总结
- 本文提出了TSN方法,将视频分段,每个段中随机采样帧/光流进行训练,用来解决传统方法对于长视频训练乏力的问题
- 在网络的输入方面,除了two-stream的RGB路和optical flow,TSN尝试了RGB diff和warped optical flow等多种方式,最终是使用RGB + optical flow + warped optical flow的效果最好
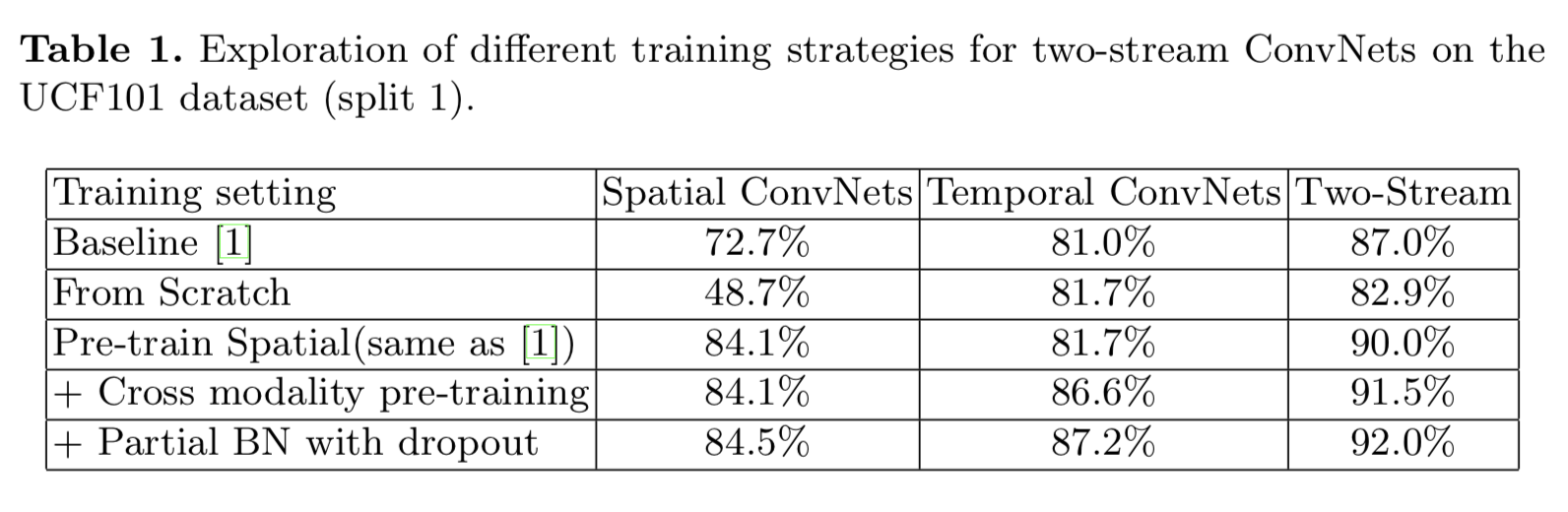
- 训练方面使用了几种方案降低过拟合
- pre-train,不仅对RGB,对其他路也用pre-train做初始化
- 冻结BN,加大dropout
- scale jittering
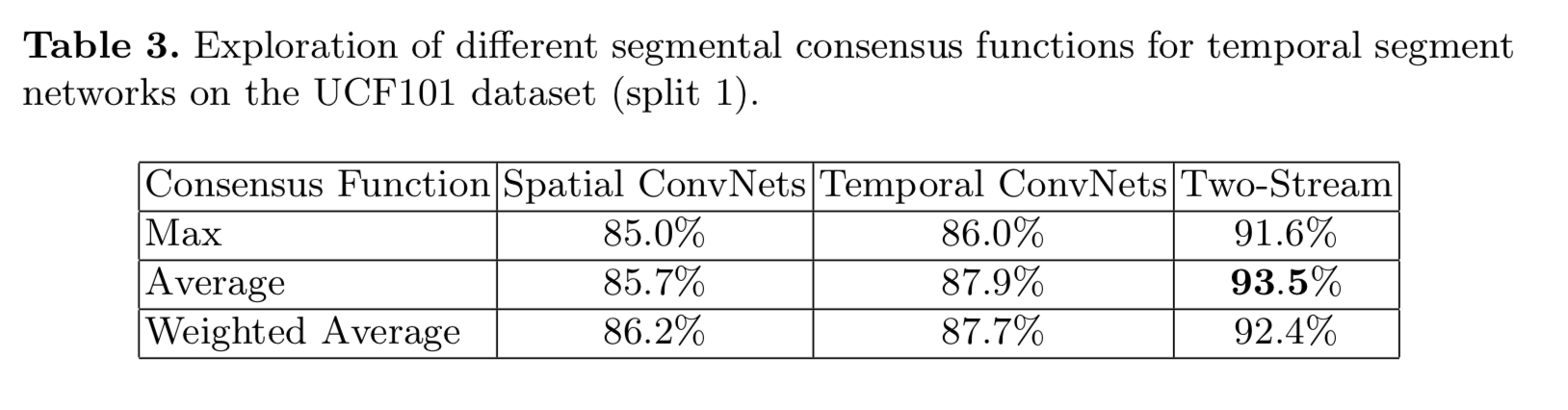
- 测试了多帧融合的方法,在max,avg,weighted avg中做选择,综合选取了avg方法,但是RGB单路中使用weighted AVG效果最好
Abstract
This paper aims to discover the principles to design effective ConvNet architectures for action recognition in videos
- Our first contribution is temporal segment network (TSN)
- The other contribution is our study on a series of good practices in learning ConvNets on video data with the help of temporal segment network
Introduction
In action recognition, there are two crucial and complementary aspects:
- appearances
- dynamics
The application of ConvNets in video-based action recognition is impeded by two major obstacles:
- First, long-range temporal structure plays an important role in understanding the dynamics in action videos.However, mainstream ConvNet frameworks lacking the capacity to incorporate long-range temporal structure
- Second, training deep ConvNets requires a large volume of training samples to achieve optimal performance
These challenges motivate us to study two problems:
- how to design an effective and efficient video-level framework for learning video representation that is able to capture long-range temporal structure
- how to learn the ConvNet models given limited training samples
TSN:
- This framework extracts short snippets over a long video sequence with a sparse sampling scheme
- a segmental structure is employed to aggregate information from the sampled snippets
To Solve shortage of training sample problem:
- pre-training
- regularization
- enhanced data augmentation
Related Works
skip over
Action Recognition with Temporal Segment Networks
Temporal Segment Networks
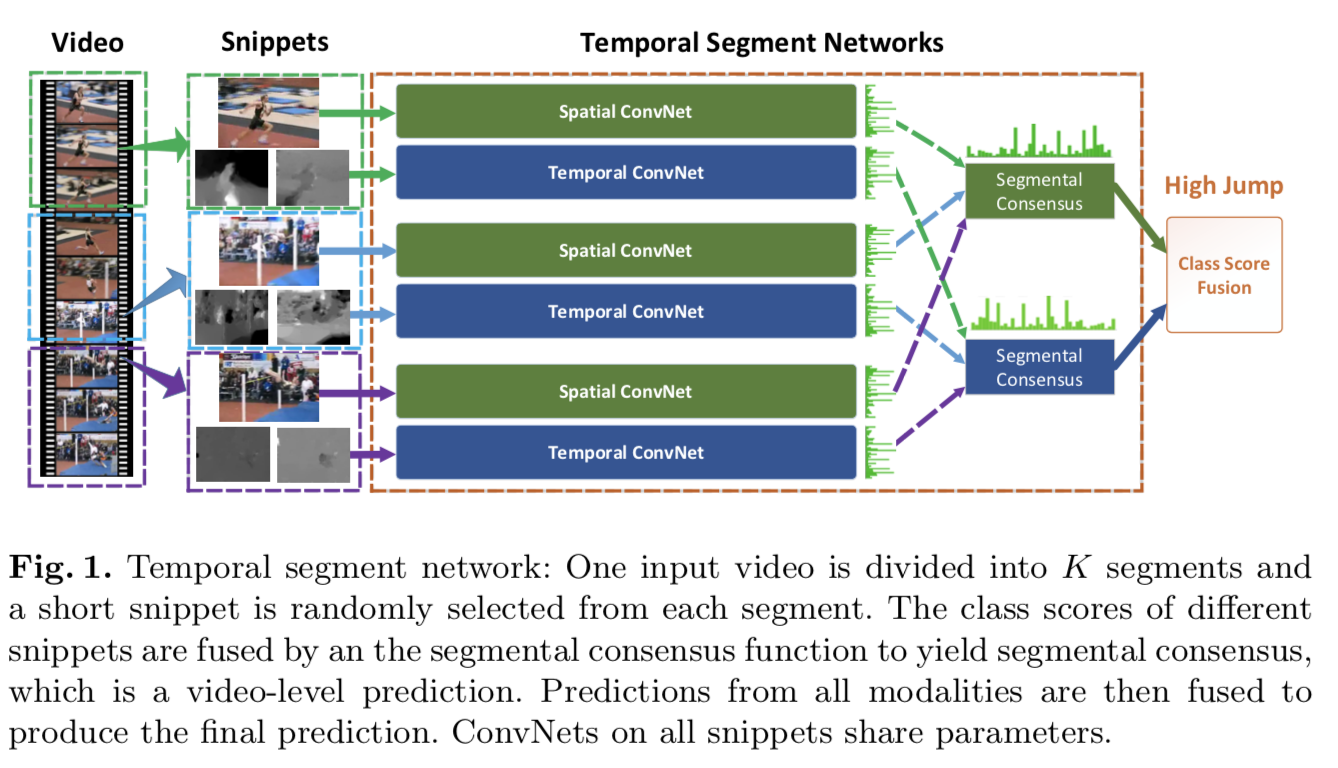
Given a video V , we divide it into K segments $\{S_1, S_2, · · · , S_K\}$ of equal durations
Which:
- $T_k$ is randomly sampled from its corresponding segment $S_k$
- $F(T_k;W)$ is the function representing a ConvNet with parameters W which operates on the short snippet $T_k$ and produces class scores for all the classes
- the segmental consensus function G combines the outputs from multiple short snippets to obtain a consensus of class hypothesis among them
- the prediction function H predicts the probability of each action class for the whole video
In practice:
- we choose softmax function as H
- In experiments, the number of snippets K is set to 3 according to previous works on temporal modeling
- we choose evenly average function as G
Learning Temporal Segment Networks
Network Architectures
The deeper, the better
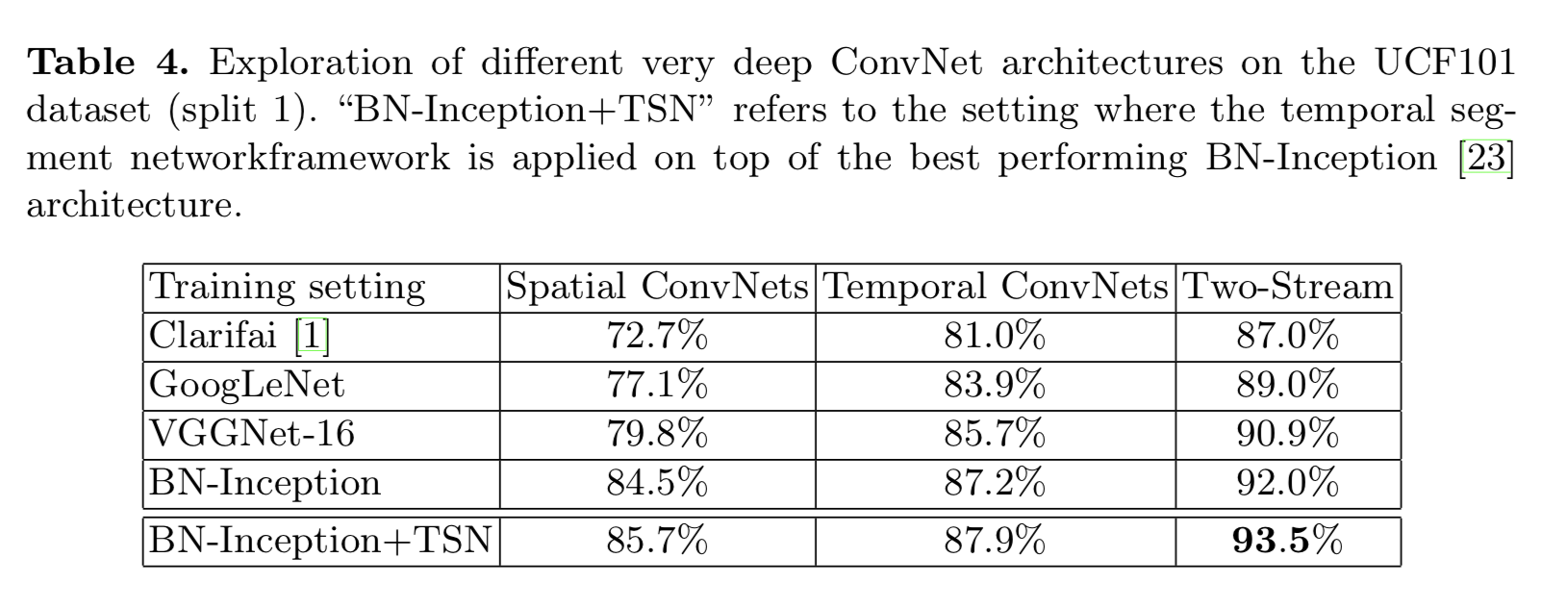
We choose the Inception with Batch Normalization
Network Inputs
Two-stream:
- RGB images for the spatial stream
- stacked optical flow fields for the temporal stream
Here:
- RGB difference
- warped optical flow fields(makes motion concentrate on the actor)

Network Training
We design several strategies for training the ConvNets as follows:
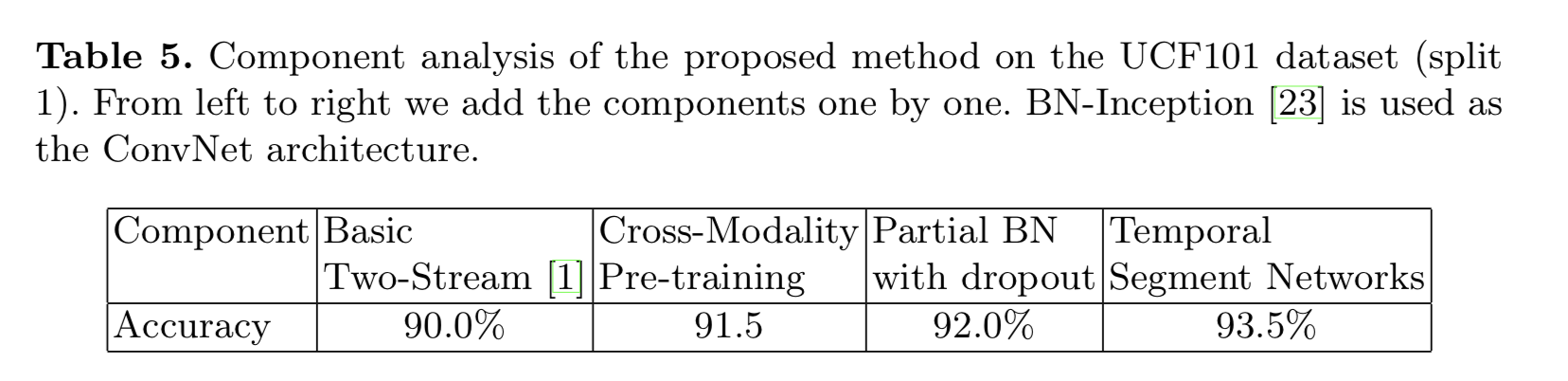
Cross Modality Pre-training
We utilize RGB models to initialize the temporal networks
Regularization Techniques
After initialization with pre-trained models, we choose to freeze the mean and variance parameters of all Batch Normalization layers except the first one
We call this strategy partial BN
We add a extra dropout layer after the global pooling layer in BN
Data Augmentation
- random cropping
- horizontal flipping
- corner cropping
- multi-scale cropping
- we fix the size of input image or optical flow fields as 256×340
- the width and height of cropped region are randomly selected from {256,224,192,168}
- Finally, these cropped regions will be resized to 224 × 224
Testing Temporal Segment Networks
We sample 25 RGB frames or optical flow stacks from the action videos
We fuse the prediction scores of 25 frames and different streams before Softmax normalization
Experiments
Datasets and Implementation Details
skip over
Exploration Study
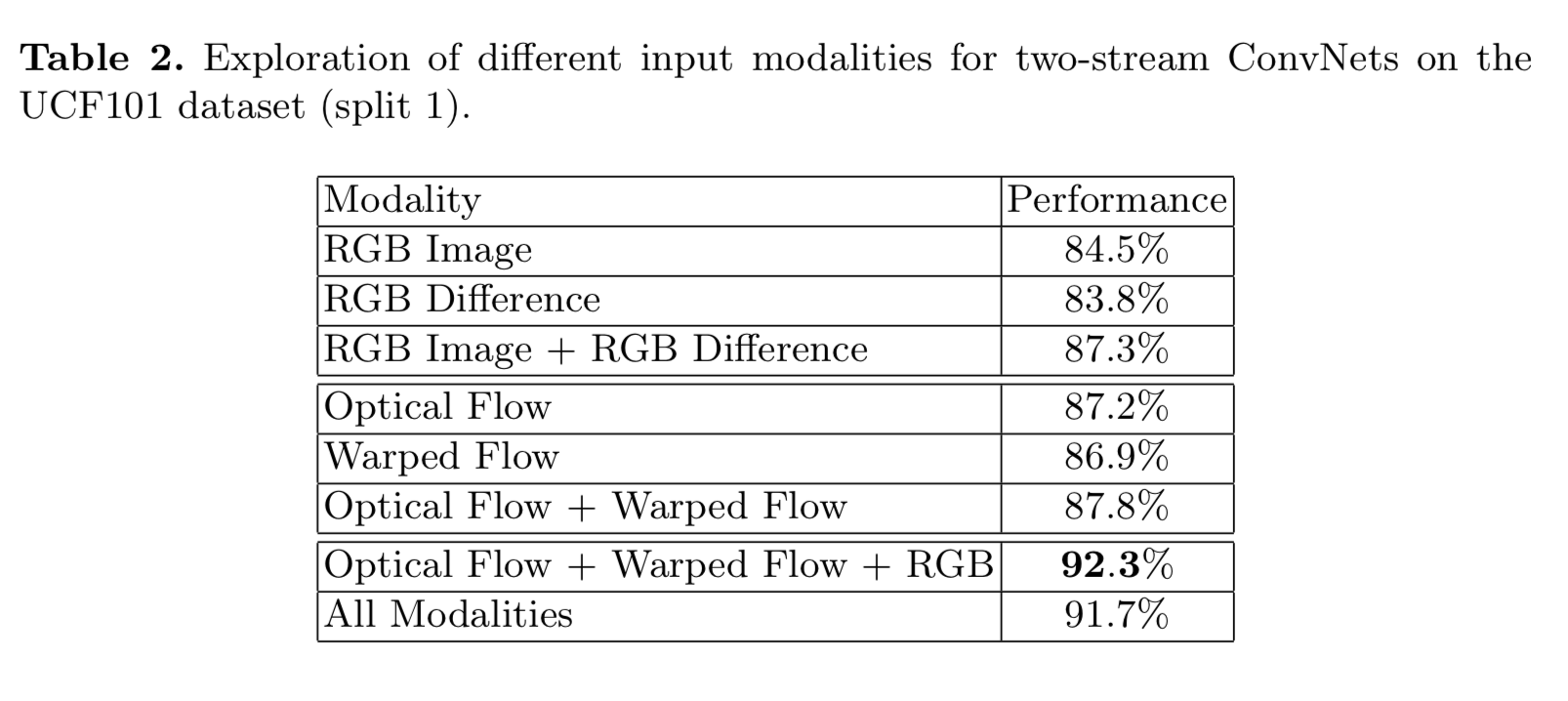
We conjecture that the optical flow is better at capturing motion information
Evaluation of Temporal Segment Networks
segmental consensus function
network architectures
component-wise analysis
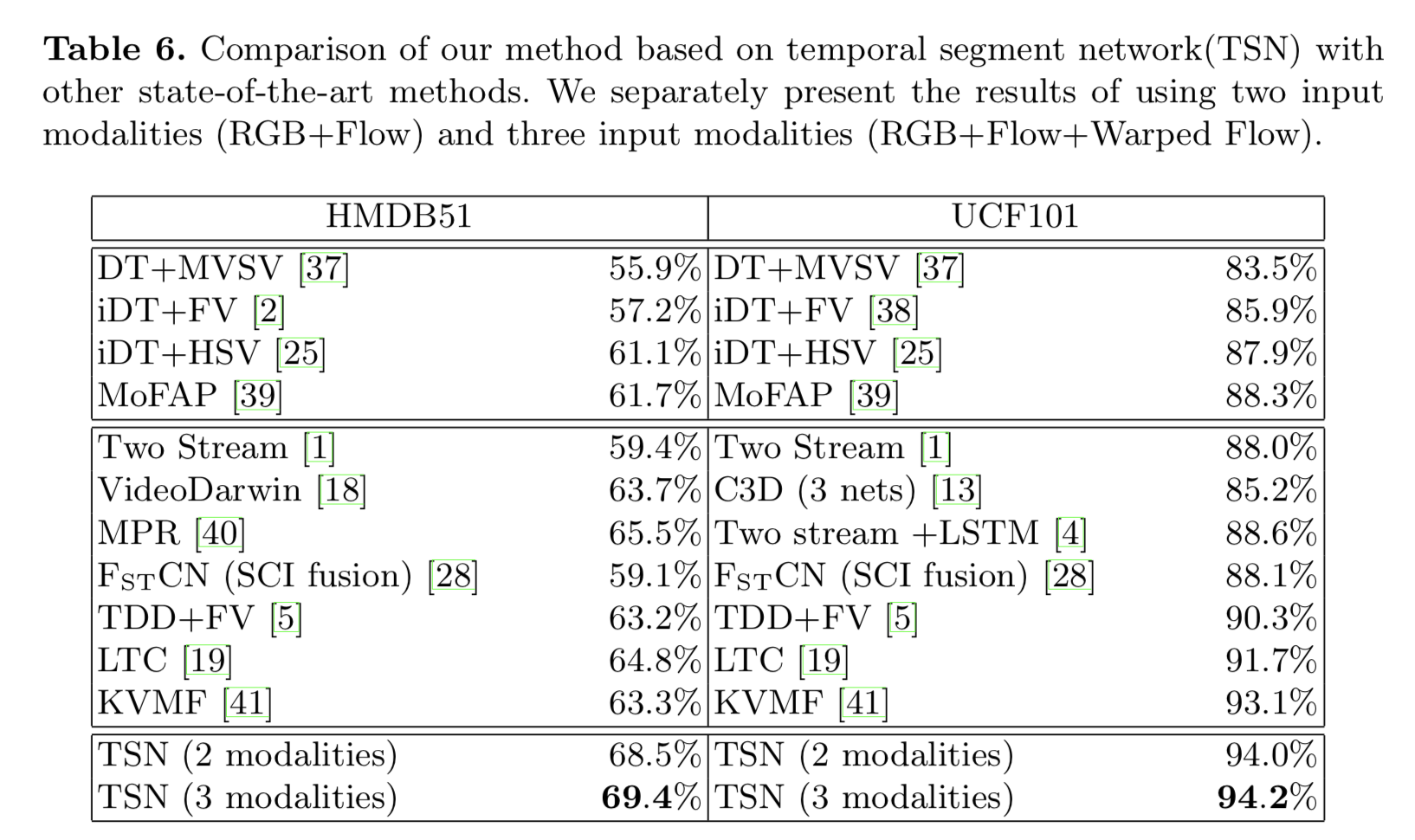
Comparison with the State of the Art
Model Visualization

Conclusions
skip over