总结
- 这篇文章提出了用CNN处理特征代替之前抽取MFCCs + 分类器的方式,获得了比较好的效果
- 比较关注将一段音频处理为音频输入的方法
- 将音频按照960ms切段
- 960ms的音频每10ms用短时傅里叶变换处理(25ms)的窗口
- 将生成的光谱图分到64个mel-spaced frequency bins里面
- 每个桶的结果取log
- 就生成96 * 64的二维向量然后用CNN的方式搞
- 后面文章对比了多种模型和数据集大小的结果基本上越深的模型越好,数据集越大越好
Abstract
Finding that analogs of the CNNs used in image classification do well on our audio classification task
Introduction
Our labels apply to entire videos without any changes in time, so we have yet to try such recurrent models
By computing log-mel spectrograms of multiple frames, we create 2D image-like patches to present to the classifiers
Dataset
- YouTube-100M
- 4.6 min per video on average
- 1 or more topic identifiers from 30871 labels
- 5 labels per video on average
Experimental Framework
Training
sample generation:
- The audio is divided into non-overlapping 960 ms frames
- The 960 ms frames are decomposed with a short-time Fourier transform applying 25 ms windows every 10 ms
- The resulting spectrogram is integrated into 64 mel-spaced frequency bins
- The magnitude of each bin is log-transformed after adding a small offset to avoid numerical issues
- This gives log-mel spectrogram patches of 96 × 64 bins that form the input to all classifiers
Evaluation
We passed each 960 ms frame from each evaluation video through the classifier. We then averaged the classifier output scores across all segments in a video.
Architectures
fully Connected
Our best performing model had N = 3 layers, M = 1000 units
AlexNet
Because our inputs are 96 × 64, we use a stride of 2 × 1 so that the number of activations are similar after the initial layer
VGG
We tried another variant that reduced the initial strides (as we did with AlexNet), but found that not modifying the strides resulted in faster training and better performance
Incepiton V3
We modified the inception V3 by removing the first four layers of the stem, up to and including the MaxPool, as well as removing the auxiliary network
We tried including the stem and removing the first stride of 2 and MaxPool but found that it performed worse than the variant with the truncated stem
ResNet-50
We modified ResNet-50 by removing the stride of 2 from the first 7×7 convolution
Experiments
Architecture Comparison
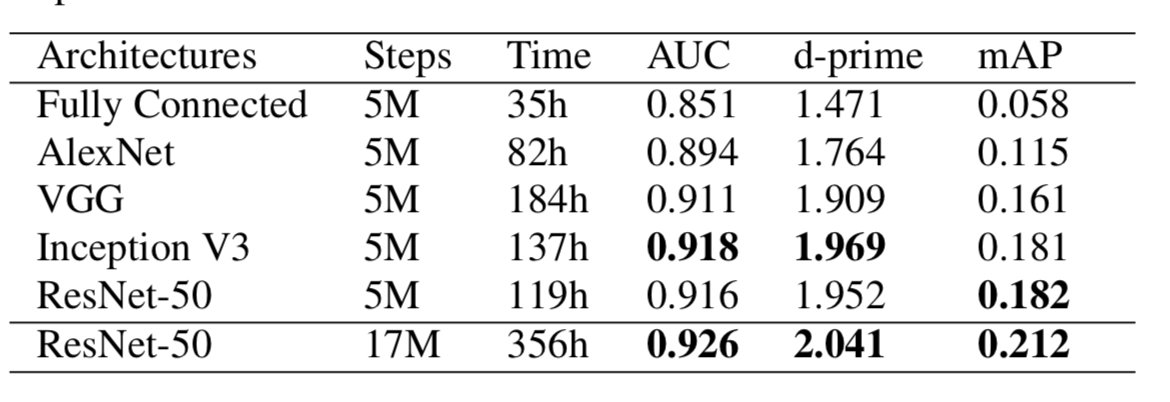
Inception and ResNet achieve the best performance
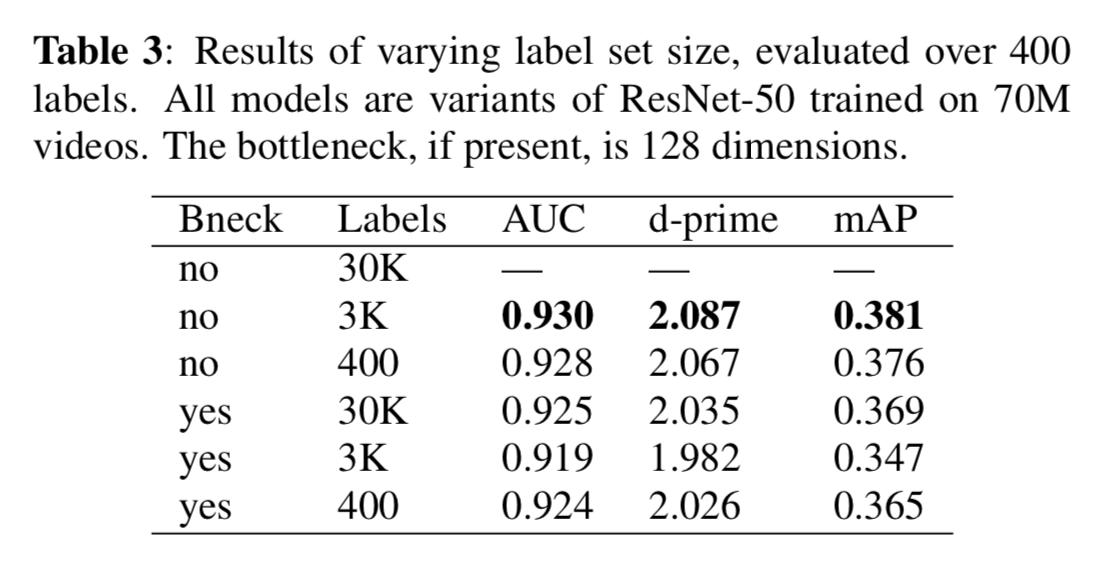
Label Set Size
Using a 400 label subset of the 30K labels, we investigated how training with different subsets of classes can affect performance
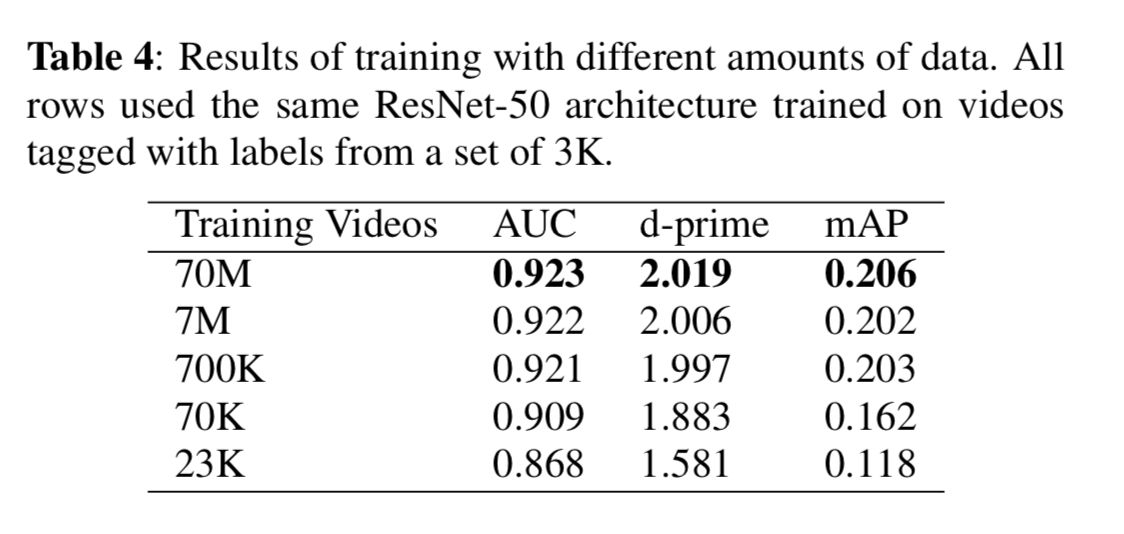
Traning Set Size
Having a very large training set available allows us to investigate how training set size affects performance
AED with the Audio Set Dataset
The log-mel baseline achieves a balanced mAP of 0.137 and AUC of 0.904
Conclusions
skip over