总结
- YOLO的V3版本,基本延续了上一代的特性——快的同时保持了还不错的效果
- 主要的创新点——使用多尺度网络
- 使用多个logistic 分类器进行分类,取代softmax
- 提出了新的基础网络结构——Darknet-53
COCOs测试结果
- time: 51ms
- COCOs AP50: 57.9
Abstract
We made a bunch of little design changes to make it better
Introduction
We will tell you:
- What things work in YOLOv3
- What doesn’t
The Deal
Bounding Box Prediction
- use MSE during training
- This should be 1 if the bounding box prior overlaps a ground truth object by more than any other bounding box prior
- If the bounding box prior is not the best but does overlap a ground truth object by more than some threshold(0.5) we ignore the prediction
- only assigns one bounding box prior for each ground truth object
- If a bounding box prior is not assigned to a ground truth object it incurs no loss for coordinate or class predictions, only objectness
Class Prediction
- we simply use independent logistic classifiers instead softmax
- helpful when training on a more complex dataset(Open Images Dataset)
Predictions Across Scales
- predicts boxes at 3 different scales
- we also take a feature map from earlier in the network and merge it with our upsampled features using concatenation
Feature Extractor
We use a new network for performing feature extraction——Darknet-53
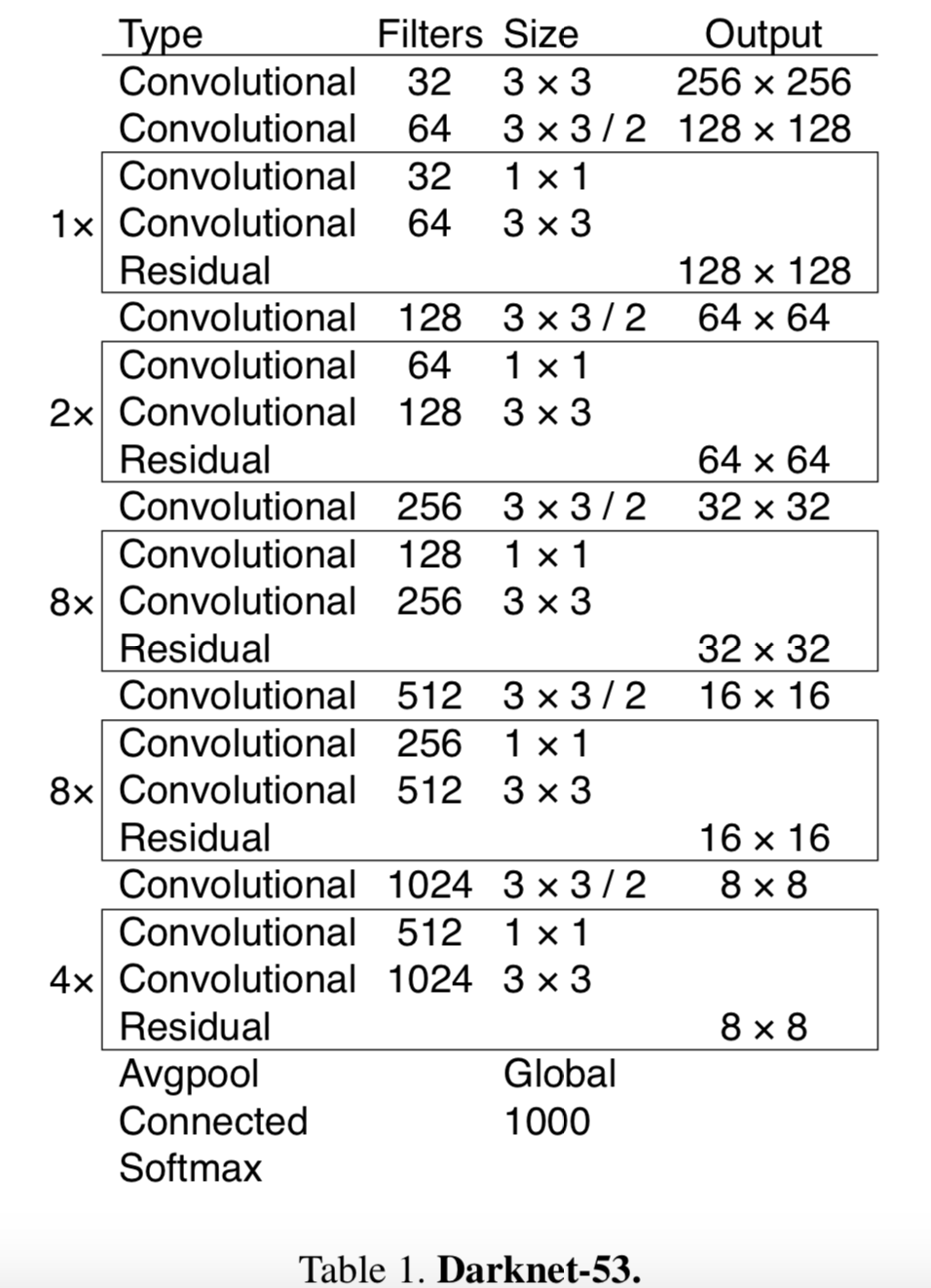
Darknet-53 has similar performance to ResNet-152 and is 2 times faster
Training
We use all the standard stuff
How We Do
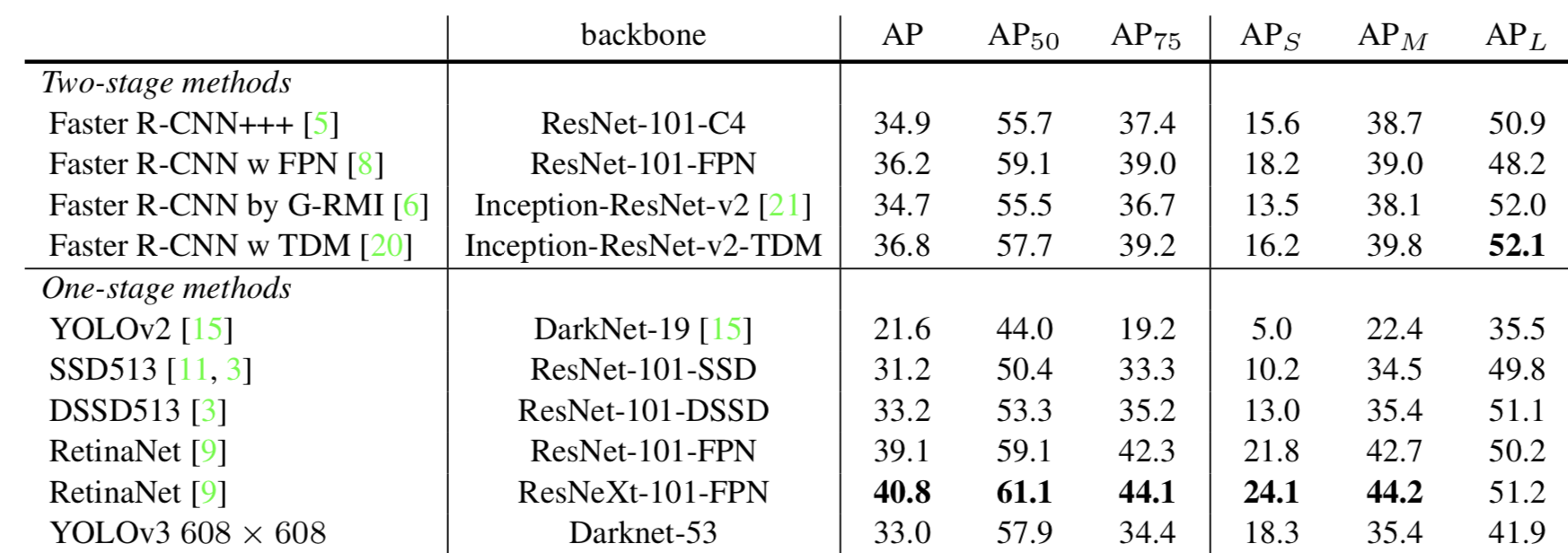
YOLOv3 is quite a bit behind RetinaNet but 3.8 times faster
YOLOv3 is a very strong detector that excels at producing decent boxes for objects, but struggles to get the boxes perfectly aligned with the object
No longer has problems with small object detection
Things We Tried That Didn’t Work
- Anchor box x, y offset prediction: this formulation decreased model stability and didn’t work very well
- Linear x, y prediction instead of logistic: a couple point drop in mAP
- Focal loss: It dropped our mAP about 2 poitns
- Dual IOU thresholds and truth assignment: couldn’t get good results
What This All Means
skip