总结
- 本文主要是受微软残差网络5的启发,提出新的结构
- 首先讨论了残差的作用
- 微软的文章5认为残差是组成“深”且“宽”的网络的关键
- 本文觉得不对,残差的效果主要体现在提高训练稳定性上
- 在v315的基础上,提出了一些改进方案,并没有说明改进的思路,只是说换了TensorFlow之后可以不做之前的妥协,所以有了v4
- 然后结合了Residual搞出了Inception-ResNet-v1(计算复杂度与v3相近)和其加强版Inception-ResNet-v2(计算复杂度与v4相近)
- 实践表明当网络filter数量超过1000的时候,训练会炸,即使调小学习率也不行,提出了减小残差传播的方法,因子在0.1~0.3左右
实验结果
ILSVRC 2012 数据集
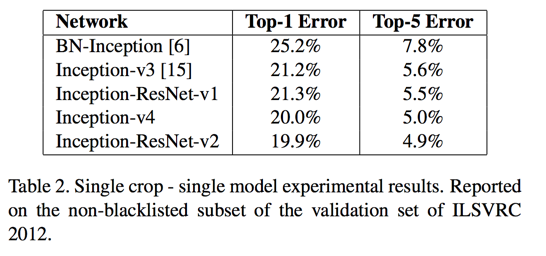
- 1 model; 1 crop; top-5 error:
- Inception-v4: 5.0%
- Inception-ResNet-v1: 5.5%
- Inception-ResNet-v2: 4.9%
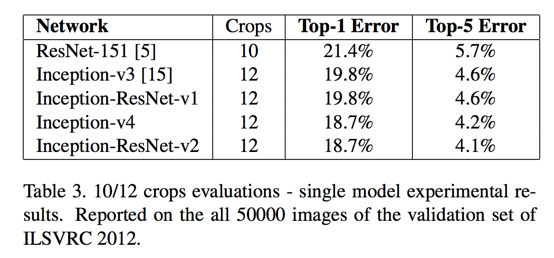
- ensemble(4 models; 144 crops); top-5 error:
- Inception-v4 + 3 * Inception-ResNet-v2: 3.1%
Abstract
Question:
whether there are any benefit in combining the Inception architecture with residual connections
Answer:
training with residual connections accelerates the training of Inception networks significantly
Introduction
In this work we study the combination of the two most recent ideas: Residual connections introduced by He et al. in 5 and the latest revised version of the Inception architecture 15
Inception-v4:
- making v3 deeper and wider —— v4
- remove the technical constrains chiefly came from the need for partitioning the model for distributed training
- migrating training setup to Tensorflow instead of DistBelief, we can simplify the architecture significantly
Inception-ResNet-v1:
- a hybrid Inception version with Inception and Resnet
- has a similar computational cost to Inception-v3
Inception-ResNet-v2:
- a costlier version with significantly improved recognition performance
Related Work
Residual connection were introduced by He et al. in 5:
- the authors argue that residual connections are inherently necessary for training very deep convolutional models
- our findings do not seem to support this view, at least for image recognition
- however residual connections seems to improve the training speed greatly
skip Inception
Architectural Choices
Pure Inception Blocks

Residual Inception Blocks
- we use cheaper Inception blocks than the original Inception
- Each Inception block is followed by filter-expansion layer (1 X 1 convolution without activation)
- “Inception-ResNet-v1” roughly the computational cost of Inception-v3
- “Inception-ResNet-v2” matches the raw cost of the newly introduced Inception-v4 network
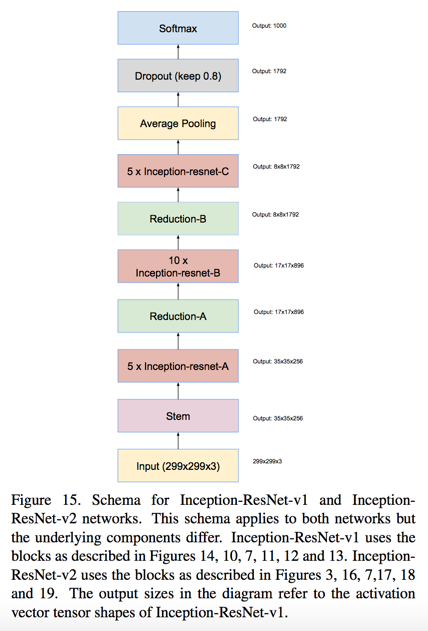
we remove the BN on the top of summations since it consumes disproportionate amount of GPU- memory
Scaling of the Residuals
- if the number of filters exceeded 1000, the residual variants started to exhibit instabilities and the network has just “died” early in the training
- we found that scaling down the residuals before adding them to the previous layer activation seemed to stabilize the training
- scaling factors between 0.1 and 0.3
- even where the scaling was not strictly necessary, it never seemed to harm the final accuracy
Training Methodology
- SGD
- Tensorflow
- RMSProp [16] with decay of 0.9 and ✏ = 1.0(better then momentum)
- learning rate 0.045 decayed every two epochs using an exponential rate of 0.94
Experimental Results
Conclusions
skip
Reference
5. K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learn- ing for image recognition. arXiv preprint arXiv:1512.03385, 2015. ↩
15. C.Szegedy,V.Vanhoucke,S.Ioffe,J.Shlens,andZ.Wojna. Rethinking the inception architecture for computer vision. arXiv preprint arXiv:1512.00567, 2015. ↩