总结
- 这篇文章主要是在YOLO的基础上加以改进提出了更好的YOLO V2
- 此外还提出了一种合并classification和detection数据集的方式,从而大大拓展了训练数据集的规模和分类目标数
- 具体改进的点
- BN:加了BN之后有2%的mAP提升
- 用更高清的图片来fine-tune图片分类网络:有4% mAP提升
- 使用Anchor来预测物体范围代替直接预测:准确率下降,召回率上升
- 下面又使用了两个改进方式来改进使用Anchor的版本
- 用K-means的方法学习数据集中的标注来选取物体范围的初始框,而不是使用Anchor尝试;为了平衡模型的复杂度和recall选定了K = 5
- 来修正bounding-box的阶段,模型的可选择范围较大,造成模型在初始训练阶段不稳定,修改了修正的方式——使用sigmod把回归预测值固定在0~1范围内,表示在格子内的比例:相较于Anchor box版本有接近5%左右的提升
- 加入高清特征
- 模型最终的输出是13*13
- 我们直接把上一层的2626的特征拿过来,将filter数量翻四倍,把维度变为1313
- 将新的layer与之前的输出层stack到一起成为新的feature map
- 有1%的提升
- 多尺度训练
- 每隔10个batch随机改变input的size大小让网络可以应对不同尺度大小的图片
- 小图片的inference时间短,用这种方法可以方便的在mAP和测试时间之间做trade off
- 加入了这些新的特性后诞生了YOLO v2
- 文章中还提出了一个混合分类数据集的方式
- 在训练过程中如果遇到了分类数据(无detection标注)那么只进行分类部分损失函数的反向传播
- 还有一个标签不统一的问题,往往因为分类数据更加丰富所以,分类数据的标签会更细一些,文章针对这个问题建立了一颗标签语义树,不同粒度的标签可以都可以在语义树中找到正确的位置
- 同时模型在分类预测的时候也依照语义树进行不同粒度的softmax
VOC测试结果
- time: 15ms
- VOC 2007: 76.8%
Abstract
- propose various improvements to the YOLO detection method——YOLO v2
- propose a method to jointly train on object detection and classification——YOLO9000
Introduction
- We propose a new method to harness the large amount of classification data we already have and use it to expand the scope of current detection systems
- We also propose a joint training algorithm that allows us to train object detectors on both detection and
Better
Flaws:
- YOLO makes a significant number of localization errors
- YOLO has relatively low recall compared to region proposal-based methods
Batch Normalization
By adding batch normalization on all of the convolutional layers in YOLO we get more than 2% improvement in mAP
High Resolution Classifier
We first fine tune the classification network at the full 448 × 448 resolution for 10 epochs on ImageNet.
Gives us an increase of almost 4% mAP
Convolutional With Anchor Boxes
Predicting offsets instead of coordinates simplifies the problem and makes it easier for the network to learn
- we get an output feature map of 13 × 13
- decouple the class prediction mechanism from spatial location
We get a small decrease in accuracy but increase in recall rate
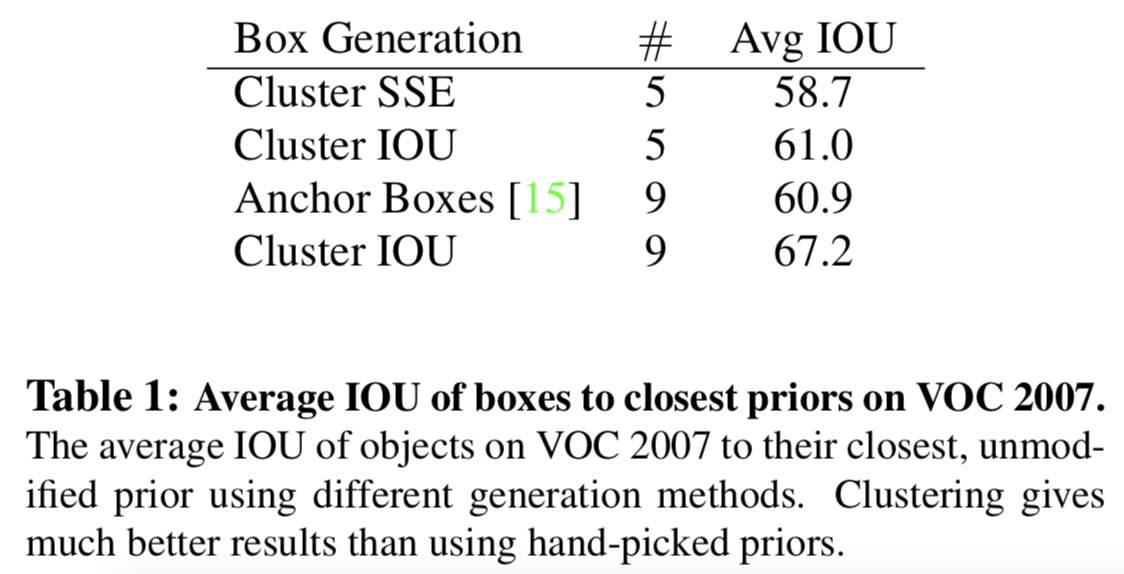
Dimension Clusters
- We run k-means clustering on the training set bounding box to automatically find good priors
we redefine distance metric by:
- We choose k = 5 as a good tradeoff between model complexity and high recall
- There are fewer short, wide boxes and more tall, thin boxes
Direct location prediction
- The location prediction is unconstrained so any anchor box can end up at any point in the image
- to fix this problem we predict location coordinates relative to the location of the grid cell
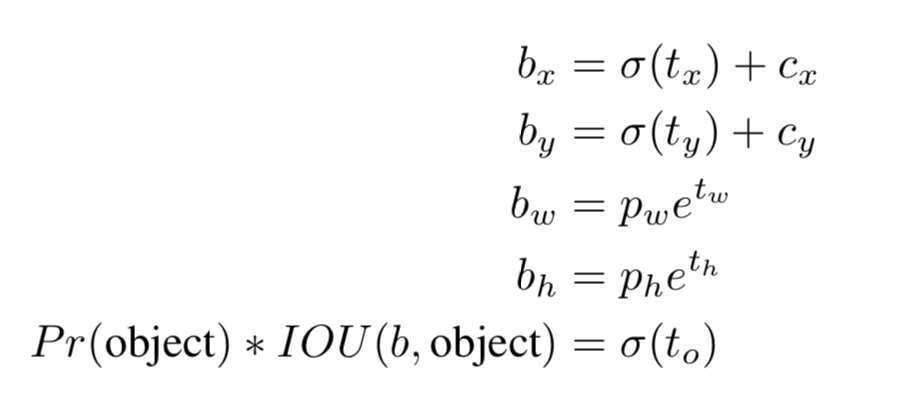
- this operation makes network more stable
- improves almost 5% over the version with anchor boxes
Fine-Grained Features
Turns the 26 26 256 feature map into a 13 13 2048 feature map to use fine-grained picture
Improves 1% performance
Multi-Scale Training
- Every 10 batches our network randomly chooses a new image dimension size
- offers an easy tradeoff between speed and accuracy
Faster
The YOLO framework uses a custom network based on the Google-net architecture
Darknet-19
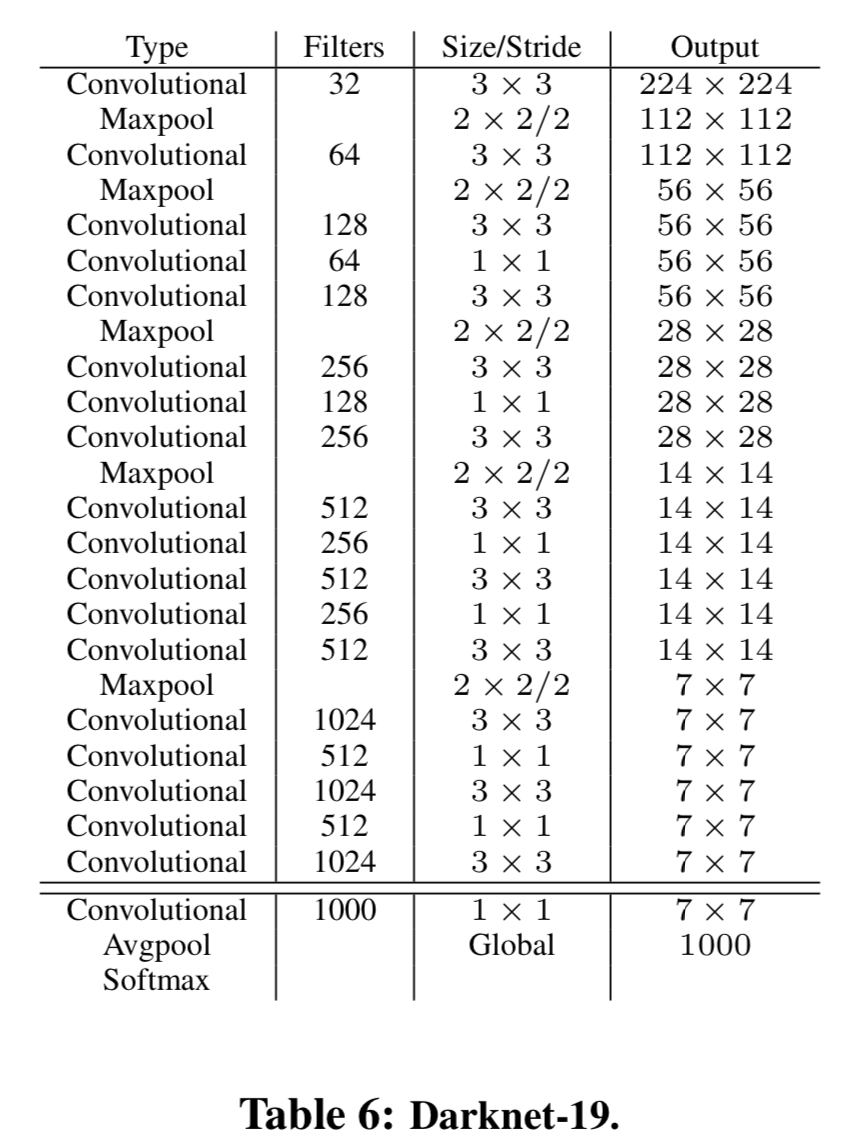
Training for classification
After our initial training on images at 224 × 224 we fine tune our network at a larger size, 448.
Training for detection
Removing the last convolutional layer and instead adding on three 3 × 3 convolutional layers with 1024 filters each followed by a final 1 × 1 convolutional layer with the number of outputs we need for detection
Add a passthrough layer to use fine grain features
Stronger
We propose a mechanism for jointly training on classification and detection data:
- mix images from both detection and classification datasets
- detection data: backpropagate based on the full YOLOv2 loss function
- classification data: only backpropagate loss from classification part
Flaw:
- labels are not mutual exclusion(“Norfolk terrier” and “dog”) so we can’t use softmax
Solution:
- use multi-label model
Hierarchical classification
- Get structure from WordNet
- Simplify graph structure into tree
- Calculate probability by multiply conditional probabilities on the path of tree

we compute the softmax over all sysnsets that are hyponyms of the same concept
Dataset combination with WordTree
Combine multiple datasets together
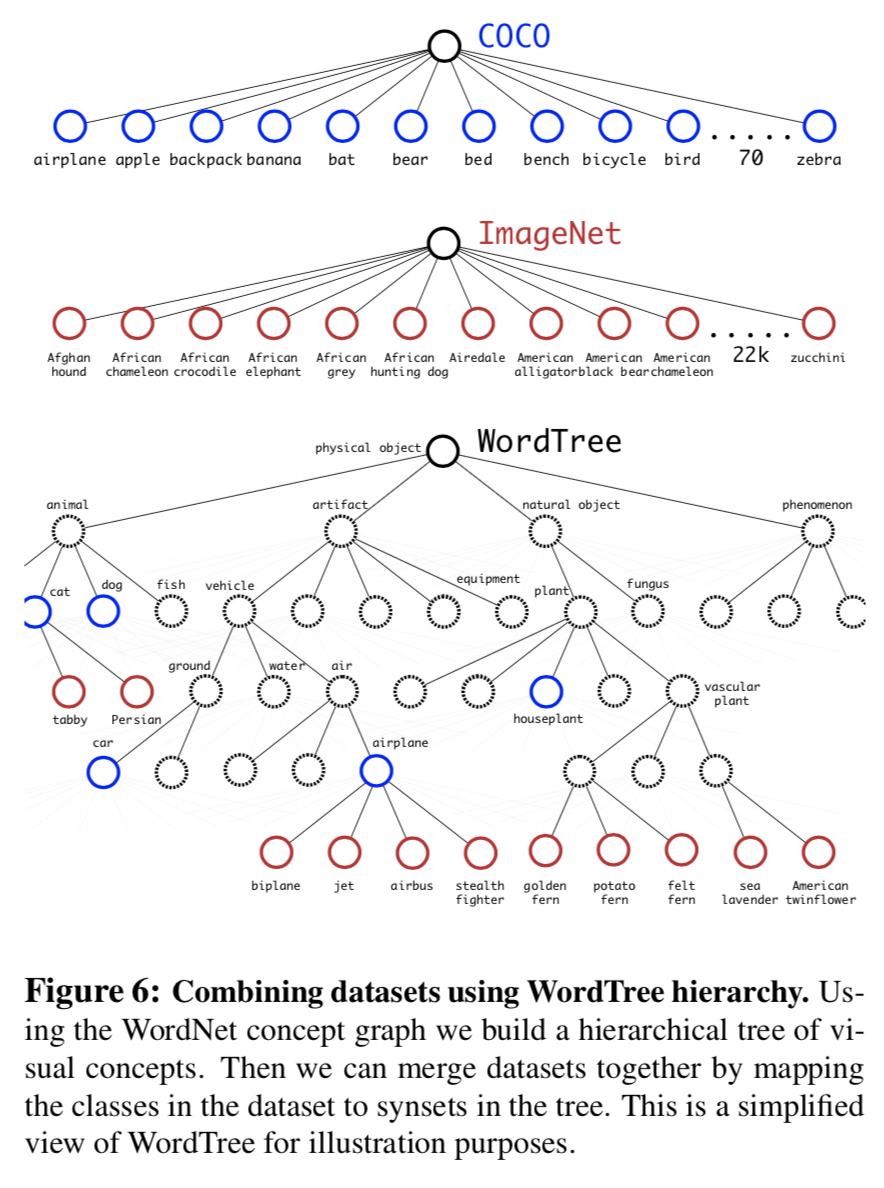
Joint classification and detection
Using this dataset we train YOLO9000
YOLO9000 gets 19.7 mAP overall
- learn new species of animals well
- struggles with learning categories like clothing and equipment
Conclusion
skip