结论
- 这个文章花了很多的篇幅&作者花了很多的精力去做把网络切开放在两块卡上这个事情,现在看来反而不是那么重要。近些年BERT等大模型越出越多,要回到切模型的方式上来
- 深度很重要,去掉之后有掉点2%(但其实这个结论并不是很置信)
- 有标注数据很重要,这使得以后很长一段时间的深度学习都比较关注有监督学习。一直到BERT的出现才把研究的视角拉回到无监督学习上面来
- 已经开始用神经网络里面的向量来搜索图片了。神经网络里面的向量在语义空间里面的表现很好

介绍
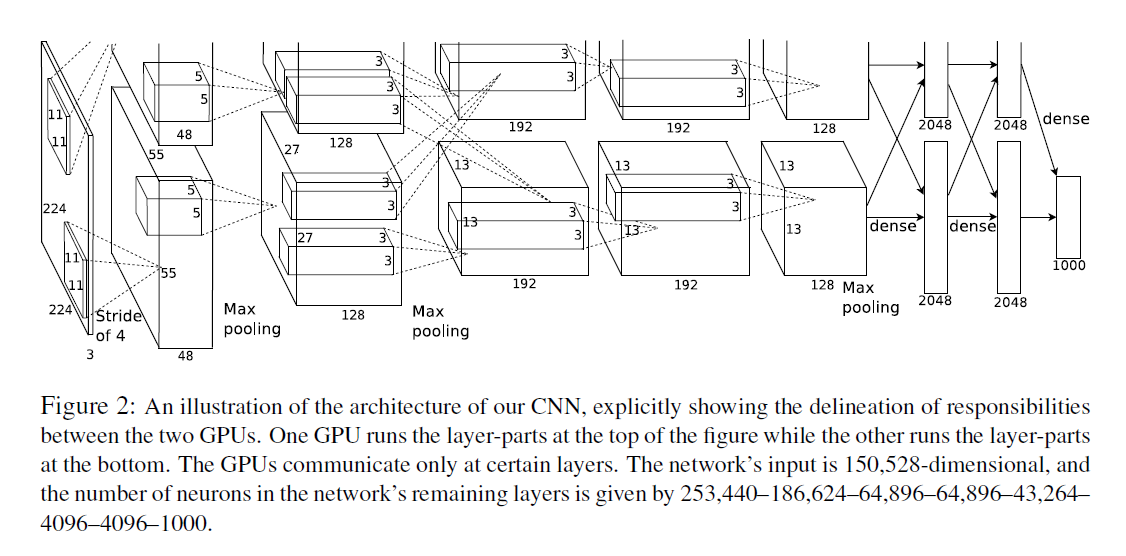
- 因为受限于显存大小,是把网络切开来放到里面,有很多工程上的工作,这个对于最终的结果不太重要
- 不抽低阶特征(SIFT之类的),直接在原始的pixel上面做,是一个end to end模型
结构
- ReLu很重要,训练速度快
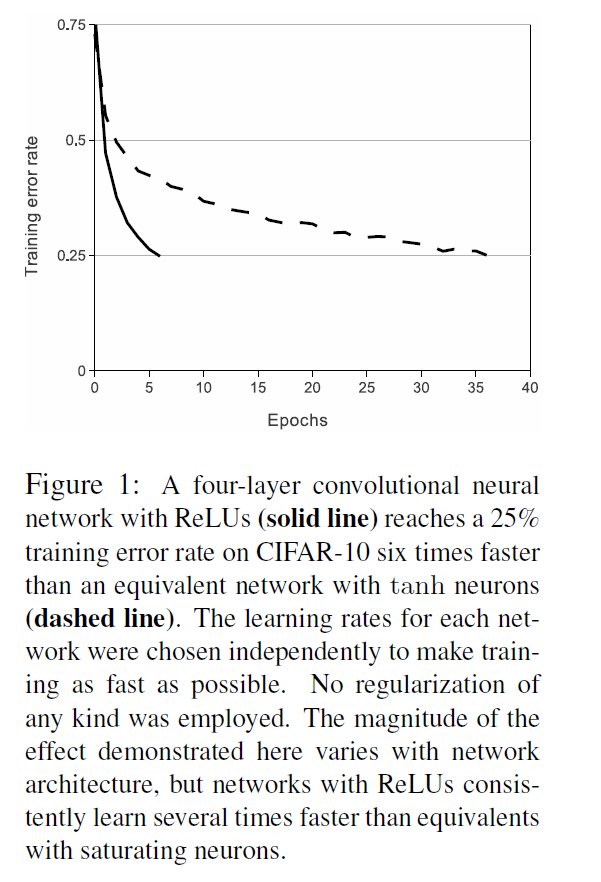
- LRN(Local Response Normalization),后面基本上被抛弃了
- overlap pooling
总体结构,5层卷积 + 3层全连接
降低过拟合
- 数据增强
- 256 256的图片随机去抠出来224 224的图
- 颜色变换(PCA
- 引入Dropout
- 这个东西可以从ensemble的角度去理解
- 但是作者过了几年又觉得这个不是在做ensemble就是等价于一个L2正则项
- 现在普遍网络不会使用这么大的FC层,也就导致dropout在CV这块没有那么重要
训练细节
- SGD作为优化器,动量更新
- FC层用1做初始化,这个后面基本上没人用
- LR在训练不动的时候手动向下调整0.1倍,现在主流做法是学习率从一个比较小的值开始上升然后cosin形式下降下来