对比学习的概念
代理任务
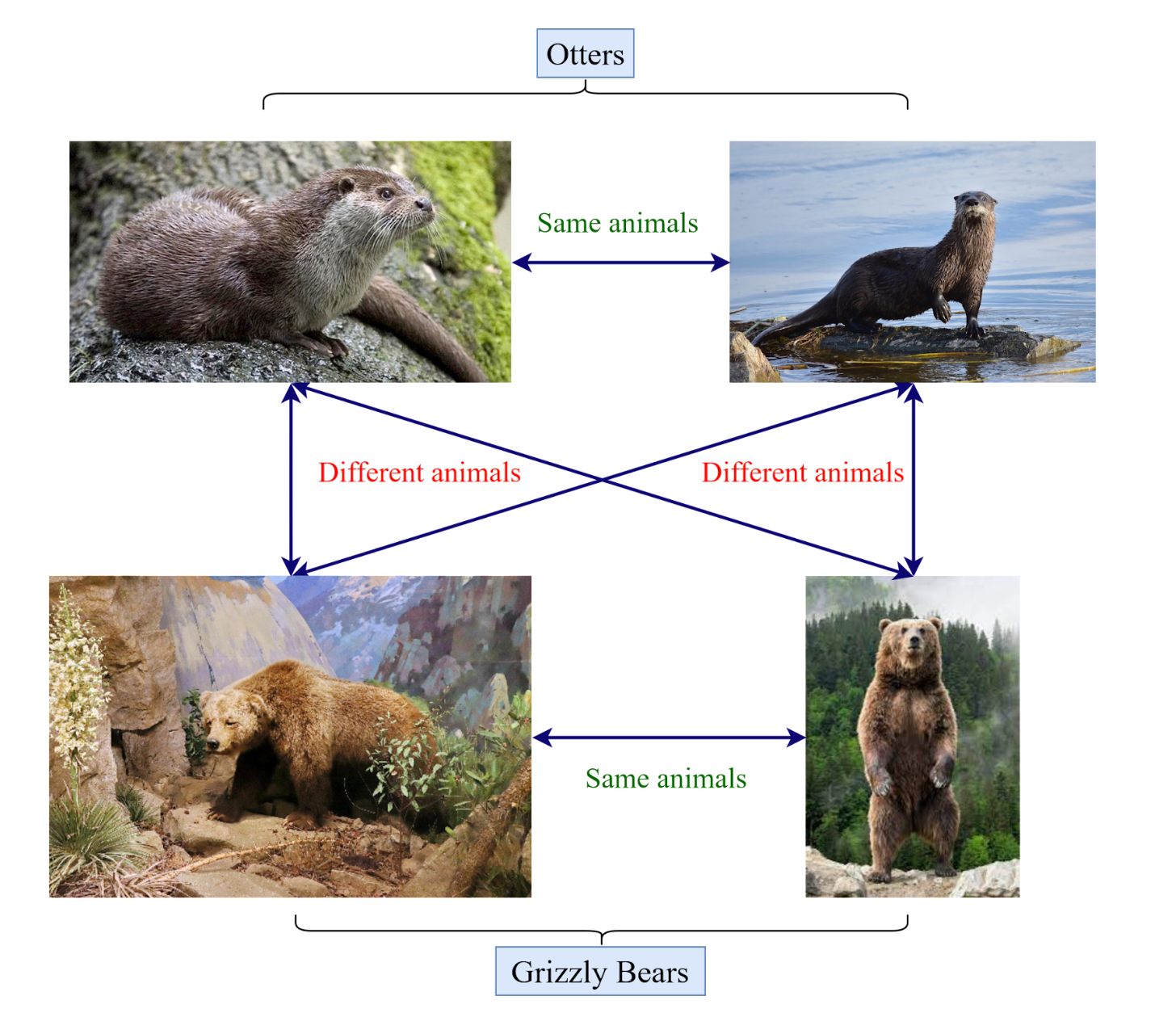
- 个体判别
- 九宫格
- 视频帧
- 数据增强
可以实现无监督学习
假设给一组数据
其中X是成对给出,如果相似则Y = 1否则为0
我们的目标是找到一个函数
实现降维和特征学习
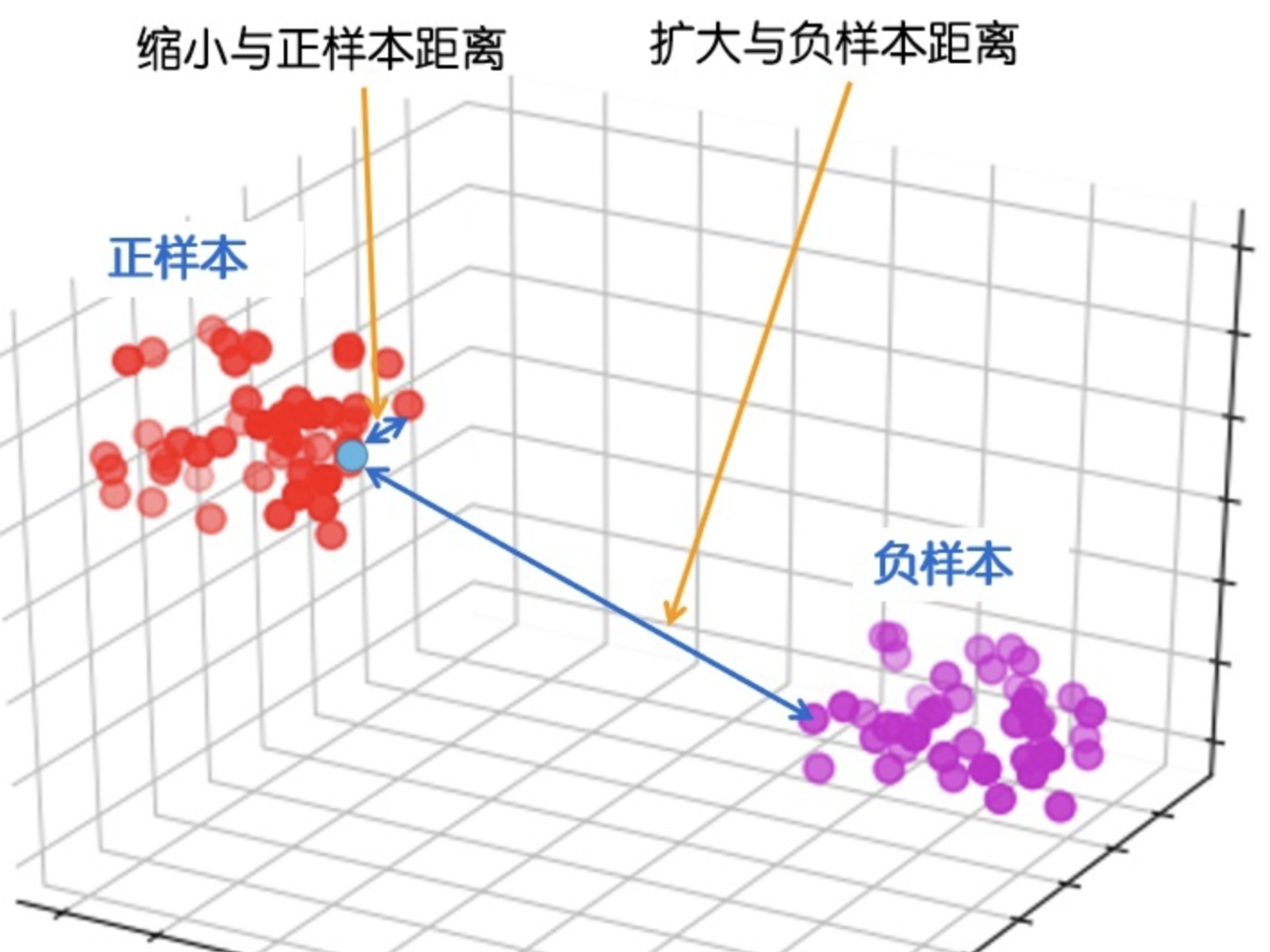
对比损失
定义距离:
损失函数:
由相似,不相似两部分组成
Triplet Loss
互信息
衡量变量间相互依赖性的度量
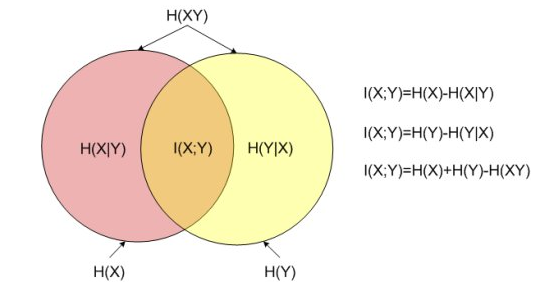
NCE/ InfoNCE loss
对softmax的改造,当类数特别多的时候不去计算归一化项,而是将问题拆解为多个二分类问题
模型结构
InstDisc
Unsupervised feature learning via non-parametric instance discrimination
开山之作,提出个体判别代理任务;对比学习框架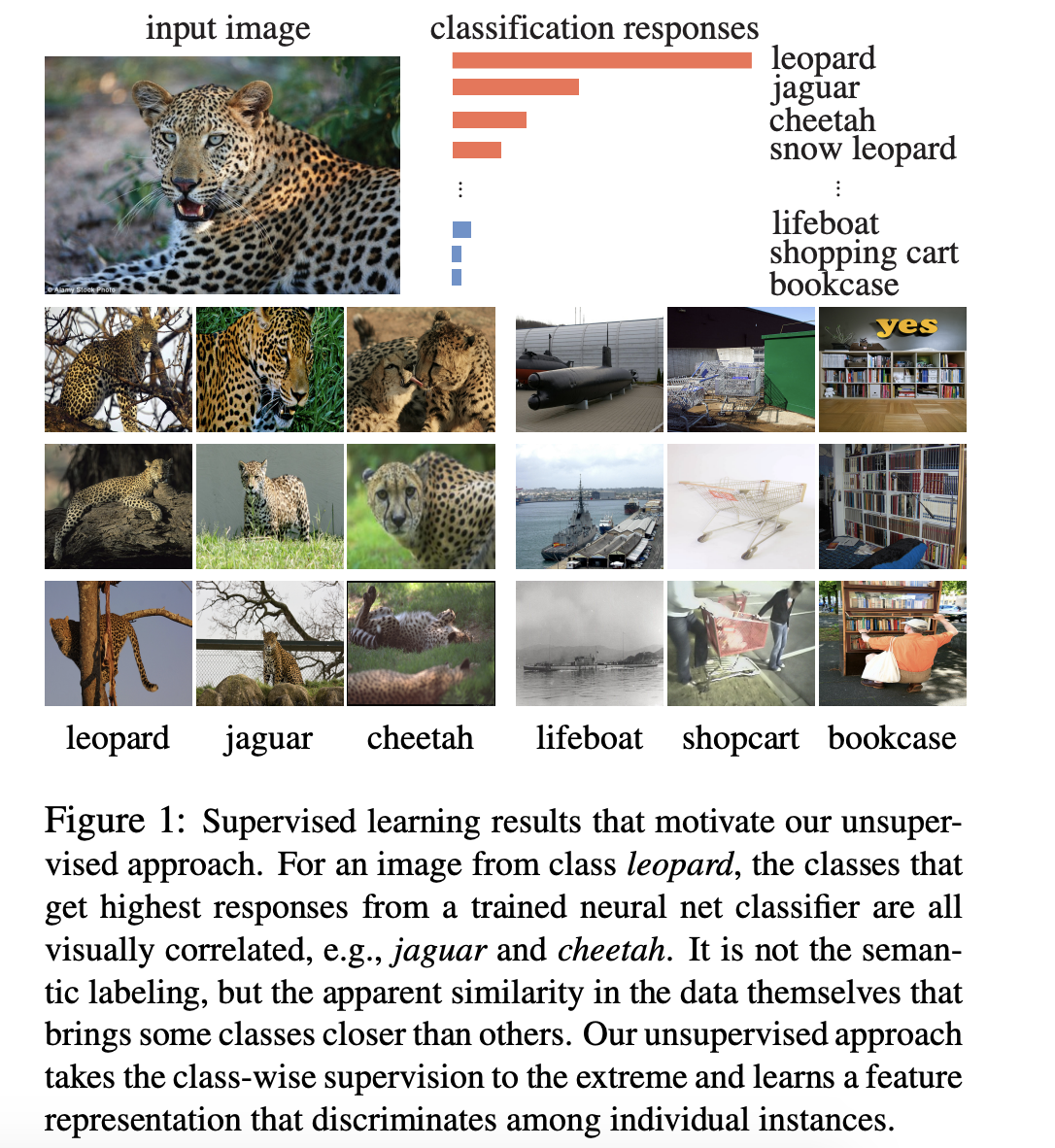
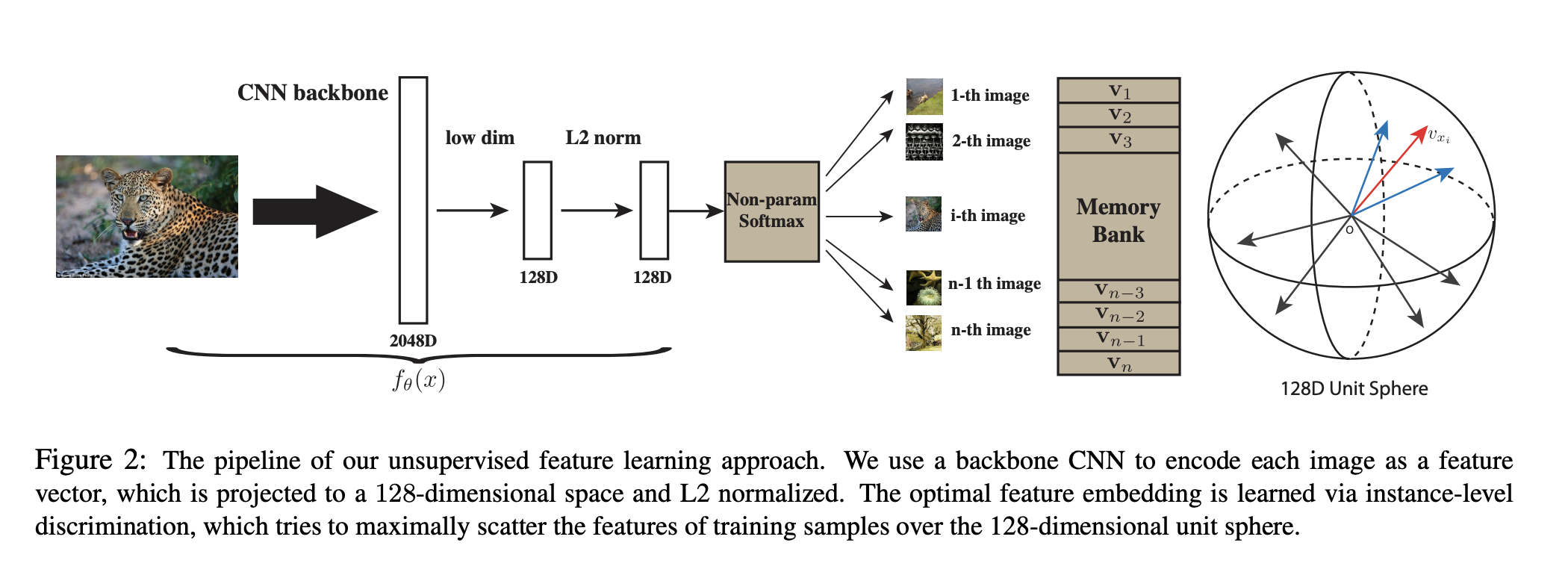
InvaSpread
Unsupervised Embedding Learning via Invariant and Spreading Instance Feature
端到端训练,SimCLR前身,但是受限于训练资源有限,效果并不好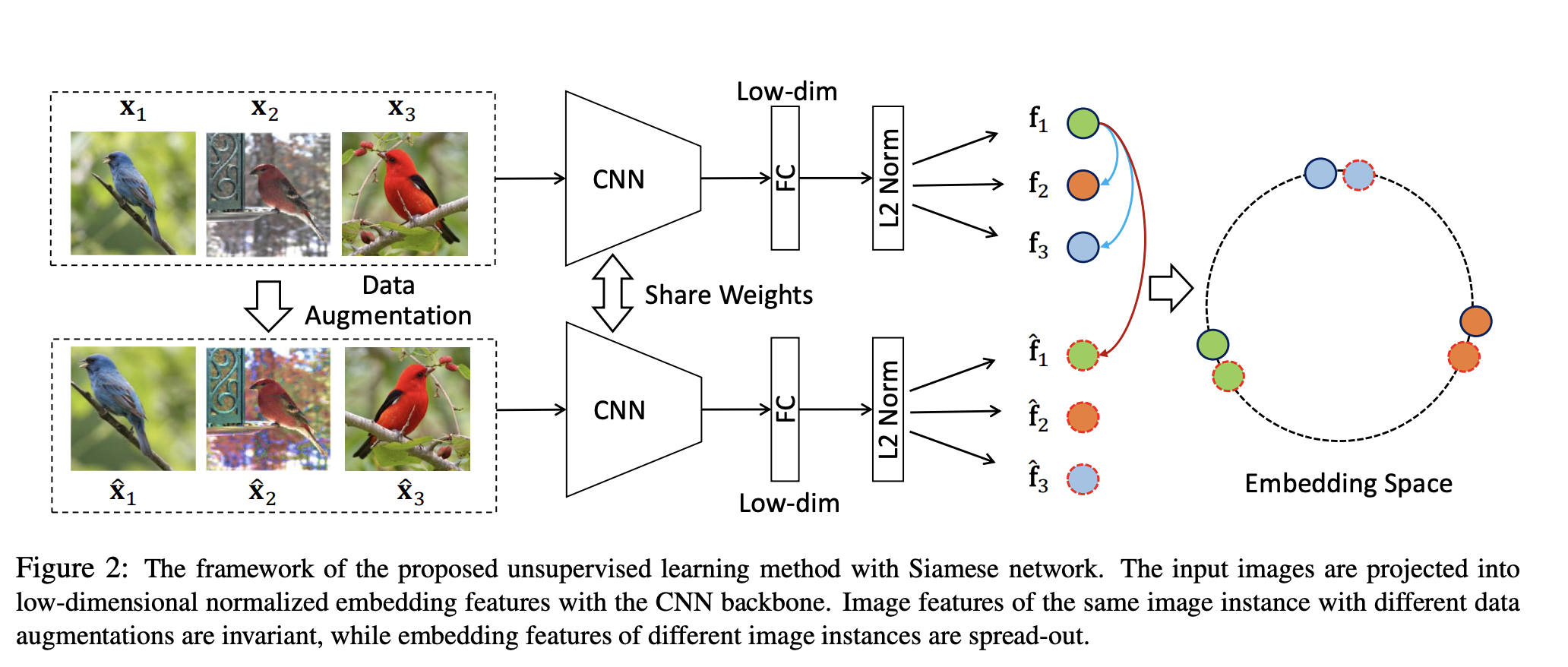
CPC
Representation Learning with Contrastive Predictive Coding
用预测去做代理任务;由NCE loss推广出InfoNCE loss
MoCO
Momentum Contrast for Unsupervised Visual Representation Learning
- 受NLP任务的启发(GPT、BERT),MOCO将对比学习转化为一个字典查询任务,图片数据分别编码成查询向量和键向量,即查询 q 与键队列 k ,队列包含单个正样本和多个负样本。通过对比损失来学习特征表示
- 锚点(query)用一个编码器,正样本和负样本(key)共用一个编码器
- 字典应有两个特性
- 大
- 稳定
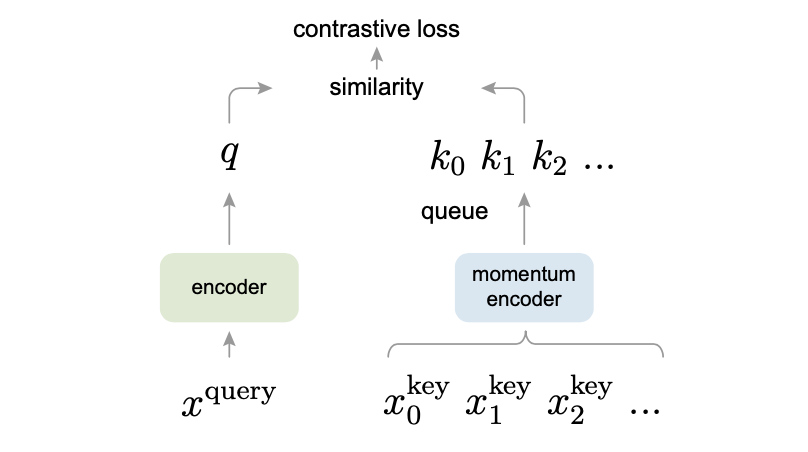
用队列代替字典,batch维度,将batch和字典大小剥离(256/65535),先进先出
动量更新,且相对较大0.999动量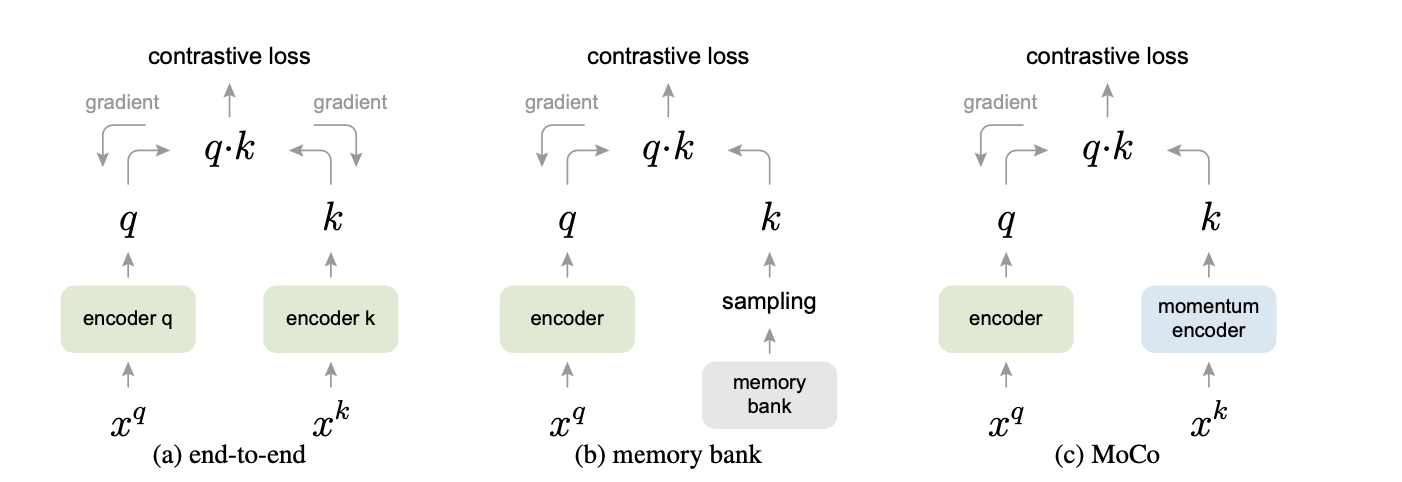
引入队列的效果对比:
引入动量的效果对比: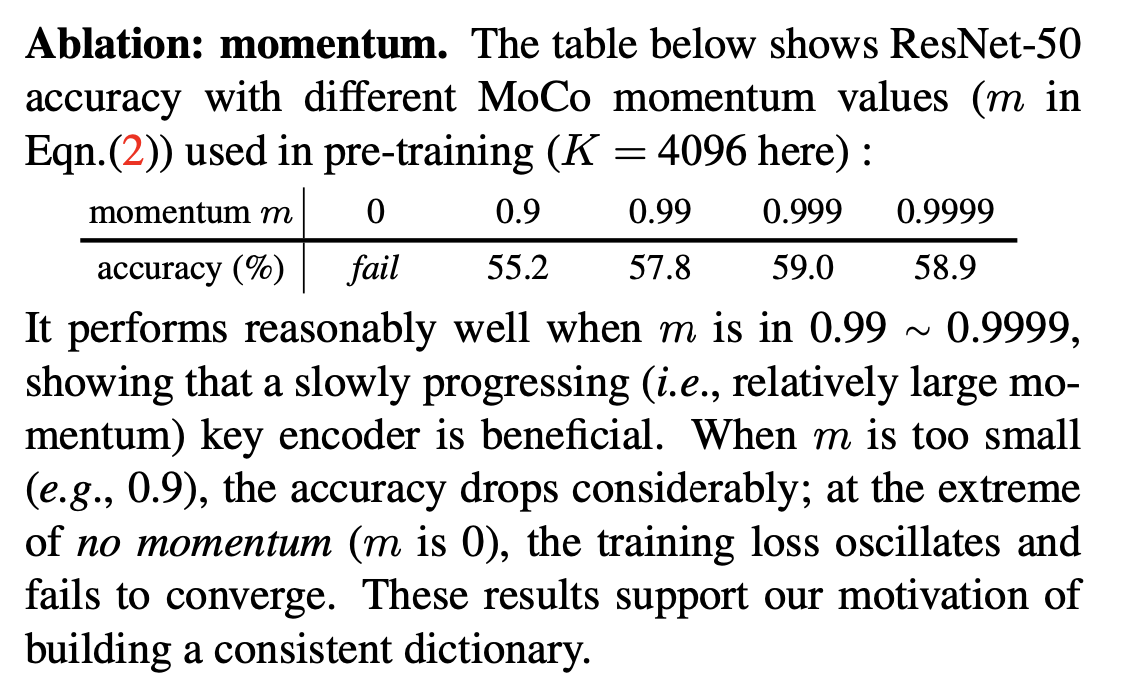
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32# f_q, f_k: encoder networks for query and key # queue: dictionary as a queue of K keys (CxK) # m: momentum
# t: temperature
f_k.params = f_q.params # initialize
for x in loader: # load a minibatch x with N samples
x_q = aug(x) # a randomly augmented version
x_k = aug(x) # another randomly augmented version
q = f_q.forward(x_q) # queries: NxC
k = f_k.forward(x_k) # keys: NxC
k = k.detach() # no gradient to keys
# positive logits: Nx1
l_pos = bmm(q.view(N,1,C), k.view(N,C,1))
# negative logits: NxK
l_neg = mm(q.view(N,C), queue.view(C,K))
# logits: Nx(1+K)
logits = cat([l_pos, l_neg], dim=1)
# contrastive loss, Eqn.(1)
labels = zeros(N) # positives are the 0-th
loss = CrossEntropyLoss(logits/t, labels)
# SGD update: query network
loss.backward() update(f_q.params)
# momentum update: key network
f_k.params = m*f_k.params+(1-m)*f_q.params
# update dictionary
enqueue(queue, k) # enqueue the current minibatch
dequeue(queue) # dequeue the earliest minibatchSimCLR
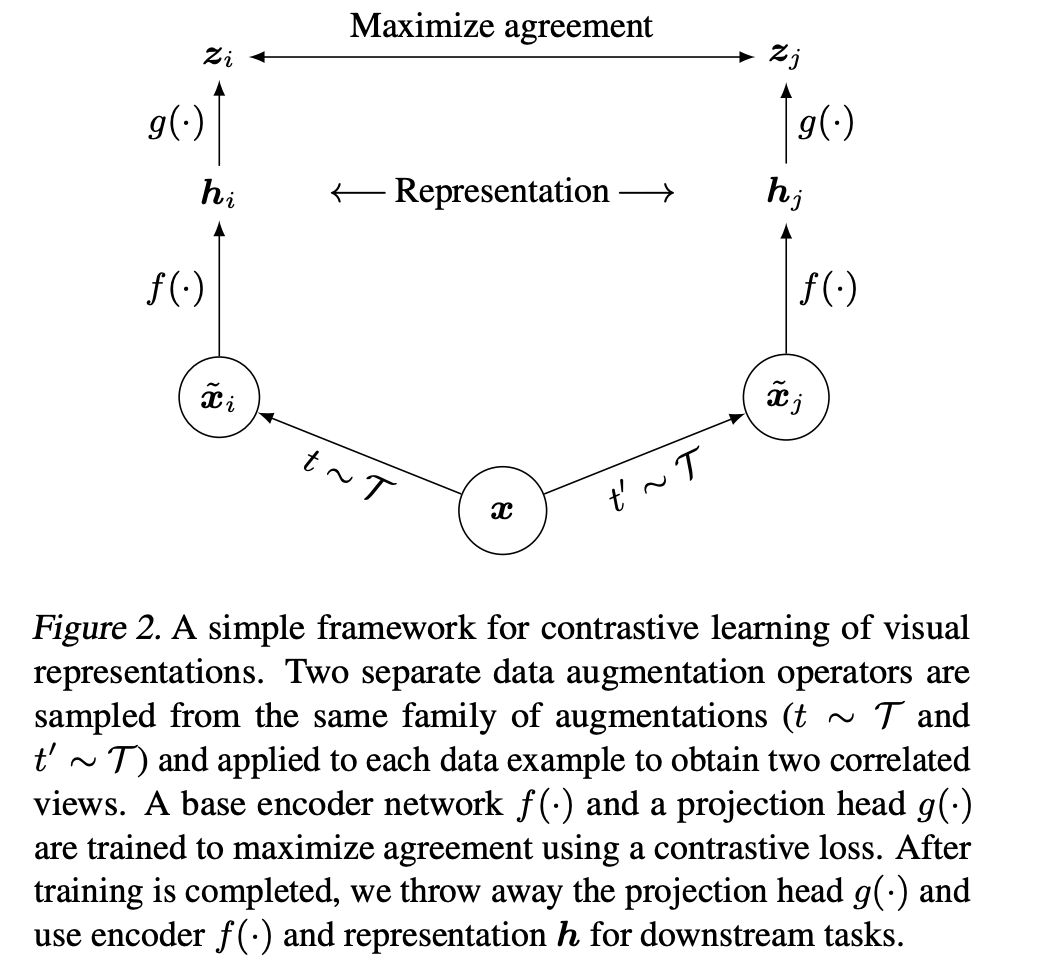
A Simple Framework for Contrastive Learning of Visual Representations视觉表征对于同一目标不同视角的输入都应具有不变性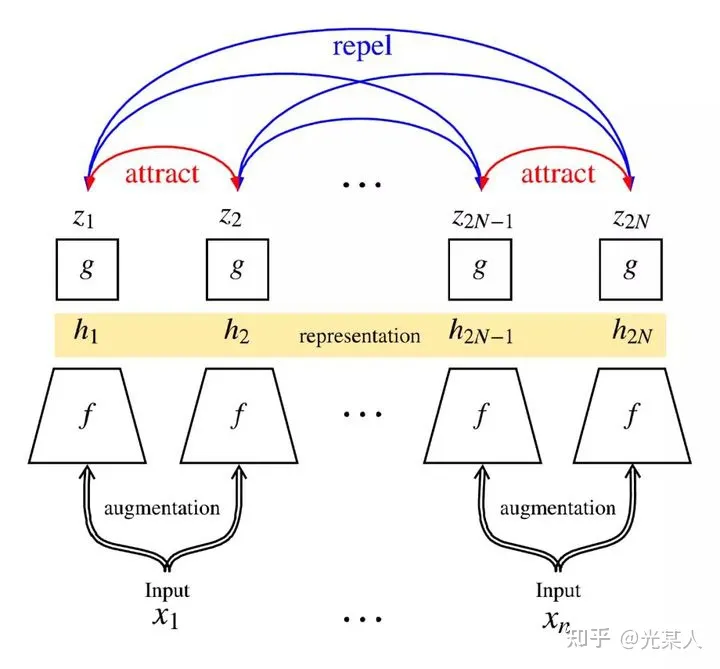
- 对mini batch中每张输入的图片进行两次随机数据增强(随机剪裁、滤镜、颜色过滤、灰度化等)来得到图片两种不同的视角,将得到的两个表征送入两个卷积编码器(如resnet)获得embedding,使用余弦相似度来度量embedding相似度
- SimCLR的batch-size达到了8192,用了128块TPU
- 用了很多的数据增强
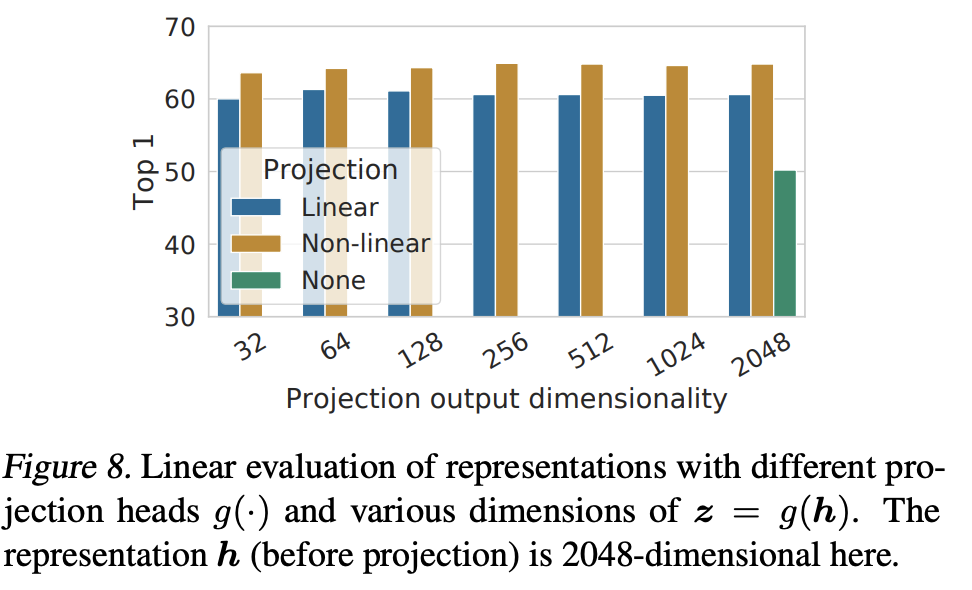
- 加了projector(MLP),用非线性变换(降维),效果有显著提升
MoCoV2
Improved Baselines with Momentum Contrastive Learning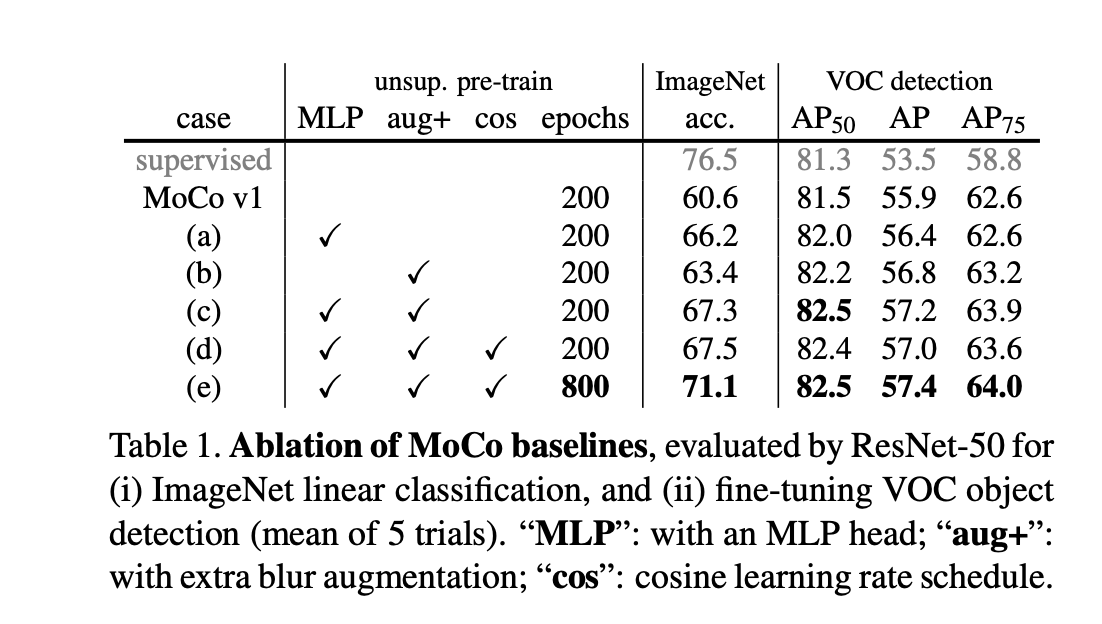
SimCLRv2
Big Self-Supervised Models are Strong Semi-Supervised Learners
换了一个更大的ResnetMLP由一层变为了两层引入动量编码器