总结
- 这篇文章提出了几种CNN结构用于处理视频
- single frame
- early fusion:将CNN的input做改造一次接收多张图片
- late fusion:两个CNN同时跑,在FC层做合并
- slow fusion:两者融合,在这篇paper中获得best performance,但计算更慢
- 类比于图像处理,视频处理更加耗时,在文章中提出了双流结构用于对计算速度进行优化
- context stream: 处理整张图片,输入的大小将为原来的一半
- fovea stream: 处理图像的中间部分,大小为原图的一半,不过分辨率更高
- 然后在FC层附近将两个流的结果融合
- 总体来看运算时间得以降低,但是精度却没有太多下降
- 作者探讨了这个网络的迁移学习能力,又拿UCF-101做了实验,fine-tune 前三层的网络的效果最好
Abstract
We provide an extensive empirical evaluation of CNNs on large-scale video classification
Introduction
There are several challenges to extending and applying CNNs in this setting
Problem:
- there are currently no video classification benchmarks that match the scale and variety of existing image datasets
Solution:
YouTube Sports-1M dataset
Problem:
- modeling perspective:
- what temporal connectivity pattern in a CNN architecture is best at taking advantage of local motion information present in the video
- how does the additional motion information influence the predictions of a CNN
- how much does it improve performance overall
Solution:
We examine these questions empirically by evaluating multiple CNN architectures
Problem:
- computational perspective:
- CNNs require extensively long periods of training time
Solution:
modify CNN into two separate streams:
- a context stream that learns on low-resolution frames
- a Image feature stream that learns on high-resolution frames
Problem:
- whether features are generic enough to generalize to a different smaller dataset
Solution:
- re-purposing low-level features is significantly useful
Related Work
standard approach to video classification:
- First, local visual features that describe a region of the video are extracted either densely or at a sparse set of interest points
- use a learned k-means dictionary map feature to visual words. Over duration of video, get visual word histograms
- a classifier (such as an SVM) is trained on the resulting ”bag of words” representation to distinguish among the visual classes of interest
Models
Time Information Fusion in CNNs
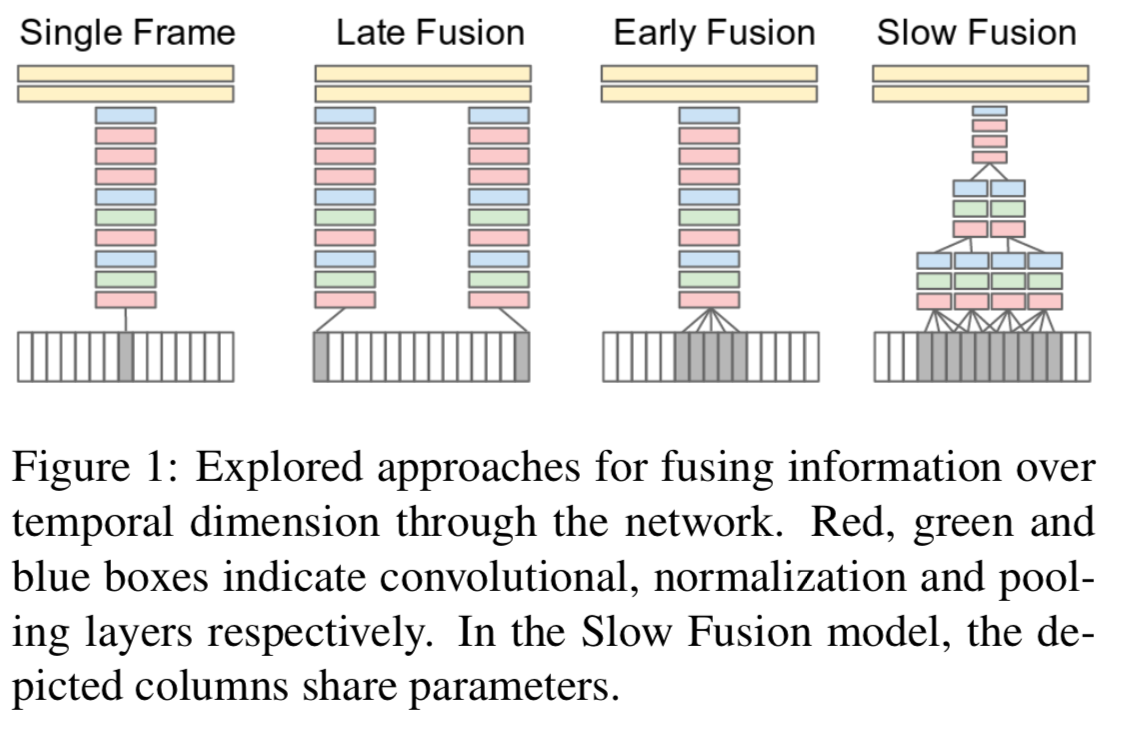
Single-frame
use CNNs to process one image
Early Fusion
This is implemented by modifying the filters on the first convolutional layer in the single-frame model by extending them to be of size 11 × 11 × 3 × T pixels
Late Fusion
The Late Fusion model places two separate single-frame networks with shared parameters a distance of 15 frames apart and then merges the two streams
the first fully connected layer can compute global motion characteristics
Slow Fusion
higher layers get access to progressively more global information in both spatial and temporal dimensions
This is implemented by extending the connectivity of all convolutional layers in time and carrying out temporal convolutions in addition to spatial convolutions to compute activations
Multiresolution CNNs
changes in the architecture that enable faster running times without sacrificing performance
we conducted further experiments on training with images of lower resolution
Fovea and context streams
The proposed multiresolution architecture aims to strike a compromise by having two separate streams of processing over two spatial resolutions
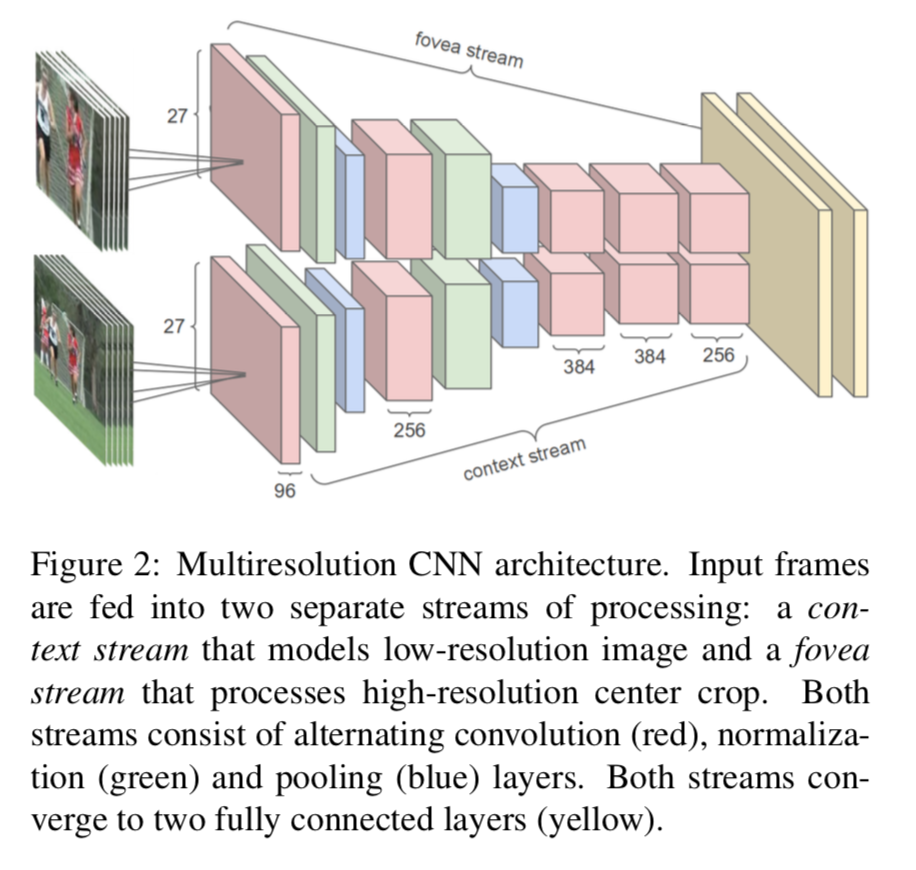
- the context stream receives the downsampled frames at half the original spatial resolution (89 × 89 pixels),
- while the fovea stream receives the center 89 × 89 region at the original resolution.
Architecture changes
We take out the last pooling layer to ensure that both streams still terminate in a layer of size 7 × 7 × 256
Learning
Detailed parameter setting in training. skip over.
Result
Experiments on Sports-1M
Video-level predictions
- to produce predictions for an entire video we randomly sample 20 clips and present each clip individually to the network. Every clip is propagated through the network 4 times (with different crops and flips)
- averaging individual clip predictions over the durations of each video
Feature histogram baselines
traditional method setting. skip over.
Quantitative results
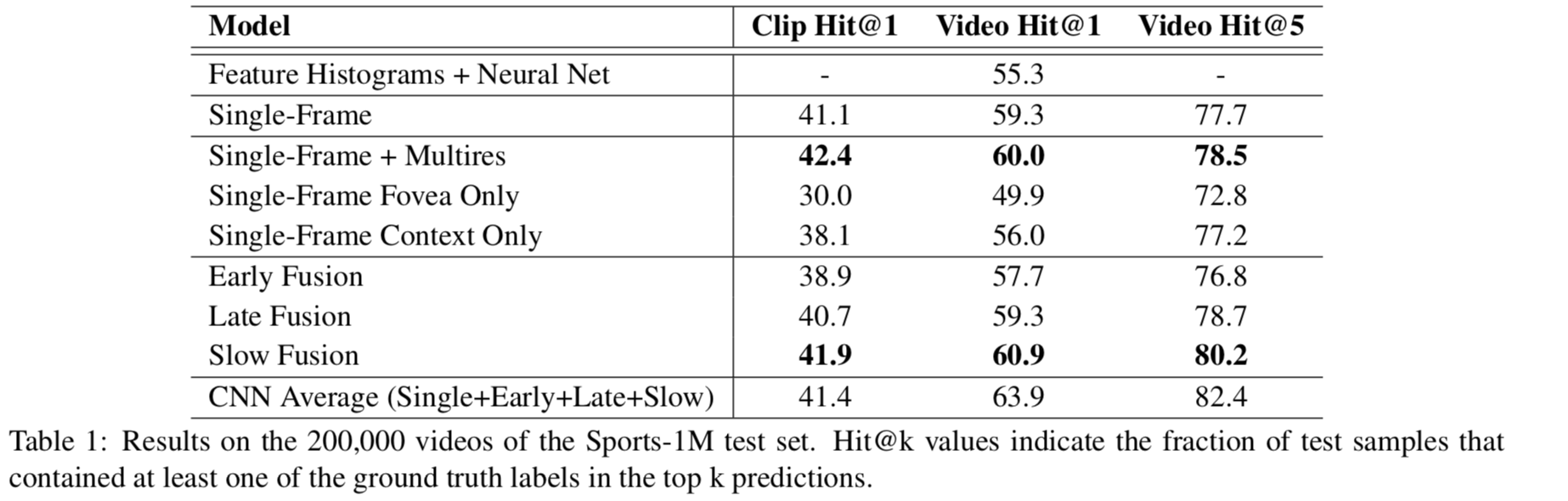
Our networks consistently and significantly outperform the feature-based baseline
The variation among different CNN architectures turns out to be surprisingly insignificant
Foveated architectures are between 2-4× faster
Contributions of motion
we qualitatively observe that the motion-aware network clearly benefits from motion information in some cases, but these seem to be relatively uncommon
we observe that motion-aware networks are more likely to underperform when there is camera motion present.
Qualitative analysis
bad case study. skip over.
Transfer Learning Experiments on UCF-101
A natural question that arises is whether these features also generalize to other datasets and class categories
We examine this question in detail by performing transfer learning experiments on the UCF-101
Transfer learning
We consider the following scenarios for our transfer learning experiments:
- Fine-tune top layer: We found that as little as 10% chance of keeping each unit active to be effective
- Fine-tune top 3 layers: We introduce dropout before all trained layers, with as little as 10% chance of keeping units active
- Fine-tune all layers
- Train from scratch
Results

The best performance is obtained by taking a balanced approach and retraining the top few layers of the network
Performance by group
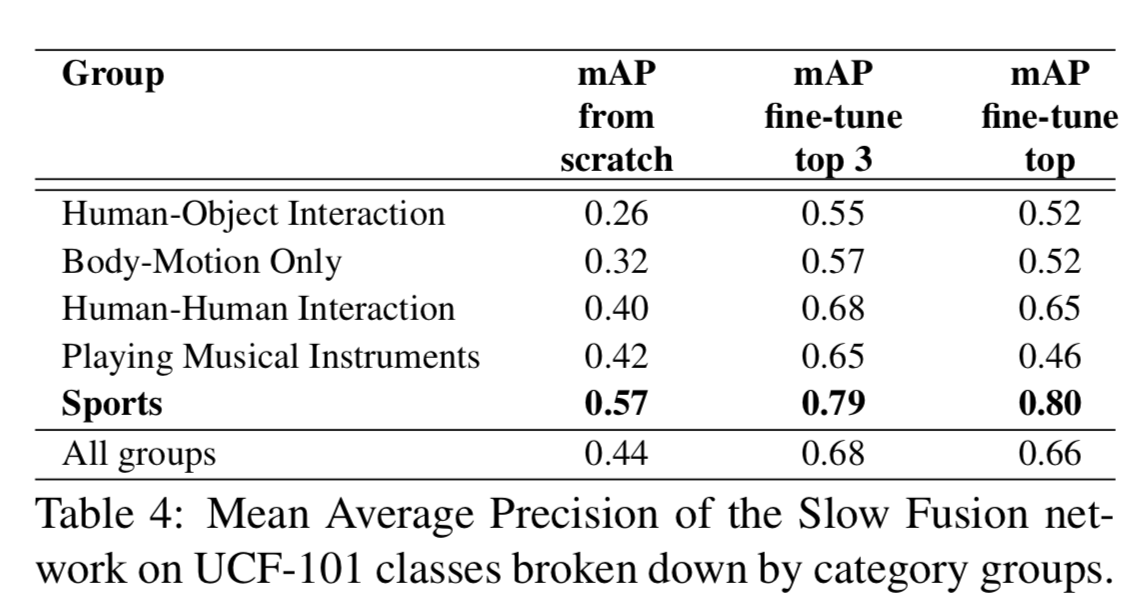
Fine-tune top 3 improve performance from non-sports categories
Conclusions
skip over.