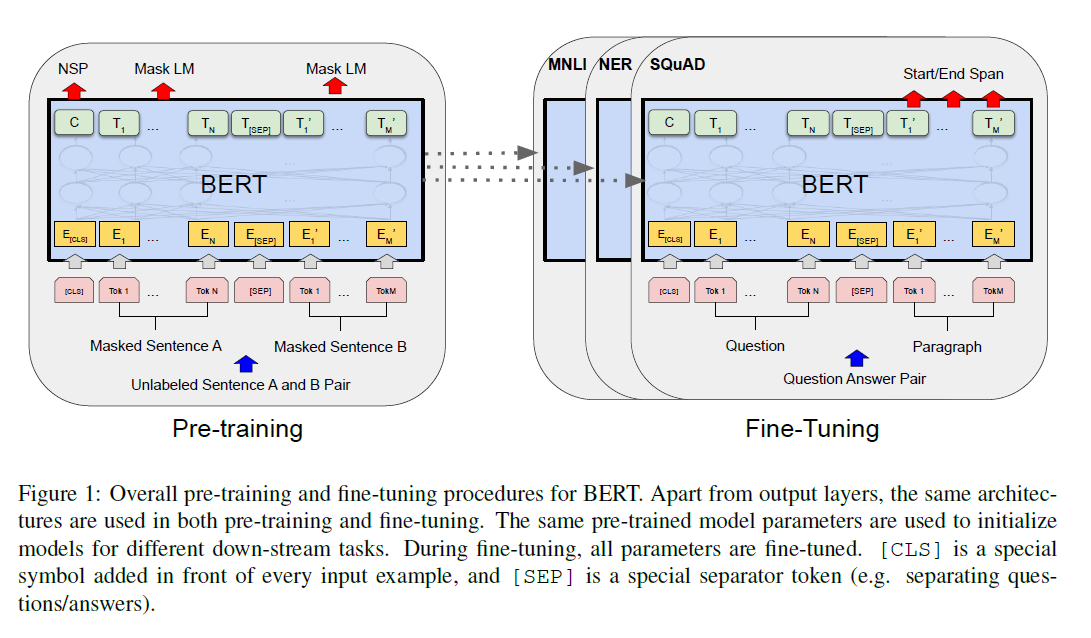
- 模型结构是transformer的Encoder,没有做任何改动
- 作者用了两个版本的BERT模型,如果有多头注意力的话那么整体的参数量是:词典长度 H + L H^2 * 12
- 切词方法没有用空格而是WordPiece方法(用词根代替低频词),把词表的规模降下来,把学习的重心调平
- 句子的第一个token是[CLS]用以代表整个句子的信息。如果输入是两个句子的话中间用[SEP]分开,此外在输入中加入Segment Embedding区分两个句子

训练
- MLM任务
- 只用于预训练
- 15%的概率随机对一个词(非特殊词)进行处理
- 由于微调不用这个步骤,所以会产生不一致问题,所以做的策略稍微复杂一些
- 80%概率表示为[MASK]
- 10%概率替换为其他词
- 10%啥都不干(只是标记一下,要对这个词做预测)
- NST任务
下游任务
- GLUE
- General Language Understading Evaluation
- 句子多分类,用CLS词源
- SQuAD
- Stanford Question Answering Dataset
- 给一段话和一个问题,把答案找出来
- 预测每个次元被当做开头和结尾的概率
- SWAG
- Situation With Adversarial Generations
- 判断两个句子的关系
实验
- 对NSP和双向都做了消融实验,效果会有下降
- 下游任务优先使用finetune的方式而不是当做特征去用的方式