总结
- 本文是按照前作20的思路继续走,寻找更加高效的计算结构
网络结构设计原则
文章提出了四点设计原则:
- 避免网络表达瓶颈,尤其是在前面几层
- 高维特征更容易处理
- 在低维嵌入上可以进行空间聚合不会或者只有少量的信息损失
- 平衡网络的深度和宽度
分解大卷积核
- 5 5 卷积和两个 3 3卷积拥有同样的接收域,但是后者的参数量和计算量都有28%的降幅且增加了网络的非线性(多了一层激活函数)
- 非对称卷积——同理将3 3 分解为 1 3 和 3 * 1也会取得较好的效果
- 实验表明在靠前的网络里这种分解方法没什么效果
辅助分类器
- 前作20中提出了辅助分类器的概念,意在更好的传递梯度
- 在本作的实验中证明了:
- 训练开始的时候辅助分类器并没什么用
- 在训练快要接近拟合的时候辅助分类器会有一些精度提升
- 移除了浅层的辅助分类器对结果没有什么影响
- 在辅助分类器上加BN会对结果有所提高,佐证了辅助分类器其实是个正则化项的说法
高效pooling
- 基于设计原则1,每次做pooling的时候会引入表达瓶颈
- 但是先将filter增大的话会加大计算量
- 基于此提出了一种新的pooling方法,convolution和pooling并行做然后将结果concat到一起
至此所有结构的变动的结果合并到一起称之为Inception-V2
标签平滑
- 本章说原始的标签值和损失函数会让模型过于自信,造成过拟合
- 新提出了一个方法,其实就是将真实分类的1拿出一个$\epsilon$来分均分到其他类别上去
- 据说有0.2%的绝对精度提升
至此,在InceptionV2基础上又增加了:
- 标签平滑
- 7 7 分解为 3个3 3
- 辅助分类器加BN
新的结构称为Inception-V3
低分辨率处理
如果输入是低分辨率图片怎么办?比如RCNN中截取出的图片
实验结论表明,高接收域的网络表现效果是最好的,也就是说不用对这种情况做什么特殊的处理
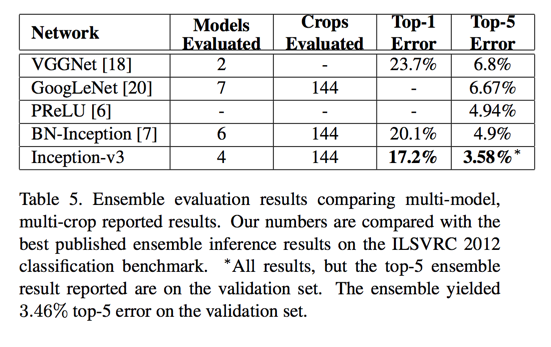
实验结果
ILSVRC 2012 数据集
- 1 model; 1 crop; top 5 error:
- v2: 6.3%
- v3: 5.6%
- ensemble(144 crops); top 5 error:
- 6 models v2: 4.9%
- 4 models v3: 3.58%
Abstract
- Here we are exploring ways to scale up networks in ways that aim at utilizing the added computation as efficiently as possible by suitably factorized convolutions and aggressive regularization
- single model: 21.2% top-1 error
Introduction
We start with describing a few general principles and optimization ideas that that proved to be useful for scaling up convolution networks in efficient ways
General Design Principles
- Avoid representational bottlenecks, especially early in the network
- Higher dimensional representations are easier to process locally within a network
- Spatial aggregation can be done over lower dimensional embeddings without much or any loss in representational power
- Balance the width and depth of the network
Factorizing Convolutions with Large Filter Size
Factorization into smaller convolutions
It seems natural to exploit translation invariance again and replace the 5 X 5 layer by a two layer convolutional architecture: the first layer is a 3 X 3 convolution, the second is a fully connected layer on top of the 3 X 3 output grid of the first layer
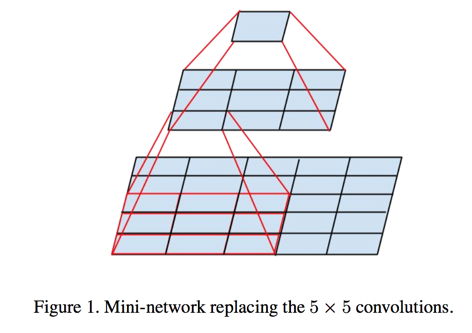
This way we end up with a net (9 + 9) / 25 X reduction of computation, resulting in a relative gain of 28% by this factorization
using linear activation was always inferior to using rectified linear units in all stages of the factorization
Spatial Factorization into Asymmetric Convolutions
Question:
- can we factorize layer into smaller, for example 2 X 2 convolutions?
Answer:
- asymmetric convolutions e.g. n X 1 is better
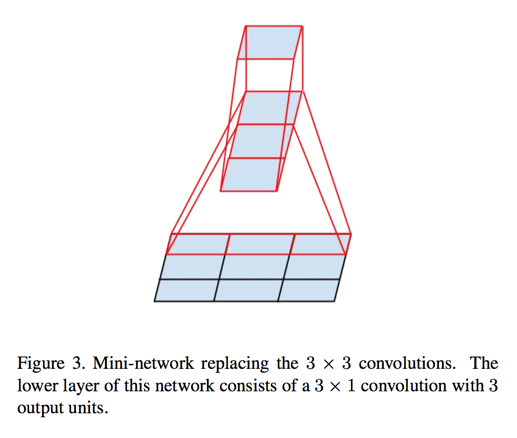
we have found that employing this factorization does not work well on early layers
Utility of Auxiliary Classifiers
- the training progression of network with and without side head looks virtually identical before both models reach high accuracy
- Near the end of training, the network with the auxiliary branches starts to overtake the accuracy of the network without any auxiliary branch and reaches a slightly higher plateau
- The removal of the lower auxiliary branch did not have any adverse effect on the final quality of the network
- we argue that the auxiliary classifiers act as regularizer
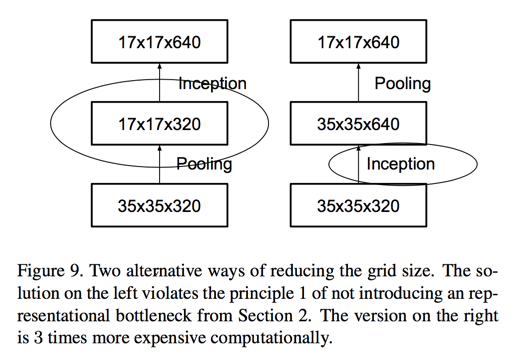
Efficient Grid Size Reduction
- pooling first then expand filters —— introducing an representational bottleneck
- expand filters first then pooling —— 3 times more expensive computationally
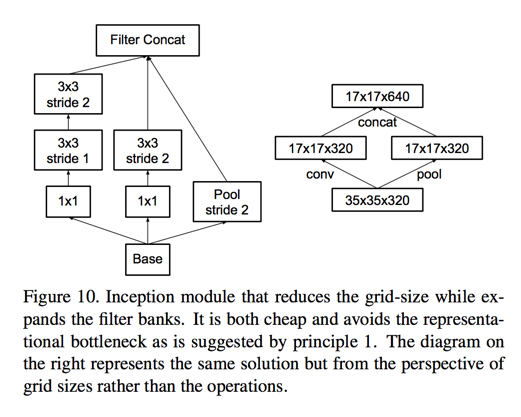
solution:
- we can use two parallel stride 2 blocks: P and C
- P is a pooling layer
- C is convolution layer
- both of them are stride 2
- concat result filter of them
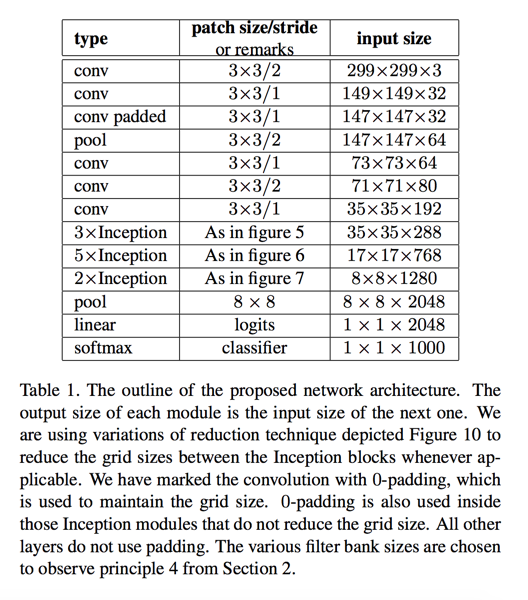
Inception-v2
Model Regularization via Label Smoothing
classic label can cause two problems:
- it may result in over-fitting: if the model learns to assign full probability to the ground-truth label for each training example, it is not guaranteed to generalize
- Second, it encourages the differences between the largest logit and all others to become large, and this, combined with the bounded gradient $\partial l / \partial z_k$reduces the ability of the model to adapt
- Intuitively, this happens because the model becomes too confident about its predictions
we replace the label distribution $q(k|x) = \delta_{k,y}$ with
we propose to use the prior distribution over labels as u(k), in our experiments, we used the uniform distribution $u(k) = 1 / K$
we refer to this change in ground-truth label distribution as label-smoothing regularization, or LSR
we have found a consistent improvement of about 0.2% absolute both for top-1 error and the top-5 error
Training Methodology
setup:
- SGD
- Tensorflow
- batch size 32
- 100 epoch
- RMSProp with decay of 0.9 and $\epsilon = 1.0$(better than momentum)
- learning rate 0.045 decayed every two epoch using an exponential rate of 0.94
- gradient clipping with threshold 2.0 was found to be useful to stabilize the training
Performance on Lower Resolution Input
The common wisdom is that models employing higher resolution receptive fields tend to result in significantly improved recognition performance.
two simple way:
- reduce the strides of the first two layer in the case of lower resolution input
- by simply removing the first pooling layer of the network
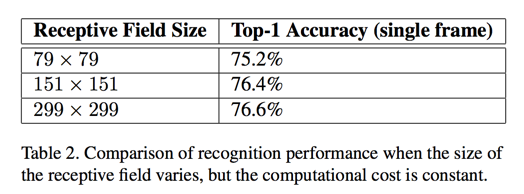
if one would just naively reduce the network size according to the input resolution, then network would perform much more poorly
Experimental Results and Comparisons
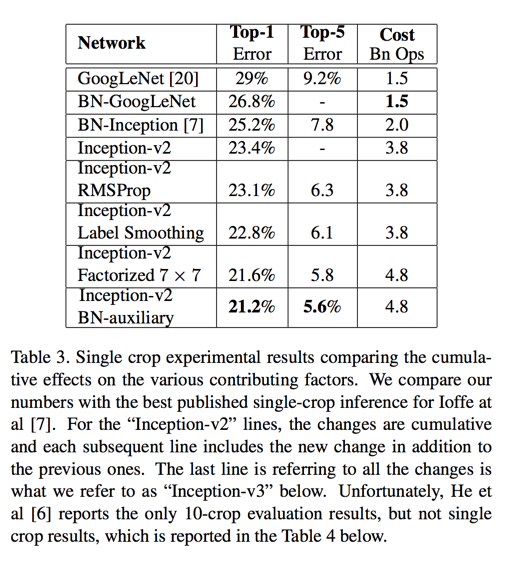
We are referring to the model in last row of Table 3 as Inception-v3
Conclusions
skip
Reference
20. C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1–9, 2015. ↩