0%
总结
- 作者都来自Google,均等贡献,比较少见
- 在seq2seq问题中,没有用循环和卷积的架构,而只依赖注意力机制,在一些机器翻译的工作中取得了很好的结果(后来这个工作出圈了,在包括CV在内的所有任务都可以用)。训练也不太费事,在8个GPU上训练了3.5天。
- 在结论部分有源码(应该放在摘要部分?)
- 虽然文章标题强调了Attention,但是在后面的消融实验中验证其实其他部分也是很重要的,有个文章叫做Attention is not all you need专门讨论这个事情,也是Google的
- 在CNN和RNN之外提出了一个新的模型架构,并且几乎可以用这个架构处理所有模态的事情,堪称深度学习界的秦始皇
概述&背景
- 现有方式的缺点
- 传统RNN的缺点是只能把输入从左往右挨个遍历,通过隐藏状态去传递信息,难以并行(虽然做了一些改进但是没有根本解决这个问题)
- 卷积方式对于离的比较远的像素的相关性处理的不好(需要多层卷积);但是也提到了卷积好的一面:可以做多个输出通道,所以也就引出了多头注意力机制
- 自注意力机制之前已经有人提出,并不是创新
模型
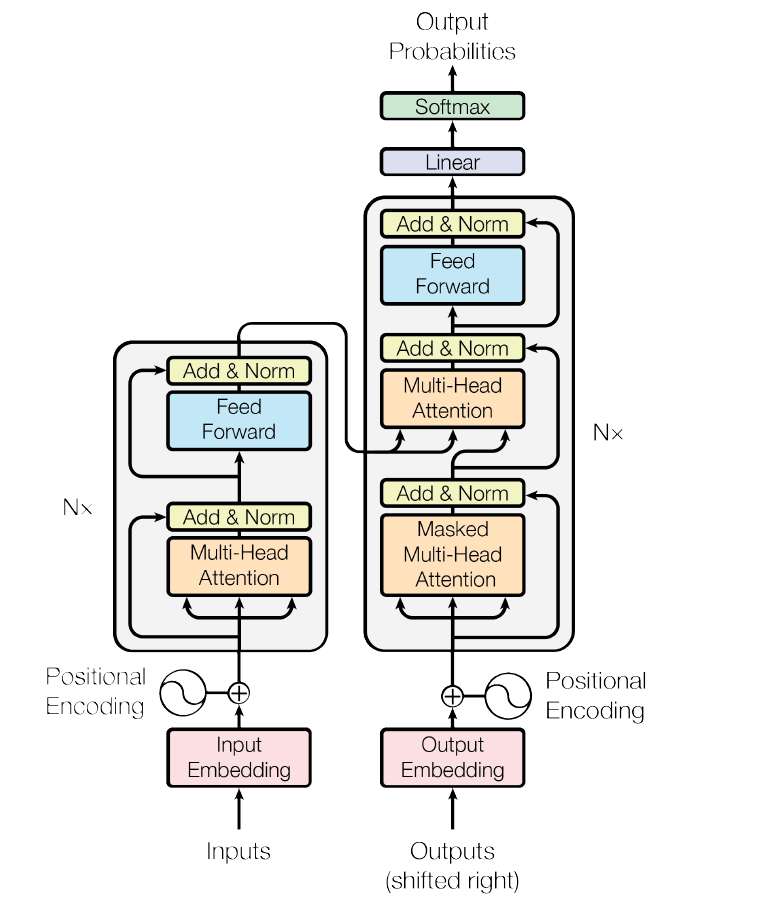
- 目前所使用的是encoder-decoder架构:encoder将原始输入变为n维向量,decoder再从n维向量变为m维向量。其中encoder是一次看一整个句子,decoder是one by one的生成(自回归)
- Transformer也是用的这个架构:
- 先把输入embedding化
- 加positional bias
- 过N个Encoder模块,本文N = 6,维度512
- 过注意力机制和MLP
- 带残差
- 过Layer Norm
- 再过N个Decoder模块
- 过Masked注意力 + 注意力 + MLP,其中注意力层的输入混合了Encoder的输出
- 带残差
- 过Layer Norm
- 最后过一层Linear然后softmax获得输出
- 为啥用LN不用BN?
- BN是Batch维度对每一维特征进行归一化,即减去均值除以标准差。预测的时候用的是全局值。通过两个变量$\lambda$和$\beta$来控制归一化的程度
- LN是对每个样本做,而不是对每个特征做
- 主要的原因是在一个时序的样本里面,样本的长度可能会发生变化
- BN是有多少组特征就有多少组结果,LN是有多少的样本就有多少组结果
- Decoder为啥要用带Masked的注意力层?
- 因为解码器在使用的时候是不能看到完整的输入的,在预测t时刻的词的时候只能看到t时刻之前的输入,所以要加上掩码(将QK的值置为一个非常大的负数),使得训练和预测的时候用起来是一致的
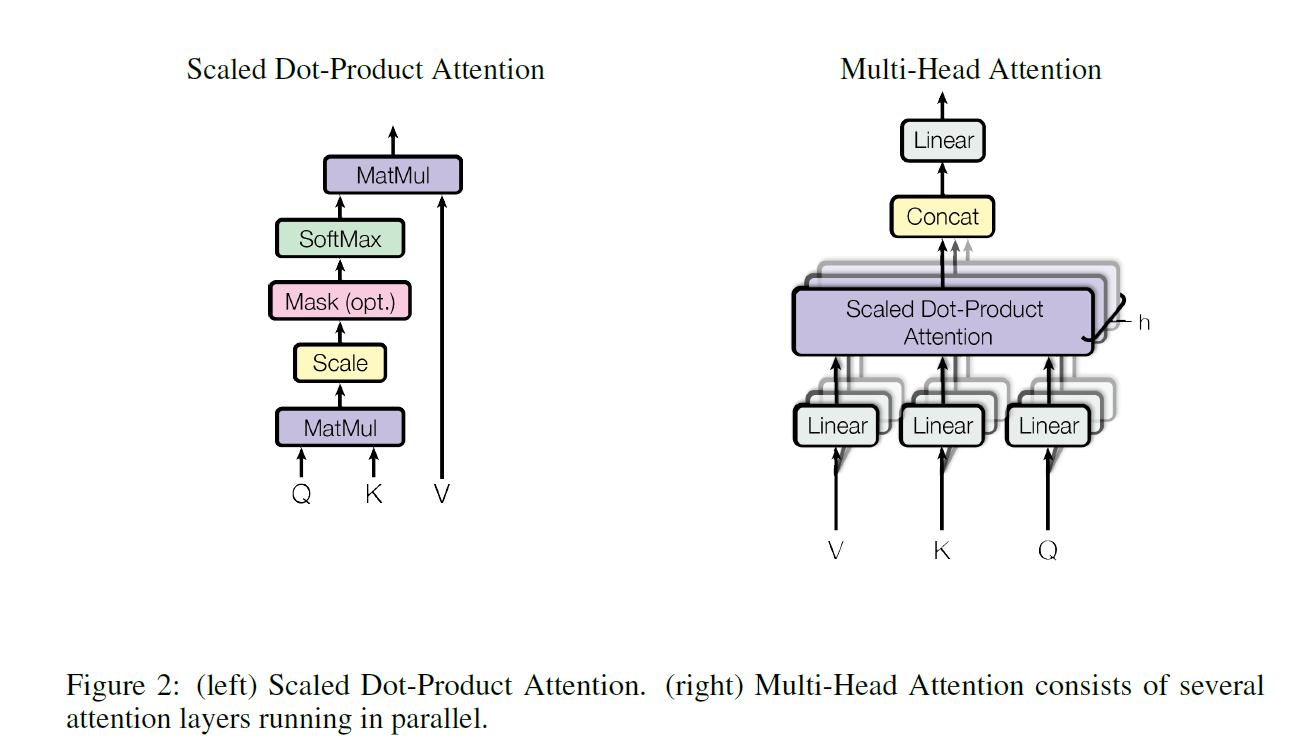
- 关于注意力机制
- 注意力机制是通过QKV矩阵去通过QK的相似度去计算V的加权和,本文所使用的的注意力机制是Multi Head的Scaled Dot-Product Attention。
- Scaled Dot-Product Attention其实是最简单的一种attention机制,$Attention(Q,K,V) = softmax(\frac {QK^T} {\sqrt {d_k}})V$。
- multihead其实就是多组这样的注意力函数的叠加,借用了CNN中通道的思想,具体实现是先把QKV都映射到一个比较低的维度(等于原始维度除以头的数量),这个投影的层是可以学的,最终的结果是所有头结果的concat到一起。本文用的头的数量时8个
- 常用的注意力机制还有一种是加项注意力机制,用以处理Q和K维度不等的情况
- 除以$\sqrt {d_k}$作为温度变量,当$d_k$比较大的时候算出来的$QK^T$结果通常也比较大,softmax容易向头部集中,梯度也比较小,不利于网络的训练
- 注意力层的应用
- Encoder中的注意力机制:三个输入,QKV,这三个是同样的东西复制过来的,即所谓自注意力
- Decoder中的Masked注意力:和Encoder中的一样,只是加了时间掩码
- Decoder中的第二层注意力:KV来自于Encoder的输出(KV是一样的),Q是Masked注意力层的输出
- 前馈层是单隐层MLP,中间维度把512变为2048,然后再变回去,维度的伸缩是在最后一个维度即词的维度进行,因为给到MLP的输入已经是经过注意力层的有整个序列信息的数据。
- input embedding、output embedding和softmax前面的embedding层是共享权重的,方便训练。并且把embedding都乘上了一个$\sqrt {d_k}$,为了后面和position embedding相加的时候在一个量级上
- position embedding是一个融合sin和cos函数的一个embedding,维度也是512
训练细节
- 优化器使用Adam
- 学习率是通过策略固定(Adam对于学习率不敏感)
- 大量使用了Dropout(10%)
- 使用了label smooth(0.9)