总结
- 本文是结合RCNN和SPPnet的改进版本
- 大幅提成训练/测试速度
- 实现端对端一体化训练
对前作缺点分析
- RCNN
- 多阶段训练
- 训练慢,也占用硬盘空间
- inference也慢
- SPPnet
- 多阶段训练
- fine-tuning阶段无法更新conv网络参数
网络结构
- 借用SPPnet的思想,每次训练只有一次整体图片的卷积计算,然后通过映射截取特定proposal的卷积值
- 然后过RoI pooling层(窗口大小和步长根据输入大小动态计算)得到定长特征向量
- 舍弃SVM训练阶段,直接使用网络softmax去做分类
- 特征向量同时给到bounding-box回归训练流程,结合两个部分组成一个新的损失函数一起训练
训练样本组成
- 首先分析了SPPnet不能fine-tuning卷积层参数的原因——不同图片的proposal需要重新计算卷积值走了RCNN的老路,耗时太长
- 所以在sampling阶段,尽量用同一图片的proposal构成batch
- 实验证明,选取同一图片的proposal没有收敛之类的问题
FC层分解
- 简化了卷积层的计算步骤之后,FC层的计算就显得时间过长了(总计算时长的38.7%)
- 利用因式分解的思想简化计算——将uv的计算量分解为t (u + v)其中$t \ll min(u, v)$
其他的思考
- fine-tuning全部网络是否有用?——用处不大,且会让训练速度大大降低,所以一般只fine-tuning后面几层(具体哪几层根据网络深度而定)
- 分多任务训练是否有帮助?——把分类损失和bounding-box回归损失结合在一起的效果最好,原因可能是分类任务&bounding任务共同反馈使网络学习的更好
- 尺度不变性用多尺度抽取还是单尺度?——多尺度效果更好但有限;在大型网络中因为GPU内存的限制(暂时)用不了多尺度,此时单尺度的效果超越中、小网络的多尺度,所以网络结构才是关键。选择尽量深的网络加单尺度
- 需要更多的训练数据?——是的,训练数据越多越好
- SVMs比softmax表现效果更好?——对,感觉有点打脸?RCNN里一通分析为啥要单拎出来一个训练流程做分类,结果这次直接合在一块而且效果更好了。除了文章中提到的softmax训练引入了不同类别之间的竞争,个人认为还有一个原因是合并流程把bounding-box回归也合并进来了共同提升了效果
- 更多的proposal会提升效果?——不是,实验证明后续proposal变多会让mAP变低
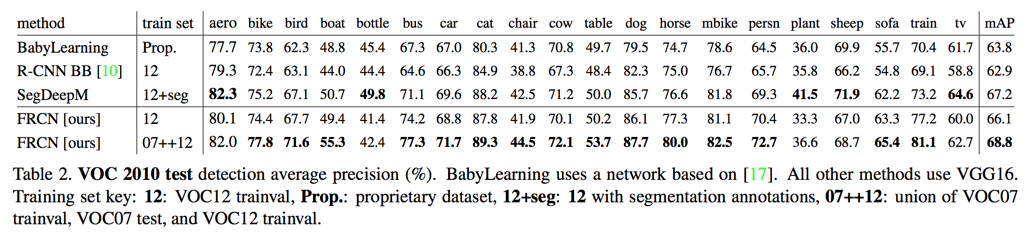
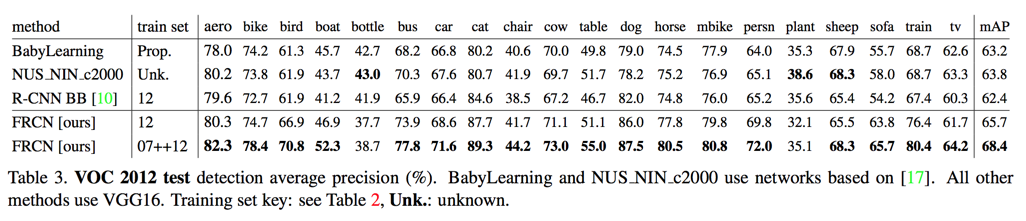
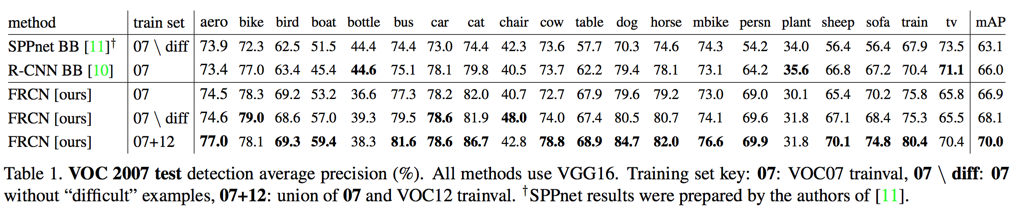
VOC测试结果
- time: 1830ms
- VOC 2007
- 07 data: 66.9%
- 07+12 data: 70%
- VOC 2010
- 12 data: 66.1%
- 07+12 data: 68.8%
- VOC 2012
- 12 data: 65.7%
- 07+12 data: 68.4%
Abstrct
Fast R-CNN trains the very deep VGG16 network 9× faster than R-CNN
Introduction
two primary challenges:
- numerous candidate object locations (often called “proposals”) must be processed
- these candidates provide only rough localization that must be refined to achieve precise localization
We propose a single-stage training algorithm that jointly learns to classify object proposals and refine their spatial locations.
R-CNN and SPPnet
R-CNN’s drawbacks:
- training is a multi-stage pipeline
- training is expensive in space and time
- object detection is slow
R-CNN is slow because it performs a ConvNet forward pass for each object proposal
SPPnet just compute convolutional feature map once per image
SPPnet’s drawbacks:
- training is a multi-stage pipeline
- fine-tuning algorithm cannot update the convolutional layers
contributions
- higher detection quality
- training is single-stage, using a multi-task loss
- training can update all network layers
- no disk storage is required for feature caching
Fast R-CNN Architecture and Training
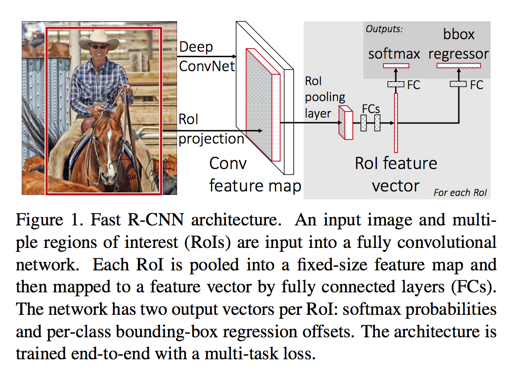
- the network first processes the whole image with several convolutional (conv) and max pooling layers to produce a conv feature map
- for each object proposal a region of interest (RoI) pooling layer extracts a fixed-length feature vector from the feature map. Each feature vector is fed into a sequence of fully connected
- one that produces softmax probability estimates over K object classes plus a catch-all “background” class
- outputs four real-valued numbers for each of the K object classes
the RoI pooling layer
each RoI is defined by a four-tuple (r, c, h, w) that specifies its top-left corner (r, c) and its height and width (h, w)
the RoI layer is simply the special-case of the spatial pyramid pooling layer used in SPPnets 11 in which there is only one pyramid level.
initializing from pre-trained networks
three transformations:
- the last max pooling layer is replaced by a RoI pooling layer
- the network’s last fully connected layer and softmax are replaced with the two sibling layers
- the network is modified to take two data inputs: a list of images and a list of RoIs in those images
fine-tuning for detection
Question:
- why SPPnet is unable to update weights below the spatial pyramid pooling layer
Answer:
- that back-propagation through the SPP layer is highly inefficient when each training sample (i.e. RoI) comes from a different image
- the inefficiency stems from the fact that each RoI may have a very large receptive field, often spanning the entire input image
- the training inputs are large
Solution:
- sampled hierarchically
- first by sampling N images and then by sampling R/N RoIs from each image
- RoIs from the same image share computation and memory in the forward and backward passes
- don’t cause slow training convergence in practice
- N = 2 and R = 128
multi-task loss
We use a multi-task loss L on each labeled RoI to jointly train for classification and bounding-box regression
- in which $L_{cls} (p, u) = - logP_u$
- For background RoIs there is no notion of a ground-truth bounding box and hence $L_{loc}$ is ignored
- $L_{loc}(t^u, v) = \sum_{i \in \{x, y, w, h\}}smooth_{L_1}(t^u_i - v_i)$
- All experiments use $\lambda = 1$
mini-bath sampling
- batch-size = 128
- sampling 64 RoIs from each image
- images are horizontally flipped with probability 0.5
back-propagation through RoI pooling layers
backwards function:
SGD hyper-parameters
softmax classification and bounding-box regression are initialized from zero-mean Gaussian distributions with standard deviations 0.01 and 0.001
biases are initialized to 0
scale invariance
two ways:
- “brute force” learning
- image pyramids
Fast R-CNN Detection
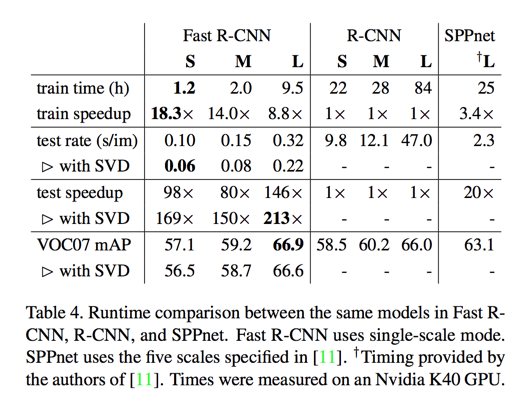
truncated SVD for faster detection
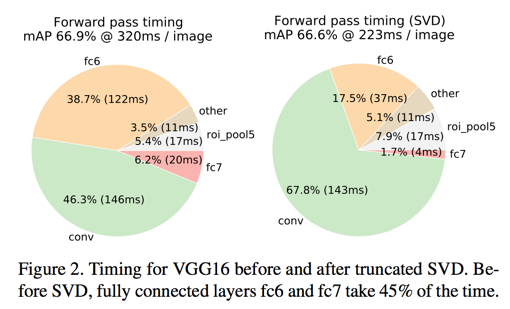
the time cost on FC is nearly half of the forward pass time
- w is u * v
- U is v * t
- $\Sigma_t$ is t * t
- V is v * t
- truncated SVD reduces the parameter count from uv to t(u + v) $t \ll min(u, v)$
Main Results
three main results:
- state-of-the-art mAP on VOC 2007, 2010, and 2012
- fast training and testing compared to R-CNN, SPPnet
- fine-tuning conv layers in VGG16 improves mAP
VOC 2010 and 2012 results
VOC 2007 results
training and testing time
truncated SVD
truncated SVD can reduce detection time by more than 30% with only a small (0.3 percentage point) drop in mAP
which layers to fine-tune
validate that fine-tuning the conv layers is important for VGG16
training through the RoI pooling layer is important for very deep nets

Question:
- Does this mean that all conv layers should be fine-tuned?
Answer:
- no
- lower layer is generic and task independent has no meaningful effect on mAP
Design Evaluation
dose multi-task training help

scale invariance: to brute force or finesse?
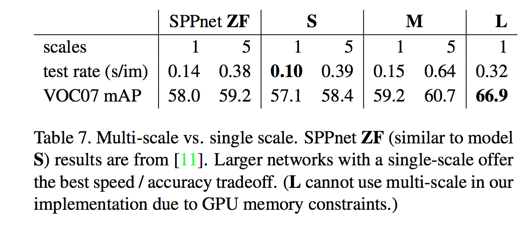
deep ConvNets are adept at directly learning scale invariance
do we need more training data?
A good object detector should improve when supplied with more training data
- roughly tripling the number of images to 16.5k
- improves mAP on VOC07 test from 66.9% to 70.0%
do SVMs outperform softmax?
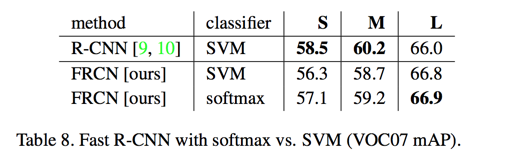
Reason:
- softmax, unlike one-vs-rest SVMs, introduces competition between classes when scoring a RoI
are more proposals always better?
- sparse set of object proposals
- dense set
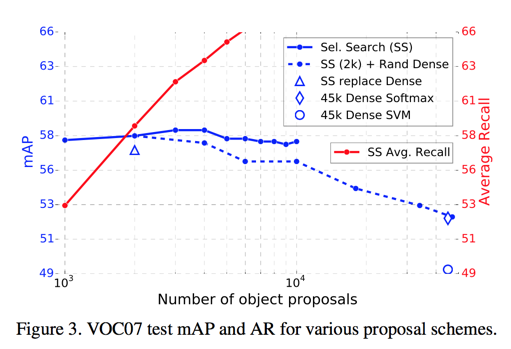
- that swamping the deep classifier with more proposals does not help, and even slightly hurts, accuracy
preliminary MS COCO results
skip
Conclusion
skip
Reference
11. K.He,X.Zhang,S.Ren,andJ.Sun.Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV,2014 ↩