概述
- Recurrent Neural Networks
- 用来处理序列数据
- 当前状态的输出与前面状态的输出也有关
- 目前在NLP上表现不错,目前的应用
- 文本生成
- 机器翻译
- 语音识别
- 使用最广泛的模型是LSTM——Long Short-Term Memory 长短时期记忆模型
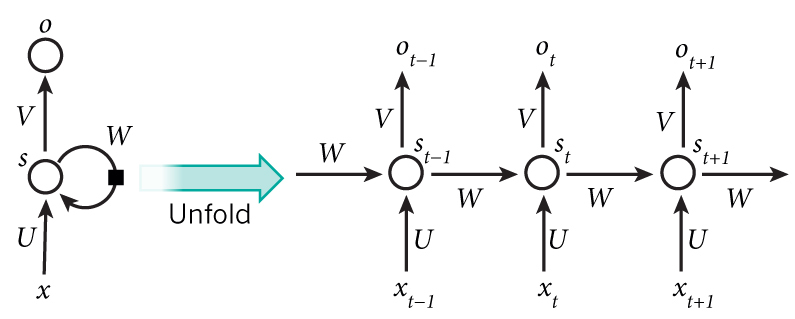
模型举例
Simple RNNs(SRNs循环网络)
三层神经网络,并在隐藏层加了上下文单元
上下文单元与隐藏层之间的链接是固定的,并且权重也是固定的
前向反馈传播
上下文节点保存上文,即隐藏层接收输入层的输出和上一时刻自己的状态
Bidirectional RNNs(双向循环网络)
当前输出不仅与之前的状态相关,还与之后的状态相关
由两个SRNs叠加而成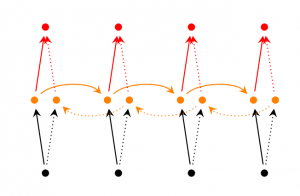
Deep (Bidirectional) RNNs(深度双向循环网络)
多层BRN
更强的表达和学习能力,所需的训练数据也更多了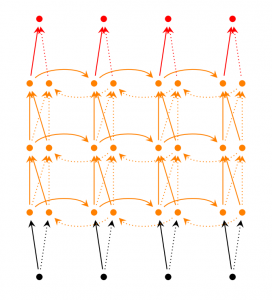
Echo State Networks
与传统RNNs相差巨大
- 核心结构是一个随机生成的且保持不变的储备池(Reservoir),储备池的链接是稀疏链接(SD 为 1% ~ 5%之间)
- 输出层的权重矩阵是唯一可变的部分
- 简单的线性回归即可完成训练
模型参数:
- $W$为储备池中节点链接的权值矩阵
- $W_{in}$为输入层到储备池之间的连接权值矩阵
- $W_{out}$为输入层、储备池、输出层到输出层的连接权值矩阵
- $W_{back}$为输出层到储备池之间的链接权值矩阵
- $W_{bias}^{out}$为输出层的偏置项
储备池参数:
- 内部连接权谱半径SR
- 储备池神经元个数N
- 输入信号连接到储备池内部神经元之间需要相乘的尺度因子IS
- 储备池稀疏程度SD
Long Short Term Memory Networks(LSTMs 长短时期记忆模型)
与RNNs相比在长间距依赖的问题上表现的更加出色
用了不同的函数去计算隐藏层的状态
隐藏层状态示意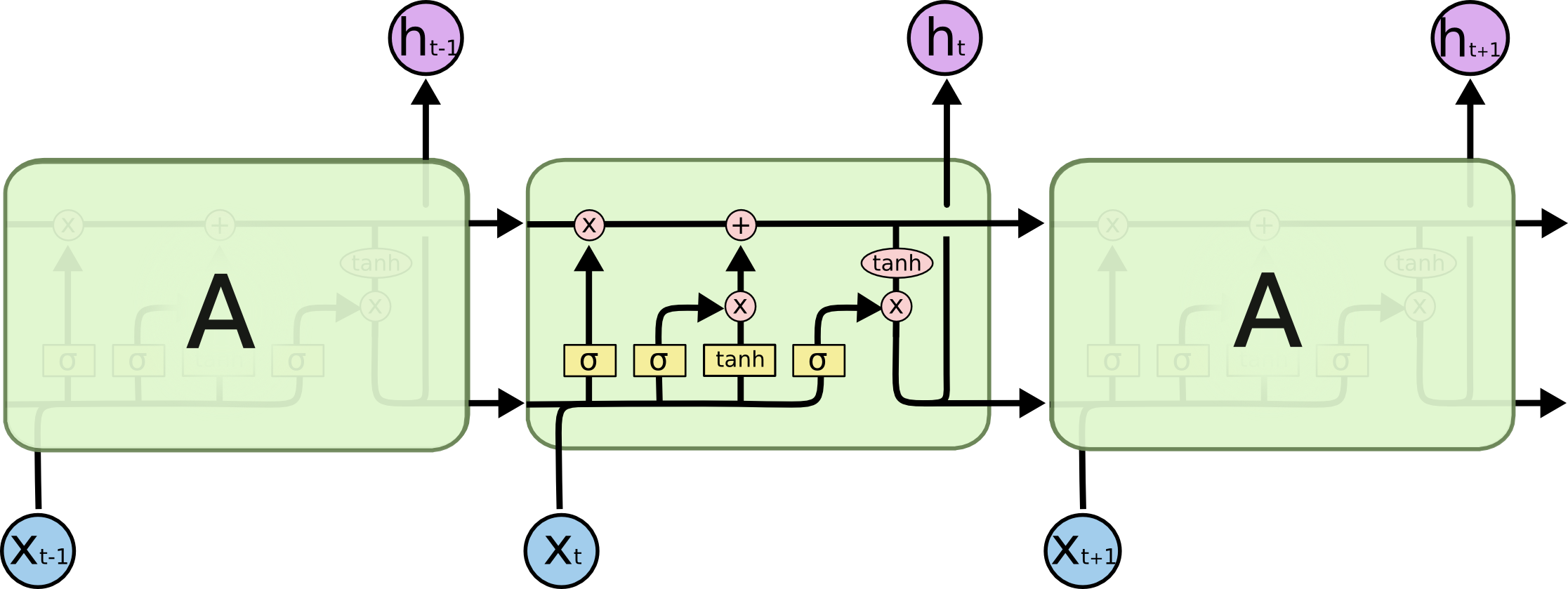

图中的$\sigma$表示sigmod函数
sigmod函数以及一个乘法操作在LSTMs中充当阀门(gate)的作用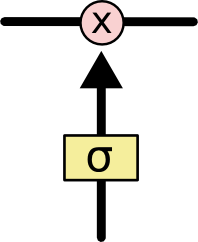
图中的$tanh$表示双曲函数
阀门可以控制增加或移除某些信息的移除
如上图所示,LSTMs总共有3个阀门
步骤分解
细胞状态——cell state就是最上面的$C$变量,是LSTMs的关键变量
计算细胞状态中旧信息筛选因子
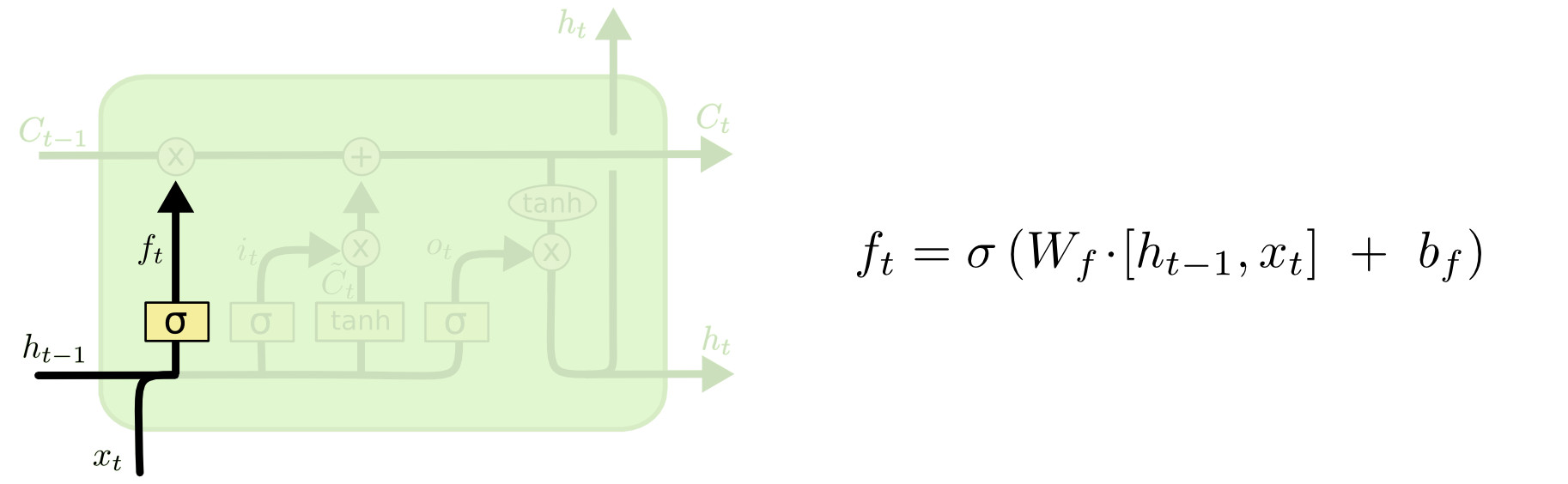
这一步主要是决定那些旧的信息需要被扔掉
通过这个操作给每个cell state中的每个数值对应的位置一个0~1的数字标识这个地方的旧数据是否需要保留
计算细胞状态中的新信息加和因子
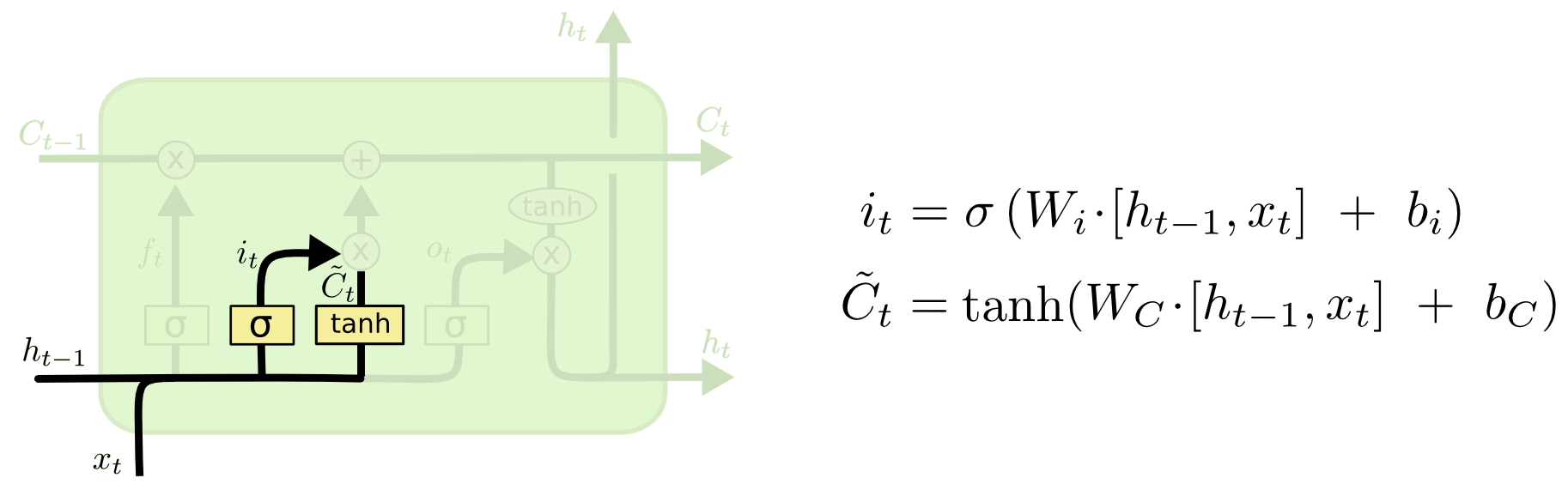
这一步主要是决定哪些新的信息要储存在cell state中
分两方面
- 第一步通过$sigmod$筛选出哪些数值需要更新
- 第二步通过$tanh$计算出另外一个乘法因子$\overset{-}{C_i}$
- 把两个结果相乘得出结果
细胞状态传递
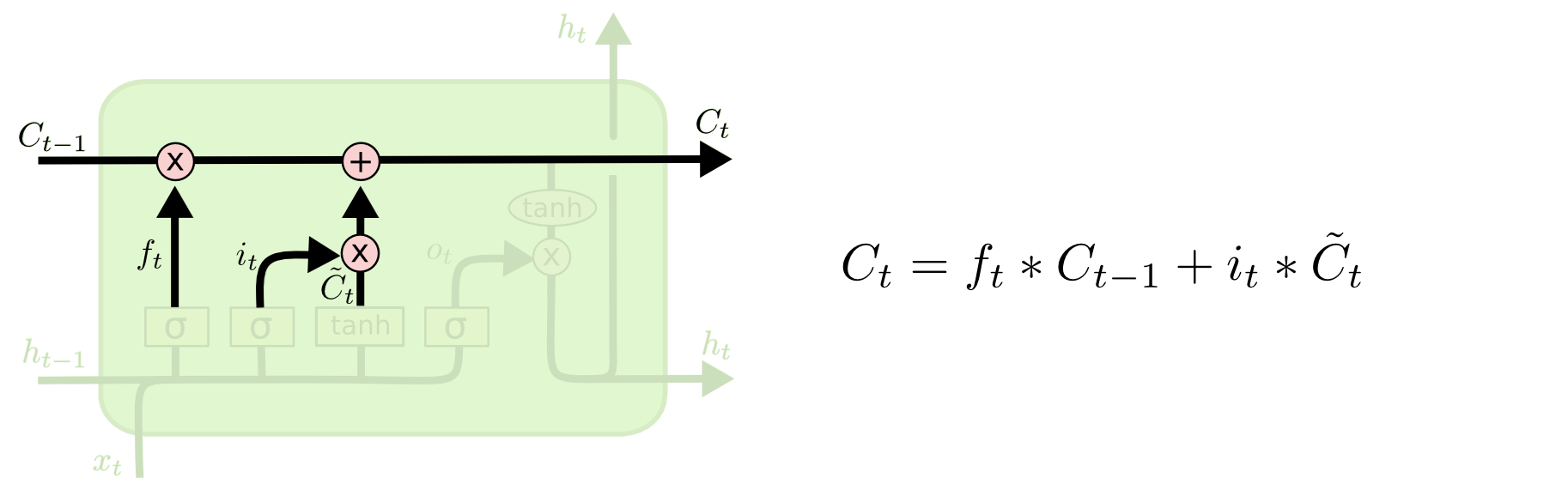
细胞状态在整个计算过程中贯穿而过只有少量的线性运算,因此这个向量保持不变就相对容易
第一个乘法运算与第一步中的筛选因子进行,筛选出保留的信息。然后与第二步计算的加和因子进行加法运算得到新的细胞状态
计算最终输出结果
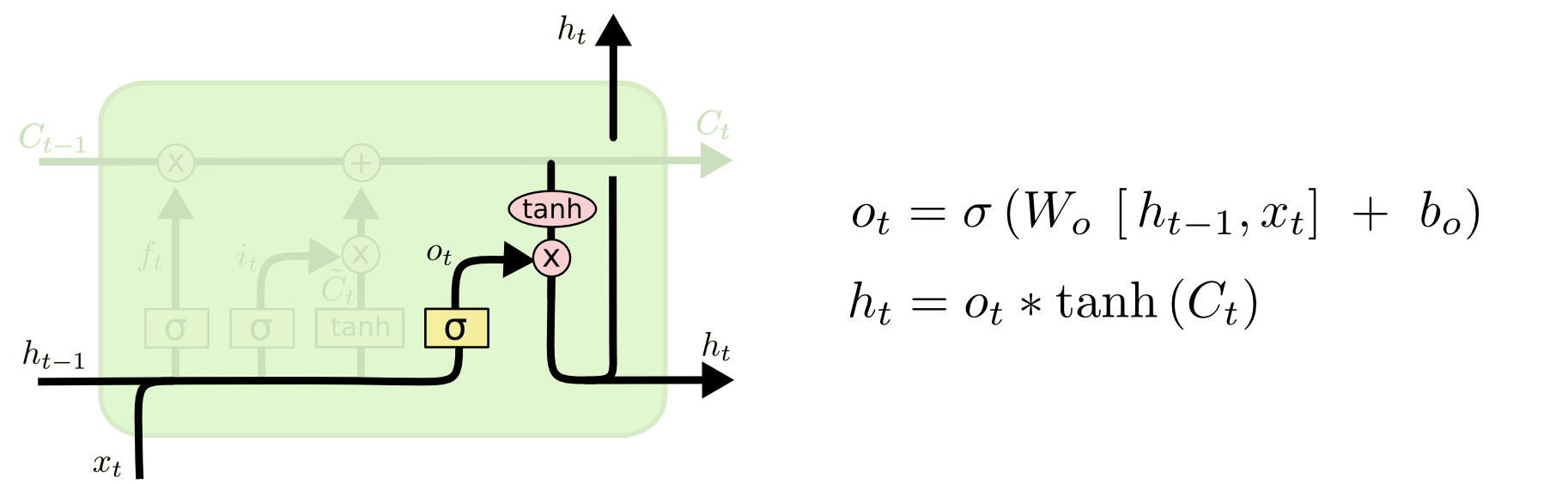
最终的输出结果是一个经过过滤器过滤的细胞状态
首先采用$sigmod$函数来决定细胞状态中的那一部分需要输出
然后将细胞状态进行$tanh$处理,将处理的结果与筛选向量相乘得到最终的输出结果
LSTMs变体
LSTMs有茫茫多的变体,只列举了比较著名的一些变体
peephole connection
由Gers & Schmidhuber在2000年提出
这个变体是在所有的阀门上加了一个通道能够直接获取细胞状态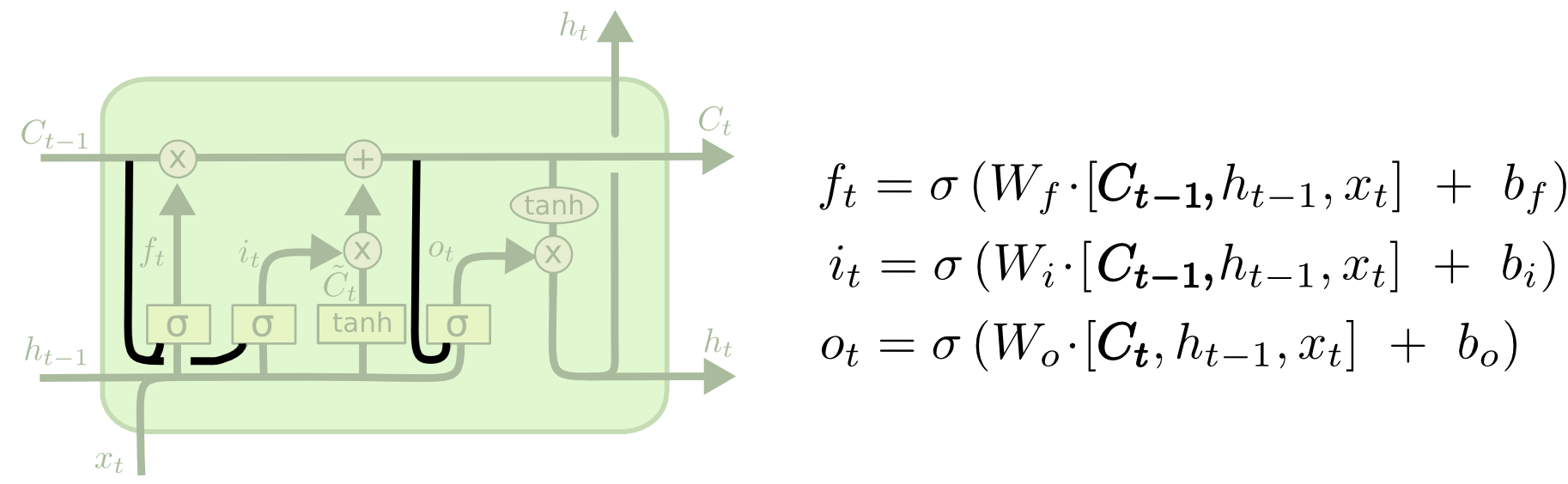
在实际应用的时候一般只加其中某些通道不是所有都加
coupled forget and input gates
这个变体是不单独计算input gates,而是直接由forget gates对偶而来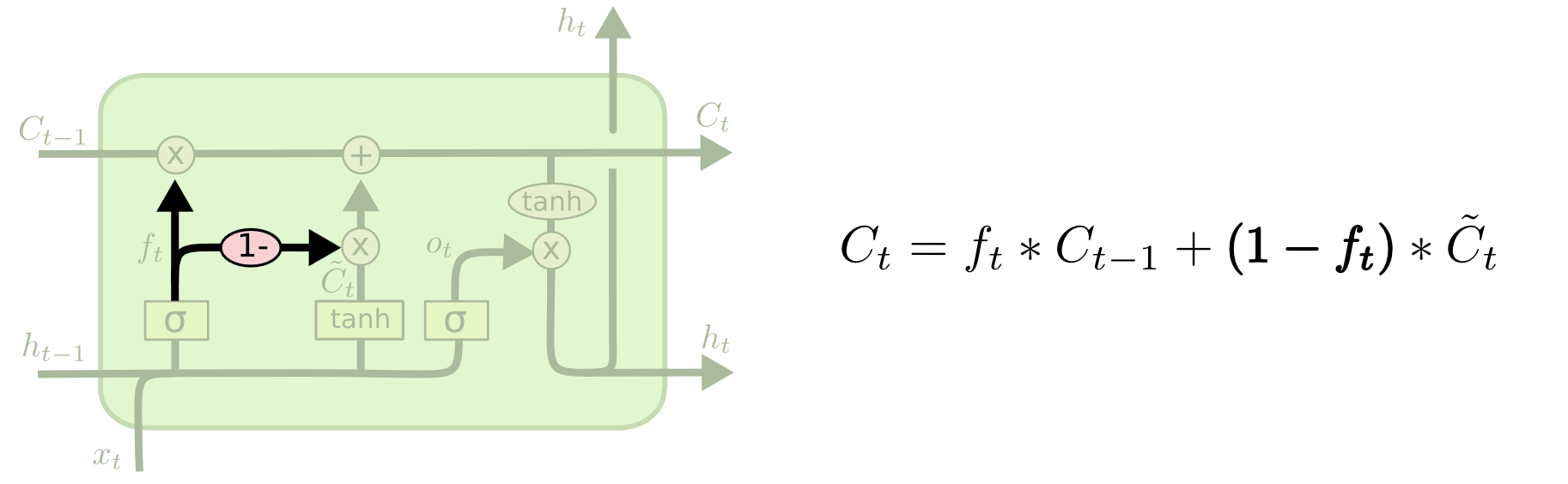
Gated Recurrent Unit Recurrent Neural Networks(GRUs)
由Cho在2014年提出
合并了input gate和forget gate,统一成update gate
将隐藏状态和细胞状态统一为了隐藏状态
不同变体之间的比较
详见论文
大多数的场景下LSTMs表现要更好
Clockwork RNNs(CW-RNNs)
论文里说效果比SRN和LSTM都要好
隐藏层会被分为若干组,每个组有等量的神经元。
里面不同组拥有不同的时间周期
每个组中的神经元是全连接的
只能周期大的神经元链接周期小的神经元