之前工作回顾
ViLT
- 把目标检测从视觉端拿掉,因为预训练的效果不好
- 将目标检测器换为patch embedding,大大降低运算复杂度,改成了目前这种轻Encoder重模态融合的形式(先tokenized然后传给transformer)
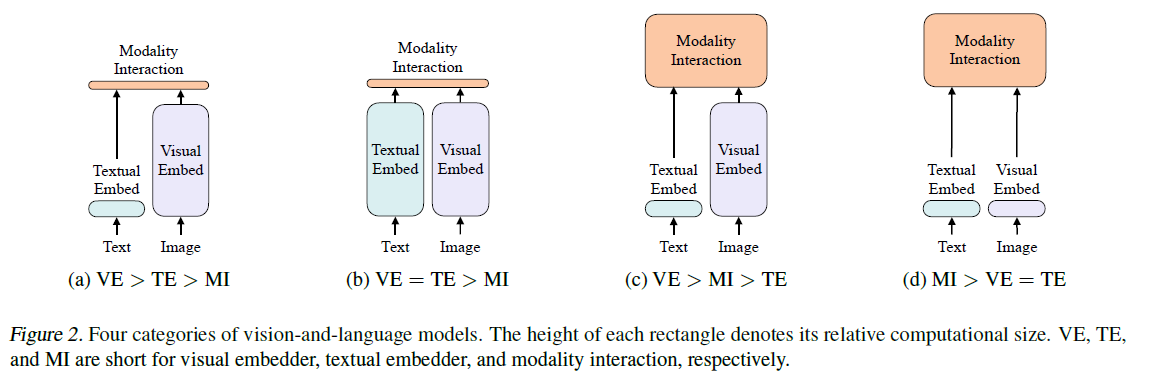
- VILT的缺点
- 性能不如C类方法(VilBert),经验来看视觉模型要比文本模型要大。另外一个原因是图片模态的初始化比较随机
- 推理快但是训练很慢(使用WPA Loss)
- ALBEF就是解决上面的问题
CLIP
- CLIP属于B类模型,双塔结构,后面交叉是通过点乘交叉,很高效但是只擅长图文匹配的任务,对于其他任务的处理就没有那么好了
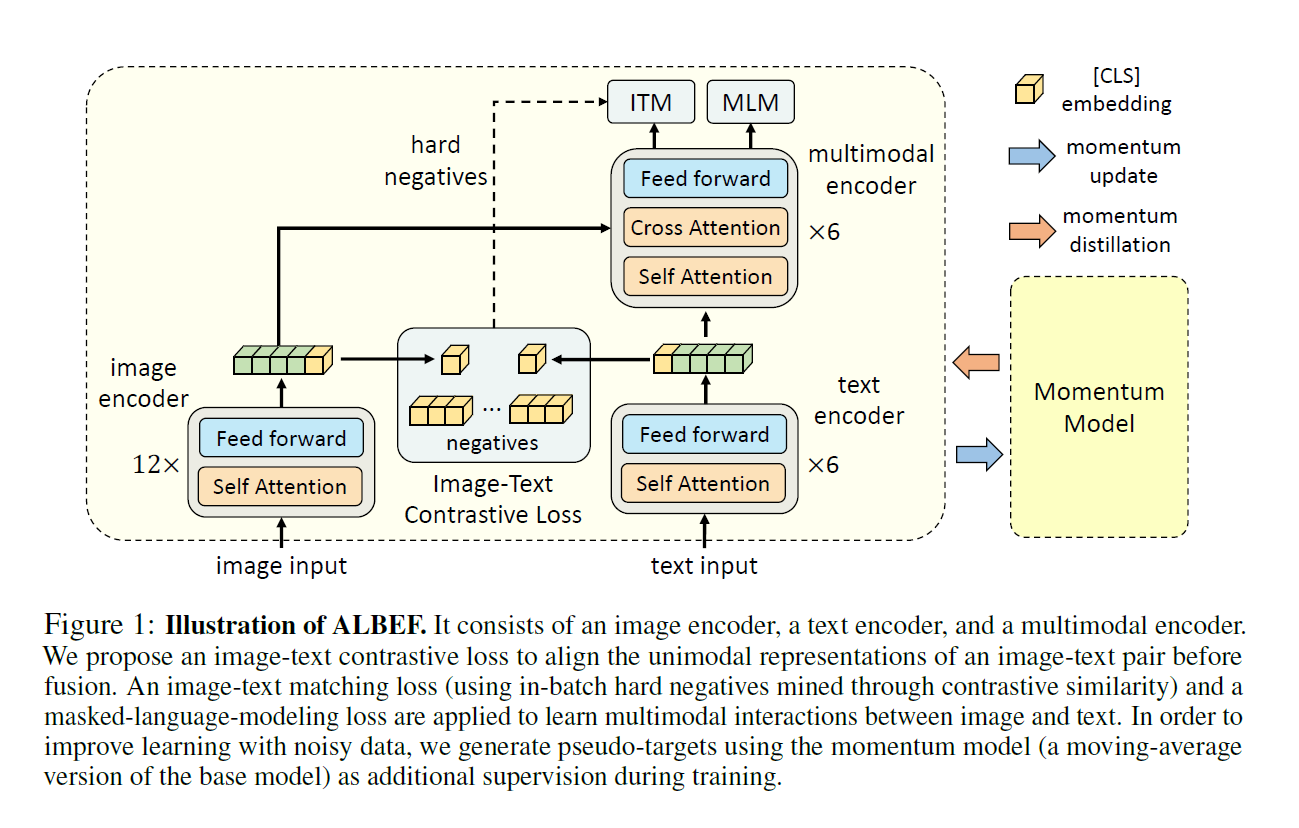
ALBEF
- 图像模态应该大点&Fusion很重要,所以大体长成C类的样子
- 损失函数ITC + MLM + ITM的融合,这几个损失函数都是之前效果比较好的
- ALBEF模型结构
- 图像编码器是12层的encoder
- 文本的编码器是2个6层encoder,前6层是文本编码器,后面6层是作为融合编码器
- 这样设计就达到了图像比文本复杂且融合模态也较为复杂这两个需求
总结
- 以往的多模态工作图像侧的特征都是通过一个预训练好的目标检测器抽取的,没有经过e2e的训练,导致交叉部分不太好学,所以想在fuse之前就做align,具体的方法是通过一个对比学习的方式
- 抛弃目标检测器和对图像高清的要求(和CLIP,VILT一样)
- 通过momentum distillation的方式去学习网上noisy的样本(网上的内容通常文本并没有很精确的去描述图像,而是偏向于搜索属性),具体方法是训练momentum model去生成pseudo label使用,从而达到自训练的目的
- 用多种损失函数其实是对同一个图像文本对生成不同的视角,也可以算作是一种data augmentation
- 训练代价低,8卡机三四天的训练量
- momentum model其实就是基础模型通过moving average不断更新的结果,机制类似于MoCo
损失函数
- 损失函数是ITC、ITM、MLM的加和
ITC
- 以图像侧为例,过ViT之后得到embedding取其中CLS部分(768 1)作为全局特征,然后downsample(256 1)并且normalization。文本也一样。
- 负样本存在queue里面,很大(6w+),不算梯度
- 正负样本算cross entropy loss
ITM
- 二分类任务,把融合特征过FC层判断两个模态是不是一个对
- 判断负样本难度比较低,所以加了负样本的筛选逻辑即使用ITC的相似度高的当做负样本,使得分类难度大大增高
MLM
- 文本部分Mask一部分,然后过融合模型得到结果去预测,和bert不一样的是借助了图像的信息
- 用了这个loss意味着对于每个样本要过两次模型,一次是原始图像文本对,另一次是图像和mask之后的文本的配对,这也是多模态的方法普遍训练时间比较长的原因
动量蒸馏
- 网上爬的数据总体噪音比较多,直接用简单的one hot label对ITC和MLM很不友好。通过self training去解决这个问题,构建momentum model,生成pseudo label(score)给主网络学习(KL散度)。改进后的损失函数是两者的加权融合
常见多模态任务
- Image-Text Retrieval,图片文本检索任务
- Visual Entailment,判定图文关系,三分类:entailment蕴含,neutral中立,contradictory矛盾
- Visual Question Answering,视觉问答,给定一个图片给定一个问题(文本),看是否能够回答这个问题
- Natural Language for Visual Reasoning,视觉推理,判定一个文本能否用来描述一对图片
实验
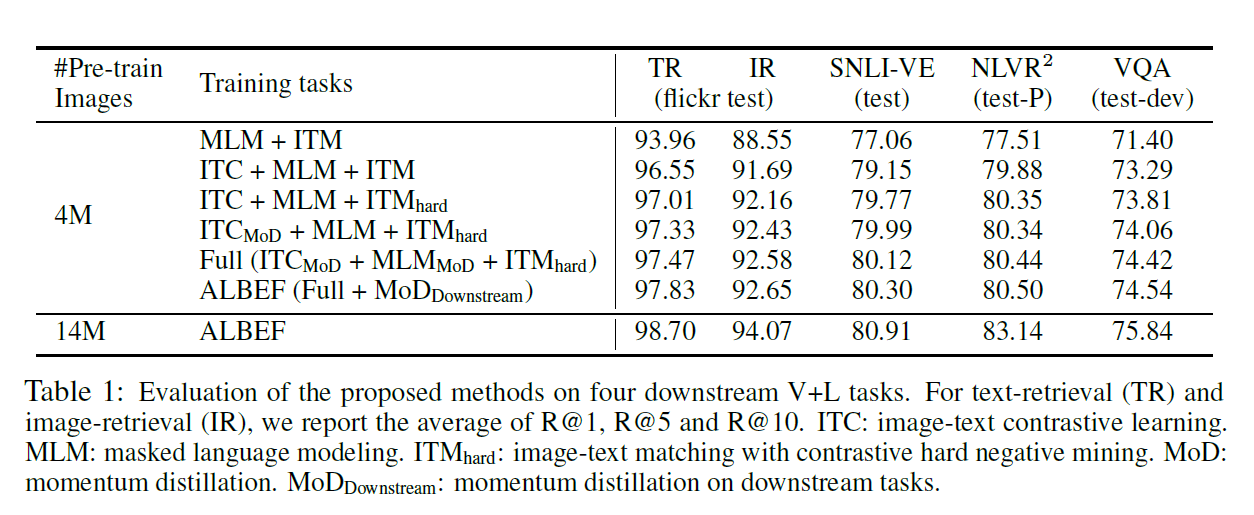
- ITC提升巨大而且全面
- hard negative也比较有用
- momentum distillation的作用不是很大
VLMo
- 模型结构改进:
- 以往的方式比如双塔(dual-encoder,例如CLIP),直接在最后算cos similarity,适合检索任务。但由于交叉较浅,在一些比较难的任务上表现不好
- 相对应的就有单塔(fusion-encoder)的工作,性能好但是在检索场景推理时间很慢
- Mixture of Modality Expert应运而生,取两者的优点进行应用
- 训练方式改进:
- 视觉和图像都有各自比较大的数据集,但是多模态的数据集当时还比较小
- 所以打算分阶段各自模态去训练,然后放在一起多模态训练
模型
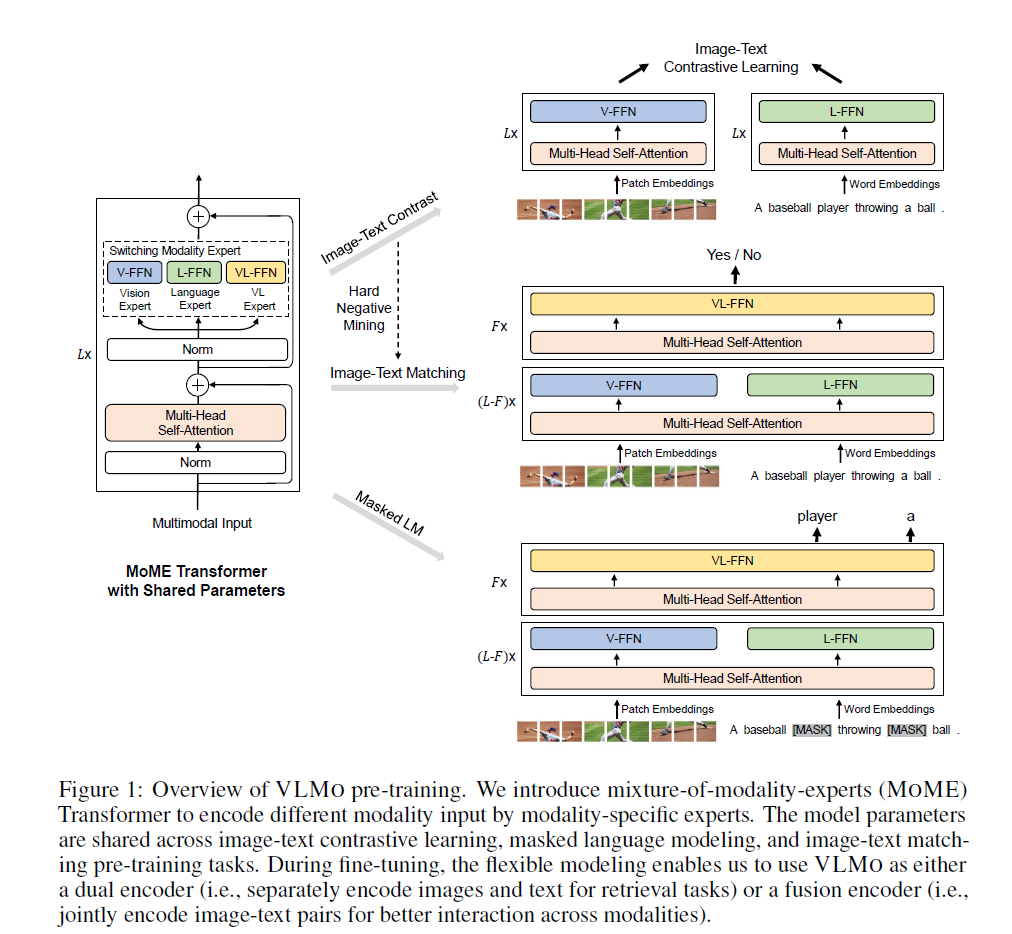
- 将原始transformer里面的Feed Forward Network按照模态分成了三份:V、L、VL
- 但是需要注意的事前面的MSA层是各个模态共享参数的,可以看到自注意力这个机制还是很泛化的
- loss和ALBEF一样是三部分组成,其中ITM也是用了ITC的negative优化。在算不同的loss的时候最后的FFN用不同的模态版本,使得整个网络来回变形
- 相应训练的成本会高,64张V100训练两天,慢于ALBEF
训练流程
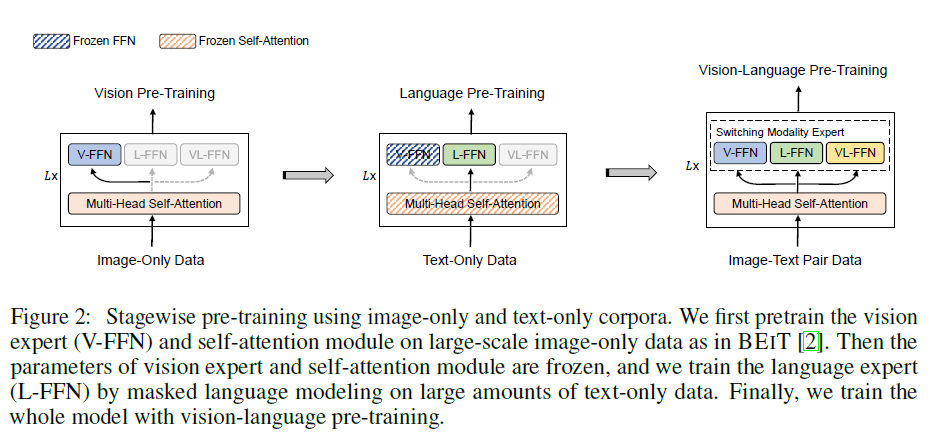
- 三阶段训练
- Mask Image Modeling训练图像
- Mask Language Modeling训练文本,值得注意的是在做这一步训练的时候MSA是冻结不训练的,这样效果很好(但是反过来不行)当做经验记下来就行
- 三个损失函数一起联合训练图像和文本
实验
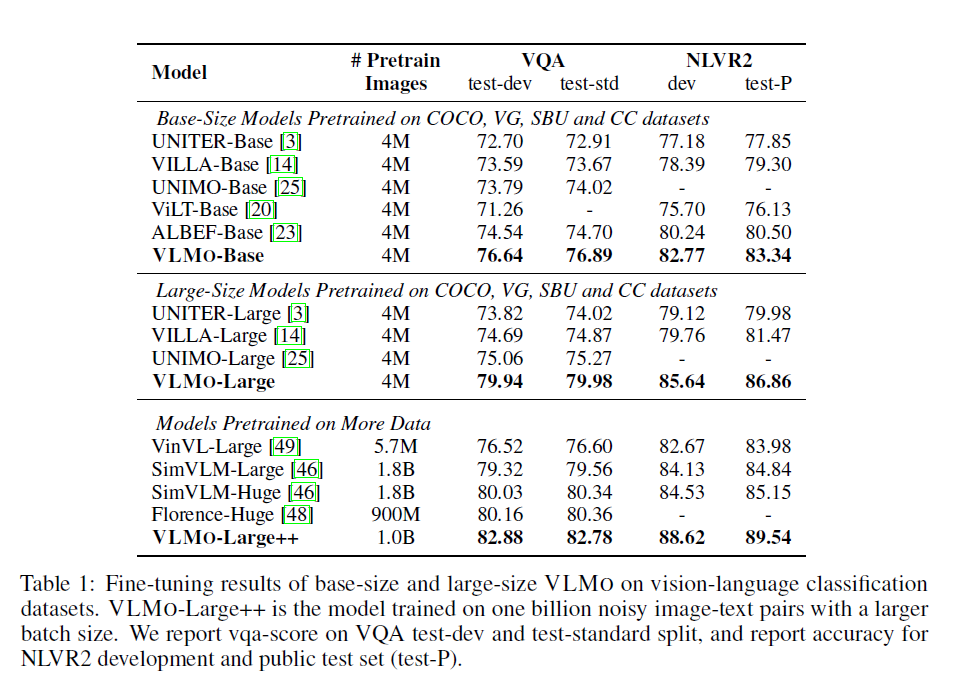
- 全线超越ALBEF
BLIP
- 两个主要的贡献点:
- Bootstrapping,从数据集角度出发,用有噪声的数据两阶段训练模型,类似于蒸馏
- Unified,从模型角度出发,统一内容理解和生成
- 也是salesforce的文章之前写过ALBEF
引言
- 以往的模型要么是encoder结构要么是encoder加decoder的结构,如果只有encoder的话是没办法做生成任务的(图像生成字幕);反之如果是encoder加decoder的架构那么他又没办法直接做理解的任务(图文检索)。这个有点像VLMo的意思,想用一个模型干所有事。
- 以往的模型大多数用网络上的数据训练,噪音很大,只是数据集的大小掩盖了这个问题。
- 设计一个captioner,即给网上图片生成描述
- 设计一个filter,给网上图文数据(其中也包括我们生成出来的数据)判定相关性,只有相关性比较强的才能用于模型训练
模型
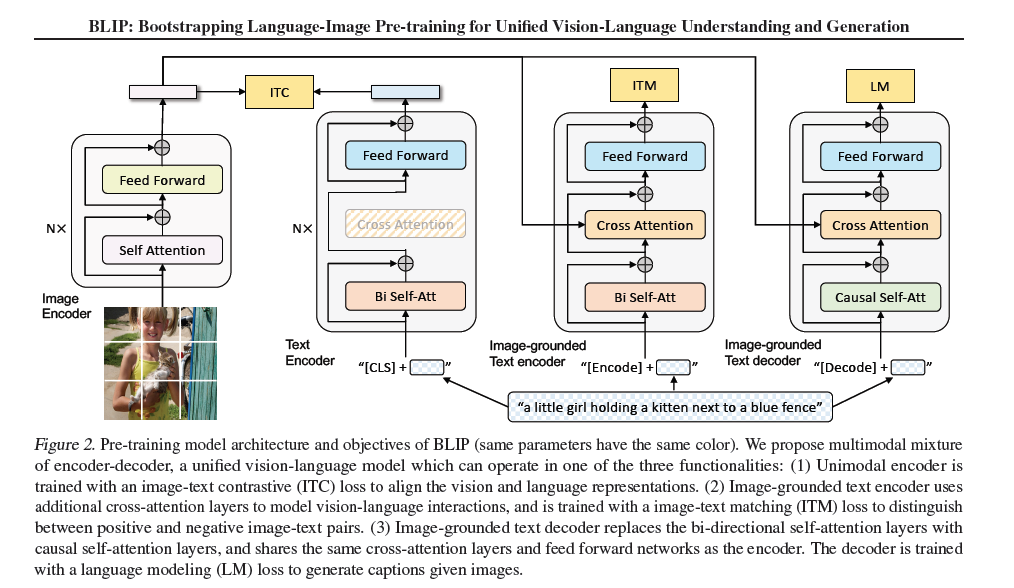
- 总体的框架是结合了ALBEF和VLMo,模型分为四个部分
- 图像模态是一个标准的N层ViT模型
- 文本模态是分为三个模型
- 第一个是N层encoder
- 第二个是一个加了cross attention的encoder。至此基本和ALBEF就很像了,主要的区别是通过共享参数而不是分割文本模态塔的方式去减小计算量
- 第三个是一个加了cross attention的decoder 去做生成任务(LM任务),self attention层也有了变化,是causal的self attention,用于因果推理,没法和之前的模型共享参数
- 三个文本模型的前面加不同的token
- 和VLMo相比就是把mixture of experts换成了mixture of encoder and decoder,所以也可以称为MED模型
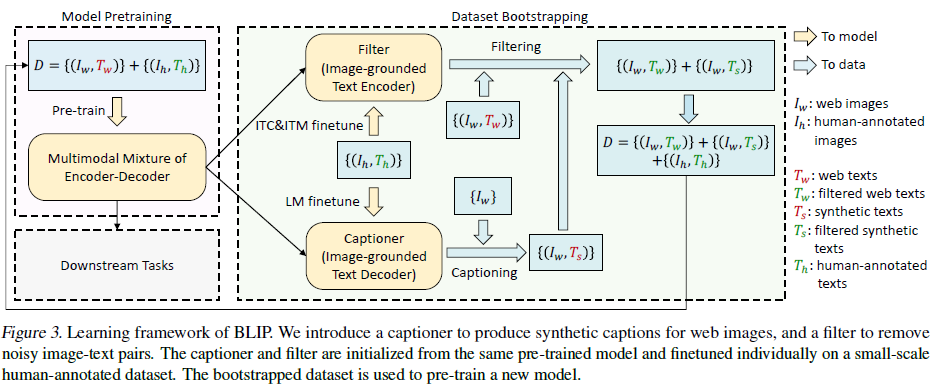
- cap filter model
- 目前训练模型所使用的数据集通常是网络上的数据集和人工标注的高质量的数据集的混合,网络数据不干净对训练有影响,需要改进
- 所使用的的方案是把混合训练好的MED拿过来再用人工标注的数据finetune一下,分别用作filter和captioner
- 用captioner生成图片对应文本交给filter一并去清洗
- 最后的数据集是由清洗过后的网络数据、人工标注数据、清洗过后的生成数据三部分组成
- 模型提升非常显著
实验
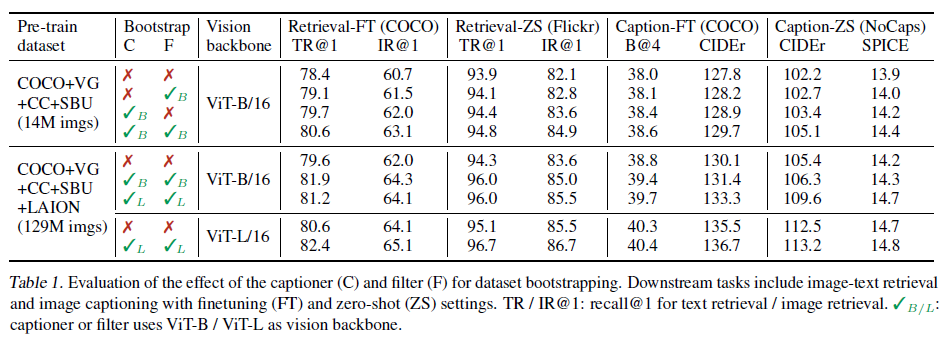
- 分别把模型和数据冻住做控制变量的观察
- capfilter模块可以单独拿出来用,用不同大小的模型,应用到不同的下游任务,效果很好,这个有很多应用(比如Laion超大规模数据集),可以当做一个思考的范式。
CoCa
- 从题目中可以看出,CoCa主要是由两部分组成
- Contrastive Loss
- Captioner Loss
- 模型大(2.1B参数量,在多模态模型里面算很大的),数据多(几B的训练数据),效果强
模型
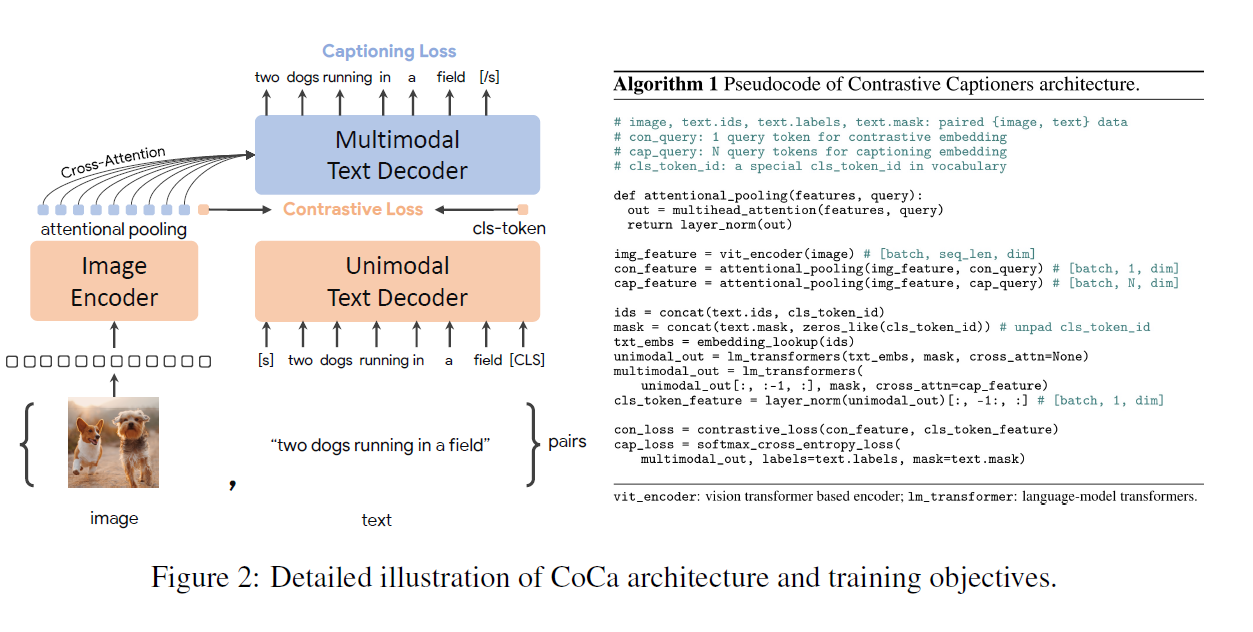
- 和ALBEF长得很像,主要区别:
- 用attentional pooling,这种pooling方式可学习
- 文本端都用decoder,主要是由于之前ALBEF设计的时候引入MLM需要计算多次,所以作者使用了另外的一个不需要计算多次的Loss。具体方案是舍弃全文本的输入,一开始就是masked输入。这样整个网络训练一个样本就只需要做一次forward。同时因为所使用的数据集比较大,所以用masked输入的副作用会小一些
实验
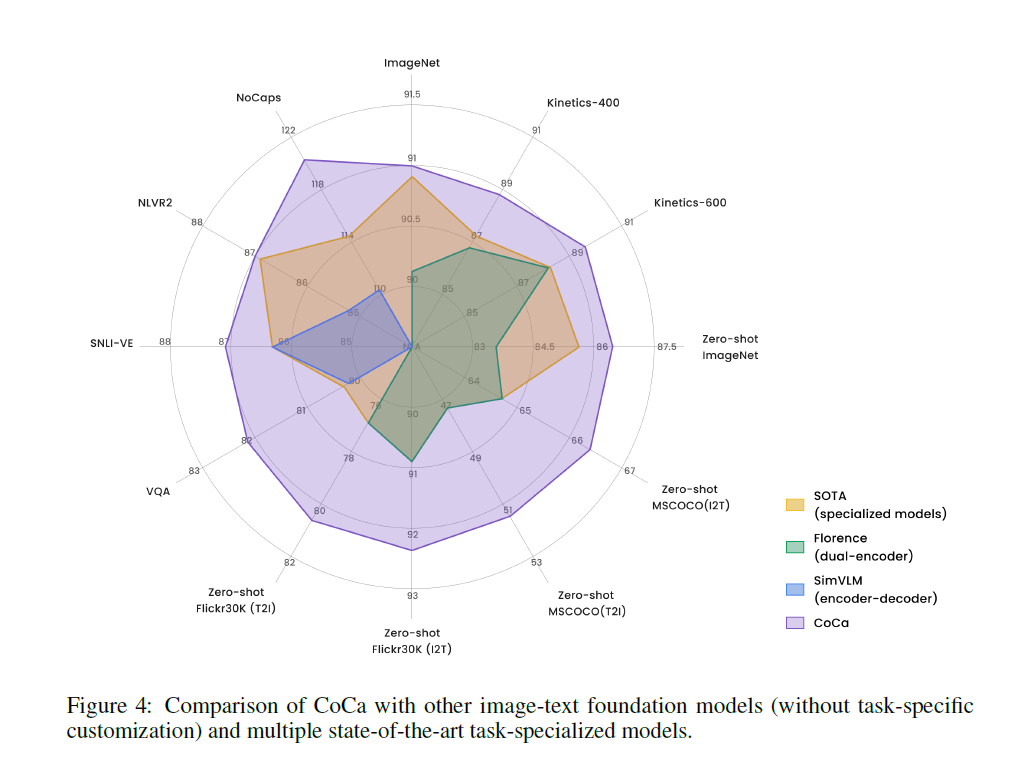
- 视觉效果和实际效果都非常炸裂
BeiTv3
- 做大一统框架
- Loss统一:使用Mask Language Modeling去做
- 模型统一:基于之前VLMo中提出的MoME(Mixture of Multi Experts),提出新的Multi Way Transformers
- 这个模型训练用的数据集都是公开数据集,总数据量比CoCa小很多,质量很关键
实验
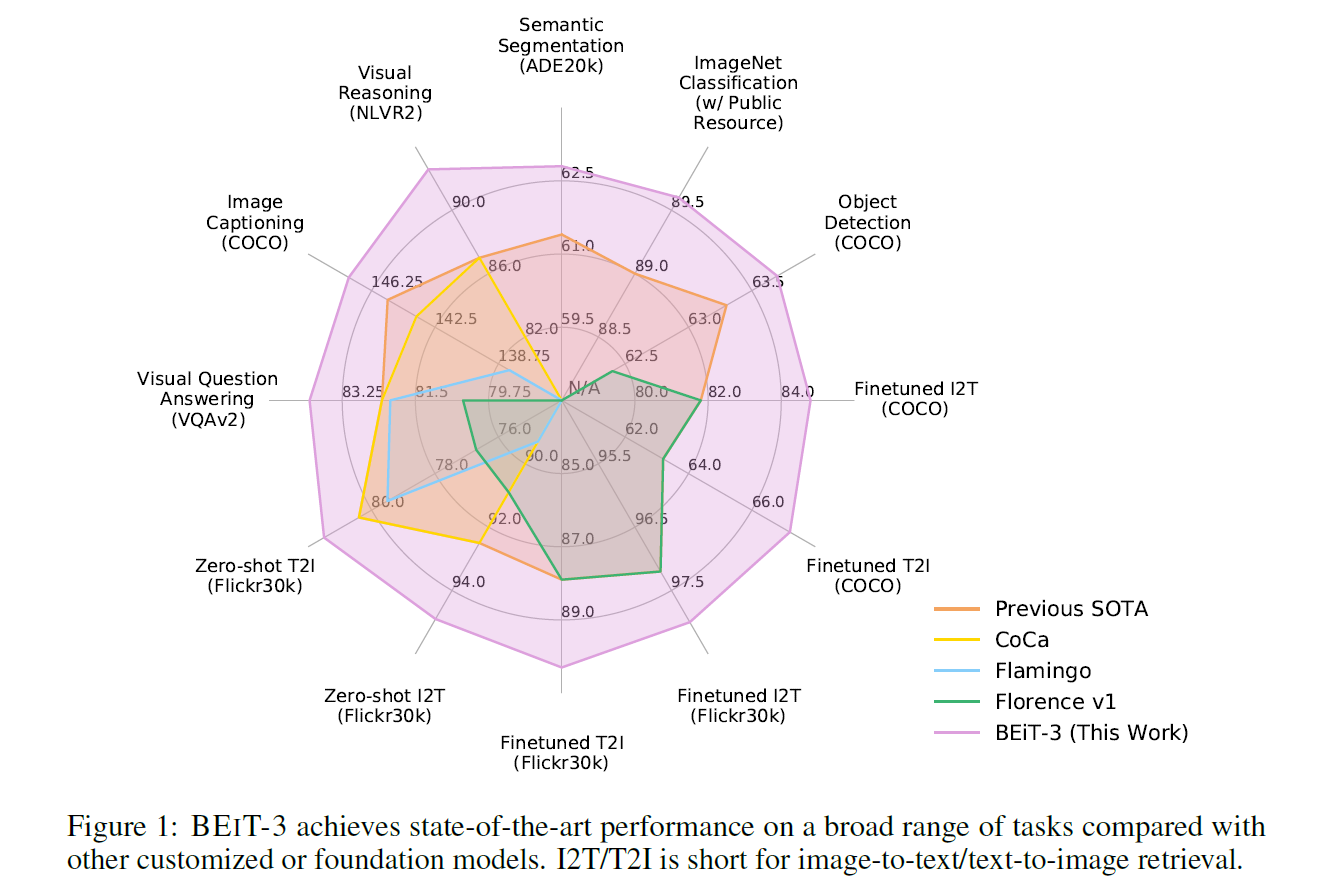
- 比MoCa强了一圈
模型
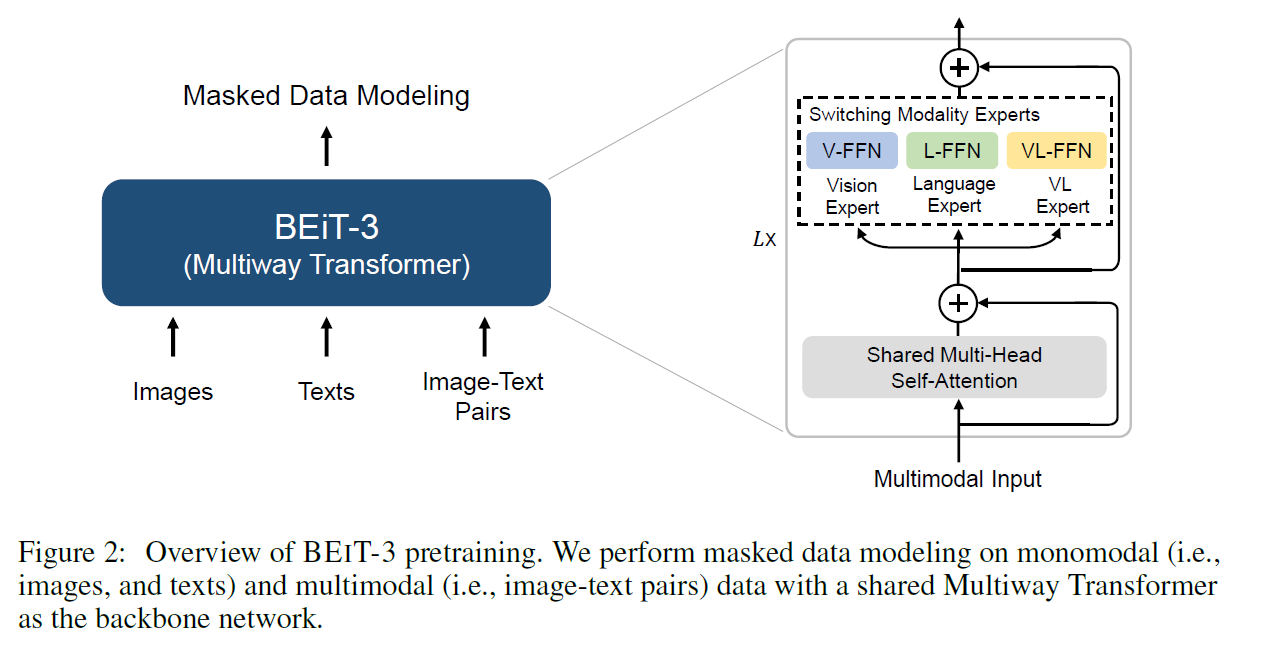
- 和VLMo是一样的,只不过损失函数只有一个Mask Language Modeling
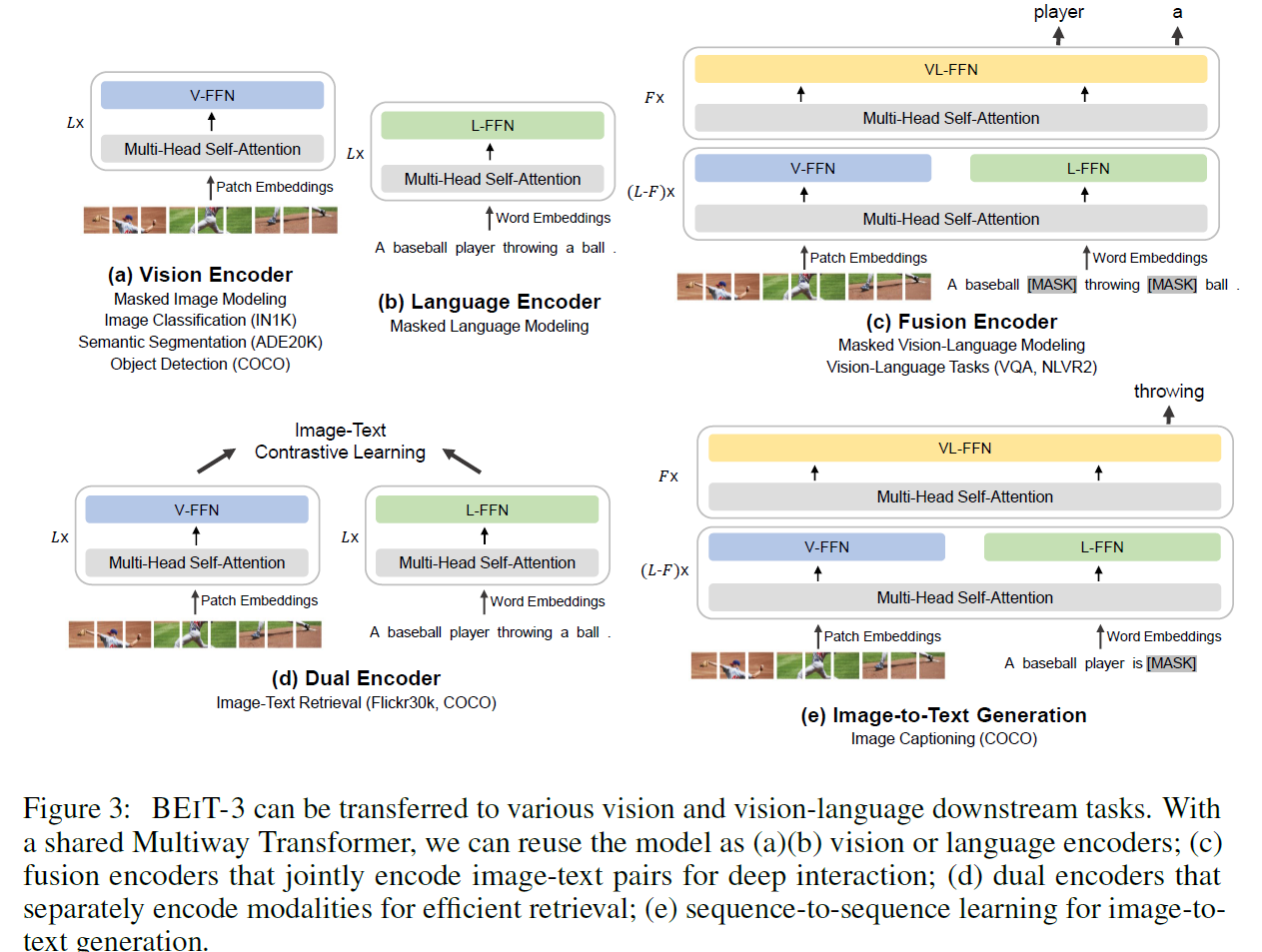
- 使用起来非常灵活
整体迭代路径
- Base:用detection去处理图像侧的模态
- ViLT:将原本Base中detection部分替换为ViT中的transformer部分,大大简化了模型结构
- ALBEF:
- 基于Base、ViLT、CLIP
- 吸收了CLIP的高效、Base的fusion性能优点、VilT中transformer的简单结构
- 提出了ITC、ITM、MLM三种Loss混合使用
- 双塔Encoder,把文本塔切为两部分,后一部分用于fusion建模
- 动量蒸馏,做pseudo label
- VLMo:
- 基于VILT、ALBEF
- 设计了多重FC去灵活切换,用于不同任务
- 分阶段训练各个FC,以应用更多的数据集
- BLIP
- 基于VLMo、ALBEF
- 在attention层去分多类处理数据;参数共享
- 提出capfilter训练范式,生成、蒸馏数据
- CoCa:
- 基于SimVLM、ALBEF
- 使用contract和caption loss训练,使得每次训练网络只推理一次,高效
- BEiT
- 基于ViT、BERT
- 继续探索mask modeling在图像模态的应用
- VL-BEiT
- 基于BEiT、BERT
- 将视觉、文本模态融合
- BEiTv3
- 基于VL-BEiT、VLMo、BEiTv2(纯视觉)
- 融合前面的工作,效果最强
- MAE
- 基于ViT、BEiT
- mask对象由patch换为pixel
- 只用没有mask的部分进行训练,加快训练速度
- FLIP
- 基于CLIP、MAE
- 把MAE中只用没有mask部分数据的思想应用到CLIP上